lang: kr
slug: cogvideo
title: ‘CogVideo: 12.7K Stars — Complete Text-to-Video Setup Guide 2026’
description: ‘CogVideo (CogVideoX) is a text and image-to-video generation model from Zhipu AI. Supports ComfyUI, Diffusers, SAT, and Wan/HunyuanVideo/Open-Sora integration. Covers installation, Docker, inference, fine-tuning, and benchmarks.’
tags: [“ai-tools”, “guide”, “open-source”, “reference”, “tutorial”, “video-generation”]
date: 2026-05-19 00:00:00+08:00
lastmod: 2026-05-19 00:00:00+08:00
tech_stack: []
application_domain: Ai Tools
source_version: ’'
licensing_model: Open Source
license_type: Apache-2.0
file_size: ’'
file_md5: ’'
download_url: ’'
backup_url: ’'
github_repo: ‘https://github.com/zai-org/CogVideo'
last_maintained: ‘2026-05-19’
draft: false
categories: [‘ai-tools’]
aliases:
/posts/cogvideo/
faqs:
q: ‘What GPU do I need to run CogVideoX locally?’
a: ‘CogVideoX-2B runs on 5GB VRAM with Diffusers plus sequential CPU offload, while CogVideoX-5B needs 10GB minimum. CogVideoX1.5-5B-I2V works on just 4GB, and 16GB+ VRAM (RTX 4080/4090 or A100) gives a comfortable experience without CPU offloading.’
q: ‘What is the difference between CogVideoX-5B and CogVideoX1.5-5B?’
a: ‘CogVideoX1.5-5B is the November 2024 update with higher resolution (1360x768 vs 720x480), longer videos (up to 10 seconds vs 6 seconds), and improved frame handling (16N+1 vs 8N+1 frame formula). The 1.5 series also adds dedicated I2V models with better motion coherence from static images.’
q: ‘How long does CogVideoX-5B take to generate a video?’
a: ‘On a single A100 80GB at 50 steps, CogVideoX-5B takes about 1000 seconds for a 5-second video, making it slower than Wan 2.1 or HunyuanVideo on equivalent hardware. Video-BLADE step distillation offers up to 8.89x speedup but requires separate model conversion.’
q: ‘Can I fine-tune CogVideoX on my own dataset?’
a: ‘Yes, via two paths: the SAT framework supports full-parameter fine-tuning and LoRA, while Diffusers supports LoRA through train_cogvideox_lora.py. The 5B models require A100 GPUs, 2B models can train on a single RTX 4090 with gradient checkpointing, and you need 25+ videos for meaningful style or concept learning.’
q: ‘Does CogVideoX support languages other than English for prompts?’
a: ‘No, CogVideoX is trained primarily on English captions, so multilingual prompts degrade in quality compared to Wan 2.1 or HunyuanVideo, which handle Chinese natively. The model also expects long, detailed prompts of 200+ words for best results, so prompt optimization via LLM expansion is recommended.’
2024~2025년에는 텍스트-비디오 생성이 연구 호기심에서 제작 도구로 전환되었습니다. 오픈 소스 모델은 이제 소비자 GPU에서 실행되는 동안 품질 면에서 상용 API와 경쟁합니다. 문제: 대부분의 리포지토리는 분산된 문서와 함께 기본 모델 가중치로 제공됩니다. 비디오를 생성하는 대신 추론 스크립트, VRAM 최적화 플래그 및 미세 조정 파이프라인을 연결하는 데 몇 시간을 소비합니다.
Zhipu AI의 CogVideo는 이 문제를 다르게 해결합니다. 12.7K GitHub 스타, 36개 콘Tributor 및 활성 릴리스를 통해 사전 학습된 2B 및 5B 매개변수 모델, Diffusers 파이프라인 통합, SAT 기반 미세 조정, ComfyUI 노드, 비디오를 효율적인 잠재 표현으로 압축하는 3D 인과 VAE 등 완전한 툴킷을 제공합니다. 이 CogVideo 튜토리얼은 2026년 개발자를 위한 가장 완벽한 CogVideo 설정 가이드인 양자화된 추론 및 LoRA 미세 조정을 통해 pip 설치부터 프로덕션 배포까지 모든 것을 다룹니다.
CogVideo는 Zhipu AI가 개발한 오픈 소스 텍스트-비디오 AI 생성 프레임워크로, 3D 인과 VAE 및 전문 변환기 아키텍처를 기반으로 구축되었습니다. CogVideoX 시리즈(2024)는 ICLR 2023에서 발표된 원래 CogVideo 모델을 계승하여 텍스트 파티에서 6초 720p 비디오를 생성하는 5B 매개변수 모델을 제공합니다.pts 또는 정지 이미지.
CogVideo는 Zhipu AI가 개발한 오픈 소스 텍스트-비디오 및 이미지-비디오 생성 프레임워크로, 3D 인과 VAE 및 전문 변환기 아키텍처를 기반으로 구축되었습니다. CogVideoX 시리즈(2024)는 ICLR 2023에서 발표된 원래 CogVideo 모델을 계승하여 텍스트 프롬프트 또는 정지 이미지에서 6초 720p 비디오를 생성하는 5B 매개변수 모델을 제공합니다.
``배쉬
python3.11 -m venv cogvideo_env
소스 cogvideo_env/bin/activate
2단계 - 저장소를 복제하고 종속 항목을 설치합니다.
``배쉬
자식 클론 https://github.com/zai-org/CogVideo.git
CD Cog비디오
pip 설치 -r requirements.txt
requirements.txt는 PyTorch, Diffusers, Transformers, Accelerate 및 SAT 툴킷을 설치합니다.
토치>=2.3.0
디퓨저>=0.30.0
변압기>=4.40.0
가속>=0.30.0
문장
opencv-python
3단계 - 설치 확인:
``파이썬
수입 토치
디퓨저에서 CogVideoXPipeline 가져오기
print(f"PyTorch 버전: {torch.version}")
print(f"CUDA 사용 가능: {torch.cuda.is_available()}")
print(f"CUDA 버전: {torch.version.cuda}")
예상 출력:
파이토치 버전: 2.5.1+cu121
CUDA 사용 가능: True
CUDA 버전: 12.1
### 방법 2: Docker 배포(프로덕션)
재현 가능한 배포 및 다중 GPU 추론을 위해서는 **CogVideo Docker** 컨테이너를 사용하세요. 이 **cogvideo docker** 접근 방식은 개발과 프로덕션 전반에 걸쳐 동일한 환경을 보장합니다.
``도커파일
nvidia/cuda에서:12.1.0-devel-ubuntu22.04
실행 apt-get 업데이트 && apt-get install -y \
python3.11 python3-pip git wget \
&& rm -rf /var/lib/apt/lists/*
실행 pip3 설치 --no-cache-dir 토치 torchvision --index-url \
https://download.pytorch.org/whl/cu121
WORKDIR /앱
git clone https://github.com/zai-org/CogVideo.git을 실행하세요.
실행 pip3 설치 -r 요구사항.txt
ENV 파이썬 버퍼링=1
노출 7860
CMD ["python3", "-m", "inference.cli_demo"]
빌드 및 실행:
``배쉬
docker build -t cogvideo:latest .
docker run –gpus all -it –rm
-v $(pwd)/output:/app/output
-v $(pwd)/models:/app/models
cogvideo:최신
–prompt “일출의 고요한 산 호수” --model_path THUDM/CogVideoX-5B
다중 GPU 추론의 경우 `from_pretrained()`에 `device_map="balanced"`를 추가하고 `enable_model_cpu_offload()`를 제거하세요.
``파이썬
파이프 = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5B",
torch_dtype=torch.bfloat16,
device_map="균형"
)
ComfyUI를 다시 시작하고 CogVideoX 워크플로를 로드합니다. 래퍼는 I2V 및 비디오-비디오를 포함한 모든 모델 변형을 지원합니다.
### SAT 프레임워크 미세 조정
맞춤형 스타일과 개념을 위해 SAT를 사용하여 LoRA로 세부 조정하세요.
`sat/configs/sft.yaml`을 구성합니다.
``yaml
model_parallel_size: 1
Experiment_name: lora-맞춤 스타일
모드: 미세 조정
로드: "{your_CogVideoX-2b-sat_path}/transformer"
train_iters: 1000
평가 간격: 100
저장 간격: 100
저장:ckpts
train_data: ["your_train_data_경로"]
valid_data: ["your_val_data_path"]
깊은 씨앗:
bf16:
활성화됨: False # 5B의 경우 True
fp16:
활성화됨: 5B의 경우 True # False
단일 GPU에서 미세 조정 실행:
``배쉬
CD CogVideo/토
배쉬 Finetune_single_gpu.sh
SAT LoRA 가중치를 Hugging Face 형식으로 변환:
``배쉬
파이썬 도구/export_sat_lora_weight.py \
--sat_pt_path ckpts/lora-custom-style/1000/mp_rank_00_model_states.pt \
--lora_save_directory ./hf_lora_weights/
CogVideoX는 길고 설명적인 프롬프트에 대해 훈련되었습니다. 짧은 프롬프트는 낮은 품질의 비디오를 생성합니다. 프롬프트 변환 스크립트를 사용하십시오.
``배쉬
파이썬 추론/convert_demo.py
–“자전거를 타는 소녀” 프롬프트
–“t2v"를 입력하세요
스크립트는 큰 언어를 호출합니다.ge 모델(GLM-4 Plus 또는 GPT-4o)을 사용하면 간단한 프롬프트를 자세한 설명으로 확장할 수 있습니다. 변환 예시:
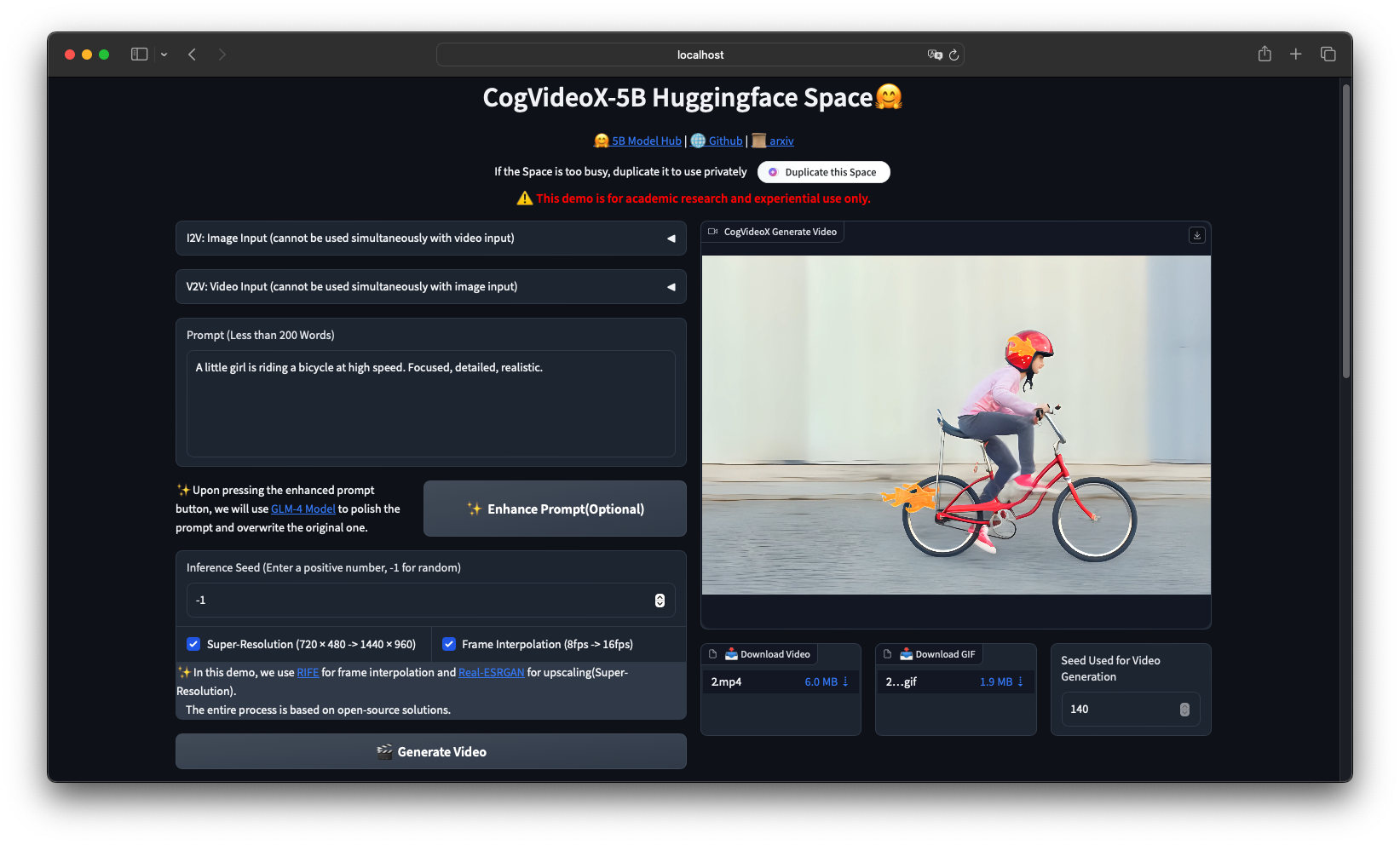
**입력:** `"자전거를 타는 소녀"`
**결과:** `"흐르는 적갈색 머리를 가진 젊은 여성이 빈티지 빨간색 자전거를 타고 조약돌 길을 따라갑니다. 그녀는 가벼운 여름 드레스를 입고 미풍에 부드럽게 휘날립니다. 길은 땅에 긴 그림자를 드리우는 키 큰 참나무가 있는 햇살 가득한 숲을 통과합니다. 황금빛 오후의 빛이 나뭇잎 사이로 스며들어 따뜻하고 향수를 불러일으키는 분위기를 연출합니다.여기. 그녀는 여유로운 속도로 페달을 밟으며 얼굴에 고요한 미소를 띠고 가끔 길 가장자리를 따라 자라는 야생화를 바라보기도 합니다."
프로그래밍 방식으로 사용하려면:
``파이썬
inference.convert_demo import Convert_prompt에서
최적화_프롬프트 = 변환_프롬프트(
"장난감 쥐를 가지고 노는 고양이",
재시도 횟수=3,
유형="t2v"
)
인쇄(최적화_프롬프트)
Content Creation Studios: 도쿄 기반 애니mation studio는 CogVideoX-5B-I2V를 사용하여 컨셉 아트를 애니메이션화하고 스토리보드 제작 시간을 60% 단축했습니다. 이미지-비디오 파이프라인은 정적 일러스트레이션을 6초 모션 미리보기로 전환합니다.
전자상거래 제품 데모: 한 가구 소매업체는 CogVideoX1.5-5B-I2V를 사용하여 단일 제품 사진에서 제품 쇼케이스 비디오를 생성했습니다. 이 모델은 1360 x 768 해상도에서 부드러운 카메라 궤도와 자연스러운 조명 전환을 생성합니다.
교육 콘텐츠: MOOC 플랫폼이 자동으로 데모를 생성합니다 v텍스트 설명에서 얻은 물리학 실험 아이디어. CogVideoX-5B 모델의 강력한 텍스트 추적 기능은 설명된 물리적 프로세스를 정확하게 묘사합니다.
소셜 미디어 마케팅: 마케팅 팀은 프롬프트에 최적화된 배치 생성을 사용하여 A/B 테스트를 위해 매일 50개 이상의 짧은 비디오 변형을 생성하고 16GB VRAM이 장착된 공유 GPU 서버에서 양자화된 추론을 실행합니다.
### VRAM 최적화 체크리스트
GPU에 따라 다음 최적화를 순서대로 적용합니다.
1. **VAE 슬라이싱**: 항상 활성화 - 무시할 수 있는 오버헤드로 대규모 배치를 분할합니다.
2. **VAE 타일링**: 720p 이상의 해상도에 대해 활성화 - 패치로 프로세스
3. **순차적 CPU 오프로드**: < 12GB VRAM과 함께 사용 - 단계 간에 레이어를 CPU로 이동합니다.
4. **모델 CPU오프로드**: 12~16GB VRAM과 함께 사용 — 순차보다 빠르지만 더 많은 메모리를 사용합니다.
5. **INT8 양자화**: 7~10GB VRAM 대상에 TorchAO 사용
6. **FP32를 통한 BF16**: Ampere+ GPU에서는 항상 BF16을 사용합니다. FP32에 비해 메모리가 절반으로 줄어듭니다.
### Prometheus를 사용한 모니터링
프로덕션에서 추론 지표를 추적합니다.
``파이썬
prometheus_client import Counter, Histogram, start_http_server에서
수입 시간
INFERENCE_COUNT = Counter('cogvideo_inferences_total', '총 추론')
INFERENCE_TIME = 히스토그램('cogvideo_inference_seconds', '추론 대기 시간')
VRAM_USAGE = 히스토그램('cogvideo_vram_bytes', '최대 VRAM 사용량')
start_http_server(9090)
@INFERENCE_TIME.시간()
def generate_tracked(파이프, 프롬프트):
INFERENCE_COUNT.inc()
torch.cuda.reset_peak_memory_stats()
결과 = 파이프(프롬프트=프롬프트, num_frames=49).프레임[0]
vram = torch.cuda.max_memory_allocation()
VRAM_USAGE.observe(vram)
결과 반환
CogVideoX를 선택해야 하는 경우: 정확한 텍스트 추적, 긴 형식 생성(최대 10초), 전용 I2V 모델을 사용한 이미지-비디오 또는 고품질 모델 중에서 가장 낮은 VRAM 설치 공간이 필요할 때 선택하세요. CogVideoX1.5-5B-I2V는 4GB GPU에서 실행됩니다. cogvideo 대 wan 비교에서 CogVideoX는 VRAM 효율성과 전용 I2V 지원에서 승리하는 반면 Wan 2.1은 모션 유동성에서 앞서고 있습니다.
Wan 2.1을 선택하는 경우: 다국어 중국어/영어 워크플로에 더 적합하며 1개가 있는 경우14B 모델의 경우 6GB+ VRAM. Wan 2.1은 벤치마크에서 뛰어난 모션 품질을 보여주고 동등한 하드웨어에서 더 빠른 추론을 보여줍니다.
HunyuanVideo를 선택하는 경우: VBench-2.0에서 전반적으로 최고의 품질, 가장 강력한 인간 충실도를 제공하지만 완전 정밀도 추론을 위해서는 24GB 이상의 VRAM이 필요합니다. GPU 메모리가 무제한인 경우 기본 선택입니다.
Open-Sora를 선택하는 경우: 연구 유연성과 매우 긴 비디오 생성(최대 16초)이 필요하지만 시각적 품질은 낮습니다.
느린 추론: 50단계의 CogVideoX-5B를 사용하는 A100에서 단일 5초 비디오는 최대 1000초가 걸립니다. Wan 2.1 및 HunyuanVideo는 동등한 하드웨어에서 더 빠릅니다. 다가오는 BLADE 가속화(8.89x 속도 향상)는 도움이 되지만 별도의 모델 변환이 필요합니다.
영어 전용 프롬프트: CogVideoX는 주로 영어 캡션에 대해 교육을 받았습니다. Chin을 처리하는 Wan 2.1 또는 HunyuanVideo에 비해 다국어 프롬프트 성능이 저하됩니다.원래 그렇죠.
인간 형상 품질: VBench-2.0 인간 충실도 점수는 HunyuanVideo(0.871 대 0.964)보다 뒤떨어집니다. 인간의 얼굴과 몸의 움직임은 때때로 인공물을 보여줍니다.
최대 10초: CogVideoX1.5-5B도 최대 10초(161프레임)입니다. 더 긴 콘텐츠를 위해서는 영상 확장 기술이 필요하거나 Open-Sora로 전환해야 합니다.
프롬프트 엔지니어링 필요: 모델은 길고 자세한 프롬프트(200단어 이상)를 기대합니다. LLM 확장을 통한 즉각적인 최적화가 없으면 출력 품질 d크게 떨어졌습니다.
상업용 비디오 API 없음: Runway 또는 Kling과 달리 CogVideoX는 자체 호스팅만 가능합니다. GPU 인프라, 확장, 큐잉을 관리합니다.
A: CogVideoX-2B는 디퓨저 + 순차 CPU 오프로드를 갖춘 5GB VRAM에서 실행됩니다. CogVideoX-5B에는 최소 10GB가 필요합니다. CogVideoX1.5-5B-I2V는 4GB에서만 작동합니다. CPU 오프로딩 없이 편안한 경험을 위해서는 16GB+ VRAM(RTX 4080/4090 또는 A100)을 목표로 하세요.
질문: H이제 50단계 이상으로 추론 속도를 높일 수 있나요?
A: timestep_spacing="trailing"과 함께 CogVideoXDPMScheduler를 사용하고 초안 미리보기의 단계를 25-30으로 줄이세요. 생산 속도를 높이려면 비슷한 품질로 CogVideoX-5B에서 8.89배 가속을 달성하는 Video-BLADE 단계 증류를 적용하세요. VAE 타일링 및 슬라이싱을 활성화하고 VRAM이 허용하는 경우 순차적 오프로드 대신 ’enable_model_cpu_offload()‘를 사용하세요.
Q: 내 데이터세트에서 CogVideoX를 미세 조정할 수 있나요?
A: 예, 두 가지 경로를 통해 가능합니다. SAT 프레임워크전체 매개변수 미세 조정 및 맞춤형 데이터 세트를 통한 LoRA를 지원합니다. 디퓨저는 train_cogvideox_lora.py를 통해 LoRA 미세 조정을 지원합니다. 둘 다 5B 모델에는 A100 GPU가 필요합니다. 2B 모델은 그라데이션 체크포인트를 사용하여 단일 RTX 4090에서 훈련할 수 있습니다. 의미 있는 스타일이나 개념 학습을 위해서는 25개 이상의 동영상이 필요합니다.
Q: CogVideoX-5B와 CogVideoX1.5-5B의 차이점은 무엇입니까?
A: CogVideoX1.5-5B는 더 높은 해상도(1360 x 768 vs 720 x 480), 더 긴 비디오를 지원하는 2024년 11월 업데이트입니다.생성(최대 10초 대 6초) 및 향상된 프레임 처리(16N+1 프레임 공식 대 8N+1). 1.5 시리즈에는 정적 이미지의 모션 일관성이 향상된 전용 I2V 모델도 도입되었습니다.
Q: CogVideoX는 Sora 또는 Kling과 같은 상용 API와 어떻게 비교됩니까?
A: 상용 API는 특히 인간 대상에 대해 더 간단한 액세스와 더 높은 최고 품질을 제공합니다. CogVideoX는 비용(비디오당 요금 없음), 개인 정보 보호(로컬 추론), 사용자 정의(LoRA 미세 조정) 및 재현성 측면에서 승리합니다.(고정 씨앗). 대규모 일괄 콘텐츠 생성의 경우 자체 호스팅 CogVideoX는 일반적으로 API 청구보다 10배 저렴합니다.
Q: CogVideoX는 어떤 파일 형식을 출력합니까?
A: Diffusers 파이프라인은 PyTorch 텐서를 출력합니다. 모델에 따라 diffusers.utils에서 export_to_video()를 사용하여 8-16FPS에서 H.264 인코딩을 사용하여 MP4로 저장합니다. 다른 형식의 경우 FFmpeg를 사용하여 MP4를 변환하세요.
**Q: 기술적인 지식이 없는 사용자를 위한 웹 UI가 있나요?여러분?**
A: 네, 다양한 옵션이 있습니다. 공식 Hugging Face Space는 설정 없이 온라인 추론을 제공합니다. 로컬에서 사용하려면 시각적 워크플로 인터페이스를 위해 CogVideoXWrapper 노드와 함께 ComfyUI를 설치하세요. Pinokio와 같은 타사 도구도 원클릭 설치를 제공합니다.
---
## 결론
CogVideoX는 오픈 소스 배포의 유연성을 통해 프로덕션 수준의 텍스트-비디오 생성을 제공합니다. 4GB VRAM 소비자 GPU부터 다중 A100 서버 클러스터까지, 모델은 하드웨어 계층 전반에 걸쳐 확장됩니다.양자화, CPU 오프로딩 및 SAT 프레임워크 미세 조정 덕분입니다.
**오늘 시작해야 할 작업 항목:**
1. 저장소를 복제하십시오: `git clone https://github.com/zai-org/CogVideo.git`
2. 종속성 설치: `pip install -r 요구 사항.txt`
3. 1세대 실행: `python inference/cli_demo.py --prompt "여기에 프롬프트" --model_path THUDM/CogVideoX-5B`
4. 더 나은 품질을 위해 `convert_demo.py`로 프롬프트 최적화
5. [Discord](https://github.com/zai-org/)에서 CogVideo 커뮤니티에 가입하세요.지원 및 작업 흐름 공유를 위한 CogVideo#-join-our-community)
프로덕션 배포의 경우 Docker 설정으로 시작하고 FastAPI 래핑을 추가하고 Prometheus로 모니터링하세요. 맞춤형 스타일이 필요할 때 SAT LoRA로 세부 조정하세요.
**매일 AI 소스 코드 업데이트를 받으려면 텔레그램 그룹에 가입하세요.** [@dibi8source](https://t.me/dibi8source)
---
## 권장 호스팅 및 인프라
위의 도구를 프로덕션에 배포하기 전에 견고한 인프라가 필요합니다. dibi8이 실제로 사용하는 두 가지 옵션s 및 권장 사항:
- **DigitalOcean
** — 14개 이상의 전 세계 지역에서 60일 동안 $200 무료 크레딧을 제공합니다. 오픈 소스 AI 도구를 실행하는 인디 개발자를 위한 기본 옵션입니다.
- **HTStack
** — 중국 본토에서 지연 시간이 짧은 홍콩 VPS입니다. 이는 dibi8.com을 호스팅하는 동일한 IDC이며 프로덕션 환경에서 전투 테스트를 거쳤습니다.
*제휴 링크 — 추가 비용이 들지 않으며 dibi8.com을 계속 운영하는 데 도움이 됩니다.*
## 소스 &추가 자료
- CogVideo GitHub 리포지토리: https://github.com/zai-org/CogVideo
- CogVideoX-5B 모델 카드(껴안는 얼굴): https://huggingface.co/THUDM/CogVideoX-5B
- CogVideoX1.5-5B 모델 카드: https://huggingface.co/THUDM/CogVideoX1.5-5B
- CogVideoX 논문(arXiv): https://arxiv.org/abs/2408.06072
- 디퓨저 문서: https://huggingface.co/docs/diffusers/main/en/api/pipelines/cogvideox
- 동영상-BLADE 가속 논문: https://arxiv.org/abs/2508.10774
- VBench-2.0 벤치마크 문서: https://arxiv.org/abs/2503.21755
- CogKit 미세 조정 프레임워크: https://github.com/zai-org/CogKit
- ComfyUI-CogVideoXWrapper: https://github.com/kijai/ComfyUI-CogVideoXWrapper
- 디퓨저-토르차오 정량화: https://github.com/sayakpaul/diffusers-torchao
- Wan 2.1 저장소: https://github.com/Wan-Video/Wan2.1
- HunyuanVideo 저장소: https://github.com/Tencent/HunyuanVideo
- 오픈소라 저장소: https://github.com/hpcaitech/Open-Sora
<!--자동 참조-->
## 참고자료 및 출처
- [코그비드eo](https://github.com/zai-org/CogVideo)
- [ComfyUI-CogVideoXWrapper](https://github.com/kijai/ComfyUI-CogVideoXWrapper)
- [CogKit](https://github.com/zai-org/CogKit)
- [디퓨저-torchao](https://github.com/sayakpaul/diffusers-torchao)
- [완 2.1](https://github.com/Wan-Video/Wan2.1)
- [HunyuanVideo](https://github.com/Tencent/HunyuanVideo)
- [오픈소라](https://github.com/hpcaitech/Open-Sora)
- [허깅 페이스 디퓨저(CogVideoX 문서)](https://huggingface.co/docs/diffusers/main/en/api/pipelines/cogvideox)

💬 댓글 토론