exo: 내 기기들을 묶어 프런티어 AI를 로컬에서 (45K Stars) — 2026 실전 가이드
exo는 여러분의 Mac, PC, 심지어 휴대폰까지 하나의 클러스터로 묶어 프런티어 AI 모델을 로컬에서 실행합니다. GitHub 스타 45,088개, Apache-2.0 라이선스. 설치, 대시보드, OpenAI/Claude/Ollama 호환 API, 실제 명령어, 그리고 솔직한 비교까지 다룹니다.
- ⭐ 45088
- Apache-2.0
- 업데이트 2026-06-02
들어가며 #
프런티어 모델은 덩치가 큽니다. 671B 파라미터 모델은 노트북 한 대에 도저히 들어가지 않고, 직접 돌리겠다고 클라우드 GPU를 충분히 빌리면 비용이 금방 불어납니다. exo는 다른 길을 택합니다. 이미 가지고 있는 기기들—Mac, 리눅스 머신, 심지어 휴대폰까지—을 하나의 클러스터로 엮은 뒤, 모델을 그 위에 나눠 올려 함께 추론을 돌립니다. GitHub 스타 45,000개를 넘기며, 「내가 통제하는 하드웨어에서 큰 모델을 돌린다」는 분야에서 가장 주목받는 프로젝트 중 하나가 되었습니다. 이 가이드에서는 exo를 설치하고, 대시보드를 열고, OpenAI·Claude·Ollama 호환 API로 exo와 대화하는 과정을 차근차근 살펴봅니다.
exo란 무엇인가? #
exo는 여러 기기를 하나의 분산 클러스터로 묶어 프런티어 AI 모델을 로컬에서 실행하는 오픈소스 도구입니다. 한 대의 머신에 모델 전체를 욱여넣는 대신, exo는 네트워크에서 발견한 모든 노드에 모델의 레이어를 나눠 배치합니다. 덕분에 어느 한 기기에는 너무 큰 모델이라도 실행할 수 있습니다.
이 프로젝트는 exo-explore(exo labs) 팀이 유지보수하며 Apache-2.0 라이선스로 배포되므로, 자유롭게 사용·검토·수정할 수 있습니다.
exo의 작동 원리 #
exo가 내부에서 하는 일은 다음과 같습니다.
- 로컬 실행: 모델이 여러분의 기기에서 돌아가므로, 프롬프트와 데이터가 네트워크 밖으로 나가지 않고 토큰 단위 클라우드 비용도 피할 수 있습니다.
- 자동 클러스터링: exo는 같은 네트워크에서 exo를 실행 중인 다른 기기를 스스로 찾아냅니다. 노드를 나열한 설정 파일도, 손수 작성하는 「마스터/워커」 설정도 필요 없습니다.
- 토폴로지 인지 분할: exo는 각 노드의 자원과 지연 시간을 실시간으로 측정해, 모델의 레이어를 어떻게 나눠 배치할지 결정합니다. 그래서 어느 한 머신에는 너무 큰 모델도 클러스터 위에서 돌릴 수 있습니다.
결과적으로 네트워크에 Mac이나 PC를 한 대 더 추가하면 클러스터가 쓸 수 있는 메모리와 연산이 그만큼 늘어나며, 설정을 다시 작성할 필요가 전혀 없습니다.
설치 및 설정 #
exo를 하루 종일 접근 가능하게 두고 싶다면(예: 사내 공용 엔드포인트), 늘 켜져 있는 머신이 필요합니다. DigitalOcean에서 한 대 띄우거나(신규 계정 무료 체험 크레딧 제공), dibi8.com을 호스팅하는 바로 그 IDC인 HTStack의 저지연 홍콩 VPS를 쓰면 됩니다. GPU 가속 추론과 관련해 유의할 점: exo는 현재 Apple Silicon에서 GPU 가속을 지원하며, 리눅스는 당분간 CPU 전용으로 GPU 지원은 개발 중입니다.
macOS 앱 (가장 쉬움) #
Mac에서 가장 간편한 방법은 미리 빌드된 앱입니다. Homebrew로 설치하세요.
brew install --cask exo
또는 https://assets.exolabs.net/EXO-latest.dmg에서 최신 DMG를 직접 내려받으세요. 이 앱은 비교적 최신 버전의 macOS가 필요합니다.
소스에서 빌드 (macOS 또는 Linux) #
최신 코드를 돌리려면 저장소를 클론한 뒤 uv로 실행합니다. 먼저 uv, Node 18+, nightly 버전의 Rust 툴체인이 필요합니다(macOS에서는 Xcode, Homebrew, macmon도 필요).
git clone https://github.com/exo-explore/exo
cd exo/dashboard && npm install && npm run build && cd ..
uv run exo
Nix를 사용한다면 사전 요구사항을 통째로 건너뛸 수 있습니다.
nix run .#exo
흔한 오류와 해결 #
첫 실행에서 자주 겪는 문제 중 하나는, 프런트엔드를 빌드한 적이 없어 대시보드가 뜨지 않는 경우입니다. 웹 UI는 dashboard/ 디렉터리에서 컴파일되므로, 저장소를 클론한 뒤 빌드 없이 uv run exo를 실행했다면 먼저 대시보드를 다시 빌드하고 나서 실행하세요.
cd dashboard && npm install && npm run build && cd ..
uv run exo
설치 중 다른 문제가 생기면 저장소의 공식 README를 확인하세요.
- Image:
- Source: exo-explore/exo GitHub
핵심 사용법 #
exo를 설치하고 나면 작업 흐름이 시원할 만큼 짧습니다. 각 기기에서 실행하고, 대시보드를 열고, API로 요청을 보내면 끝입니다.
노드 시작하기 #
클러스터에 넣고 싶은 모든 기기에서 exo를 실행하세요.
uv run exo
각 노드는 같은 네트워크에서 다른 노드를 자동으로 찾아냅니다—수동으로 등록할 게 없습니다. 유용한 플래그가 몇 개 있습니다.
--no-worker: 추론은 직접 수행하지 않는 코디네이터 전용 노드로 실행합니다.--legacy-daemon: exo를 백그라운드 데몬으로 실행합니다.
클러스터 모니터링 #
exo는 52415 포트에서 대시보드를 제공합니다. 브라우저로 여세요.
http://localhost:52415
exo가 발견한 모든 기기, 현재 모델이 그 위에 어떻게 분할되어 있는지, 그리고 실시간 처리량과 메모리 사용량을 볼 수 있습니다.
모델 호출하기 #
exo는 OpenAI, Claude(Anthropic Messages), Ollama 형식과 호환되는 HTTP API를 제공하므로, 기존 클라이언트 코드를 대부분 그대로 쓸 수 있습니다. 스트리밍 채팅 요청은 다음과 같습니다.
curl -X POST http://localhost:52415/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{"model": "model-id", "messages": [{"role": "user", "content": "prompt"}], "stream": true}'
같은 엔드포인트가 /v1/messages의 Claude Messages API와 /ollama/api/chat의 Ollama API도 이해합니다.
정리 #
전체 흐름은 이렇습니다. 각 기기에서 노드를 띄우고, 대시보드에서 클러스터가 모이는 모습을 지켜본 뒤, 아무 OpenAI/Claude/Ollama 클라이언트나 그쪽을 가리키게 하면 됩니다. 이 API가 도구들이 이미 쓰는 형식 그대로이기 때문에, 호스팅 엔드포인트를 자신의 exo 클러스터로 바꾸는 일은 흔히 한 줄 수정으로 끝납니다.
통합 #
exo가 OpenAI, Claude, Ollama API를 말할 줄 알기 때문에, 대부분의 기존 워크플로에는 base URL 하나만 바꾸면 끼워 넣을 수 있습니다—전용 SDK가 필요 없습니다.
기존 OpenAI 클라이언트 재사용 #
OpenAI 호환 클라이언트를 로컬 exo 엔드포인트로 향하게 하면 그대로 동작합니다.
# 표준 OpenAI 클라이언트로 로컬 exo 클러스터에 접속
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:52415/v1",
api_key="not-needed", # 로컬 사용 시 exo는 키가 필요 없음
)
response = client.chat.completions.create(
model="model-id",
messages=[{"role": "user", "content": "Summarize the exo project in one sentence."}],
)
print(response.choices[0].message.content)
Jupyter 노트북에서 사용 #
같은 클라이언트가 노트북 안에서도 동작하므로, 클러스터를 상대로 빠르게 실험하기에 편리합니다.
# Jupyter 노트북에서 간단히 테스트
from openai import OpenAI
client = OpenAI(base_url="http://localhost:52415/v1", api_key="not-needed")
response = client.chat.completions.create(
model="model-id",
messages=[{"role": "user", "content": "List three uses for a local AI cluster."}],
)
print(response.choices[0].message.content)
모든 것이 표준 HTTP API를 통하므로, POST 요청을 보낼 수 있는 어떤 언어나 프레임워크와도 exo를 통합할 수 있습니다.
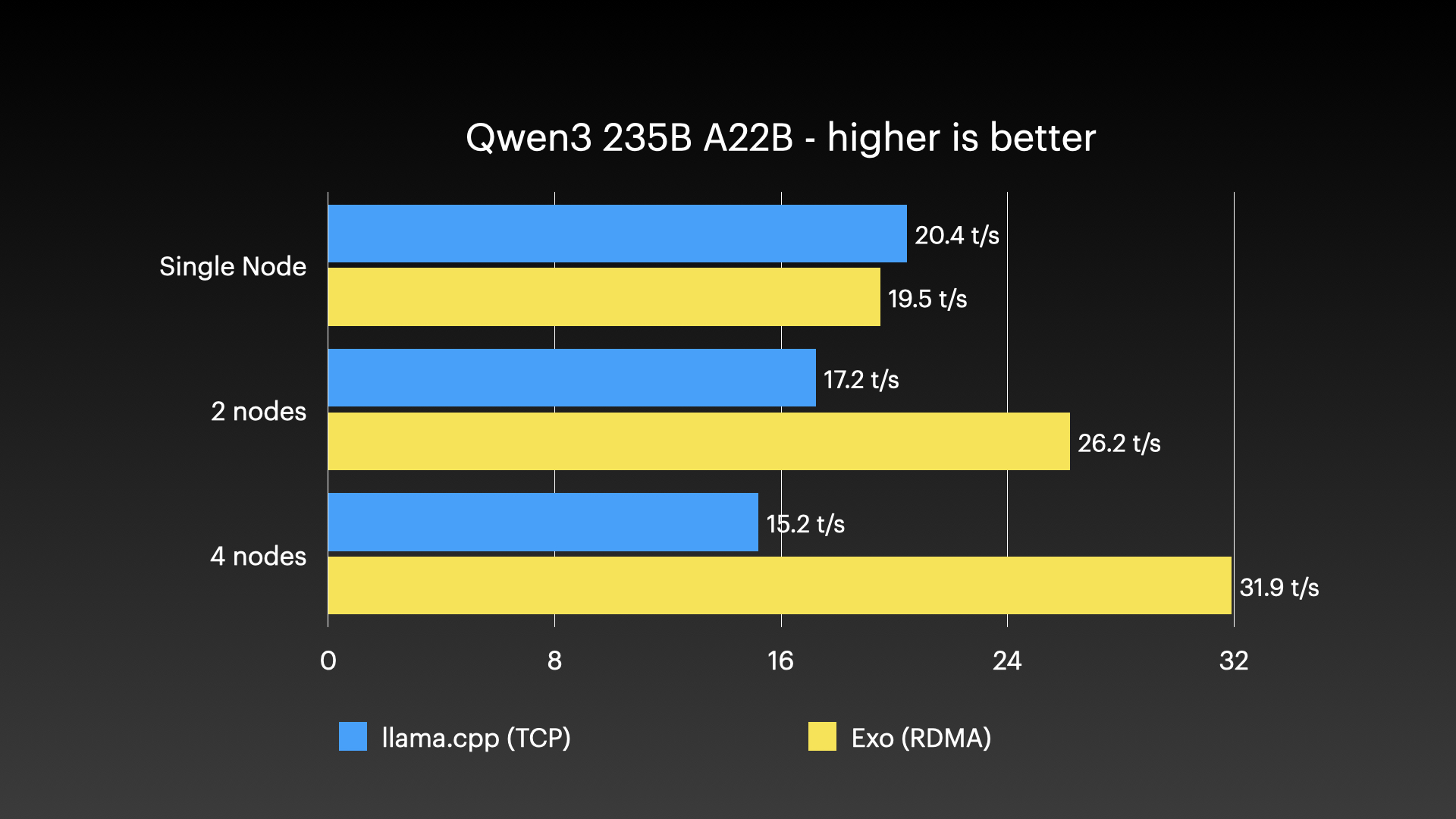
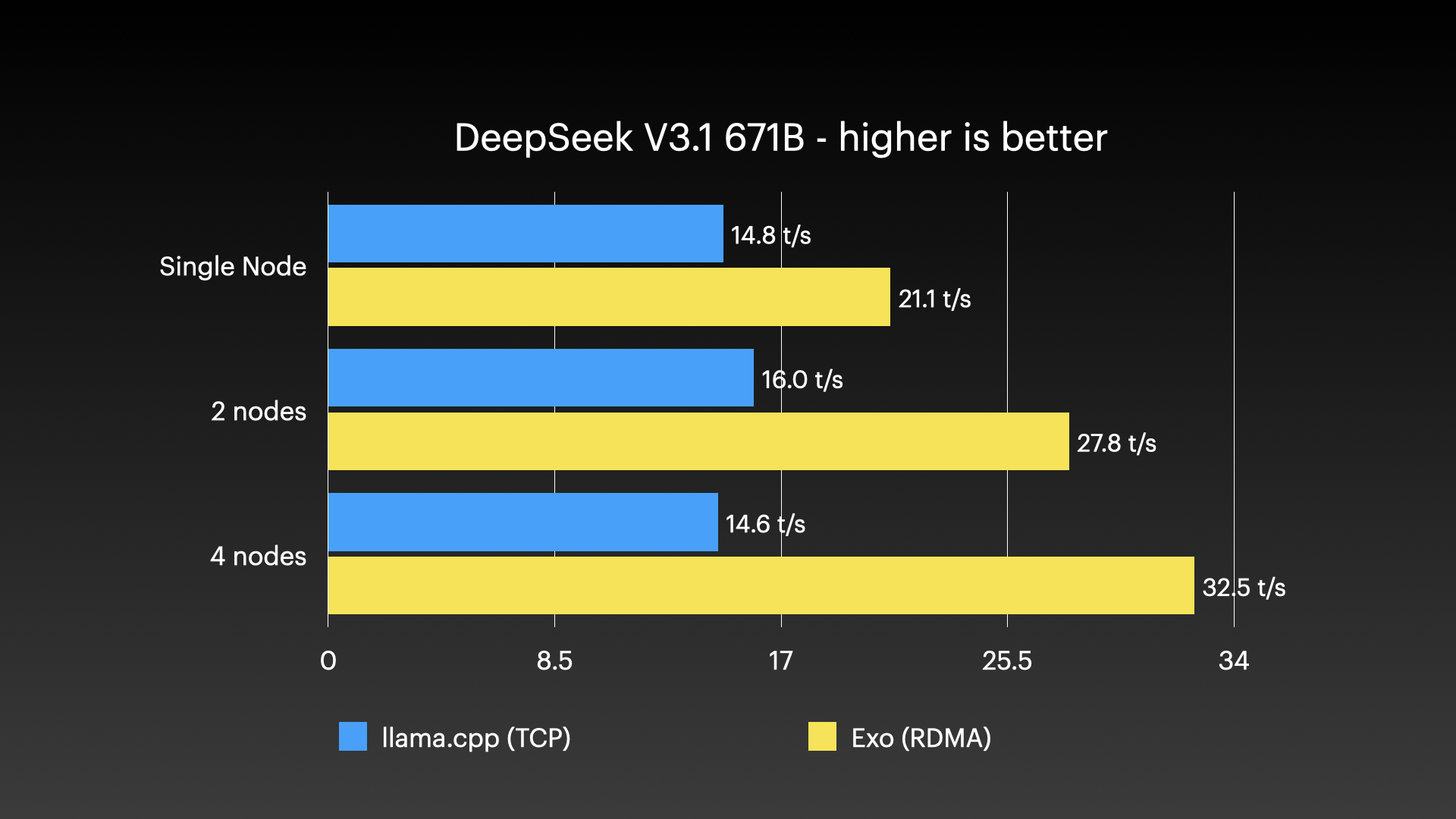
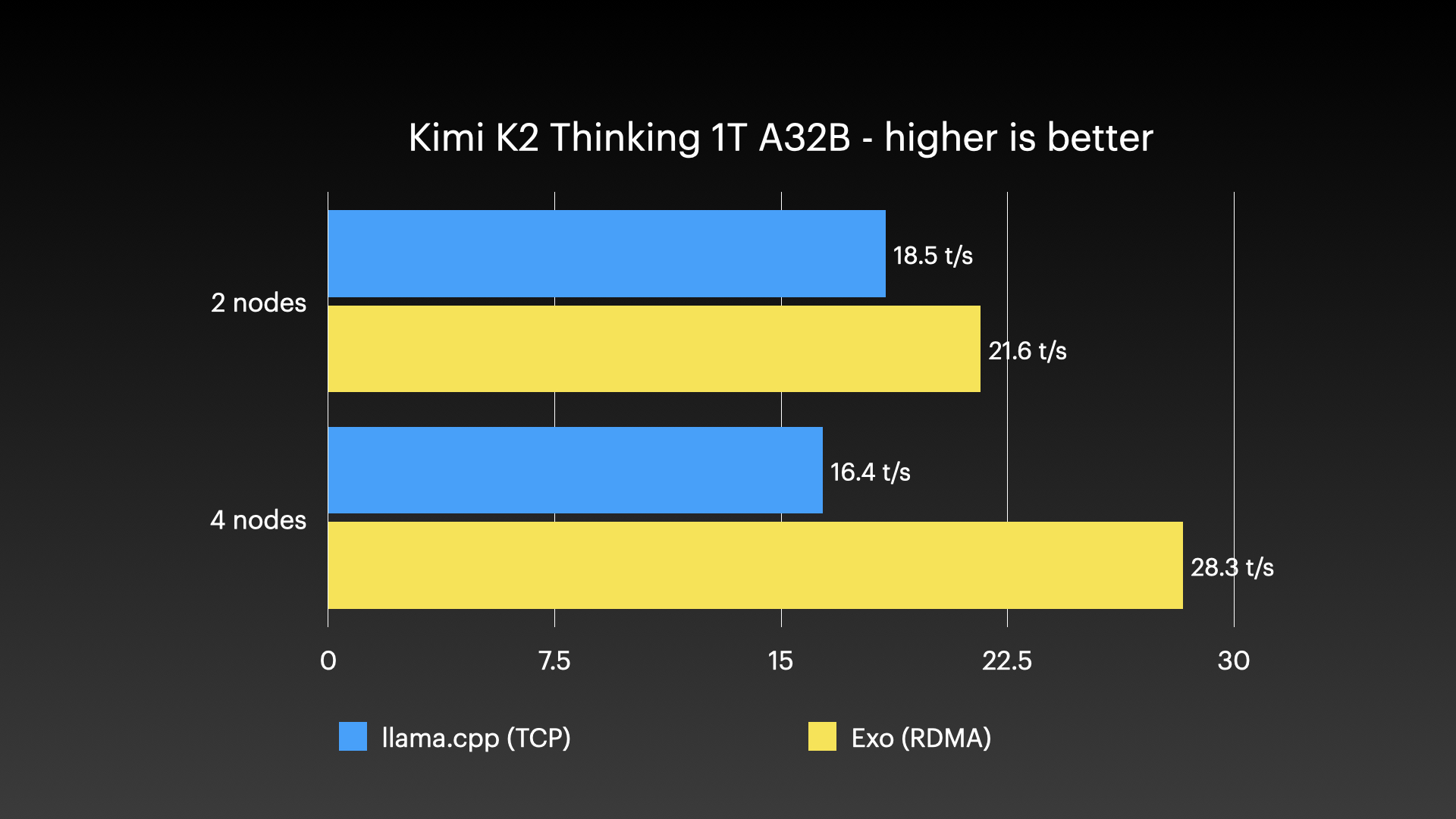
벤치마크와 실사용 #
성능 벤치마크 #
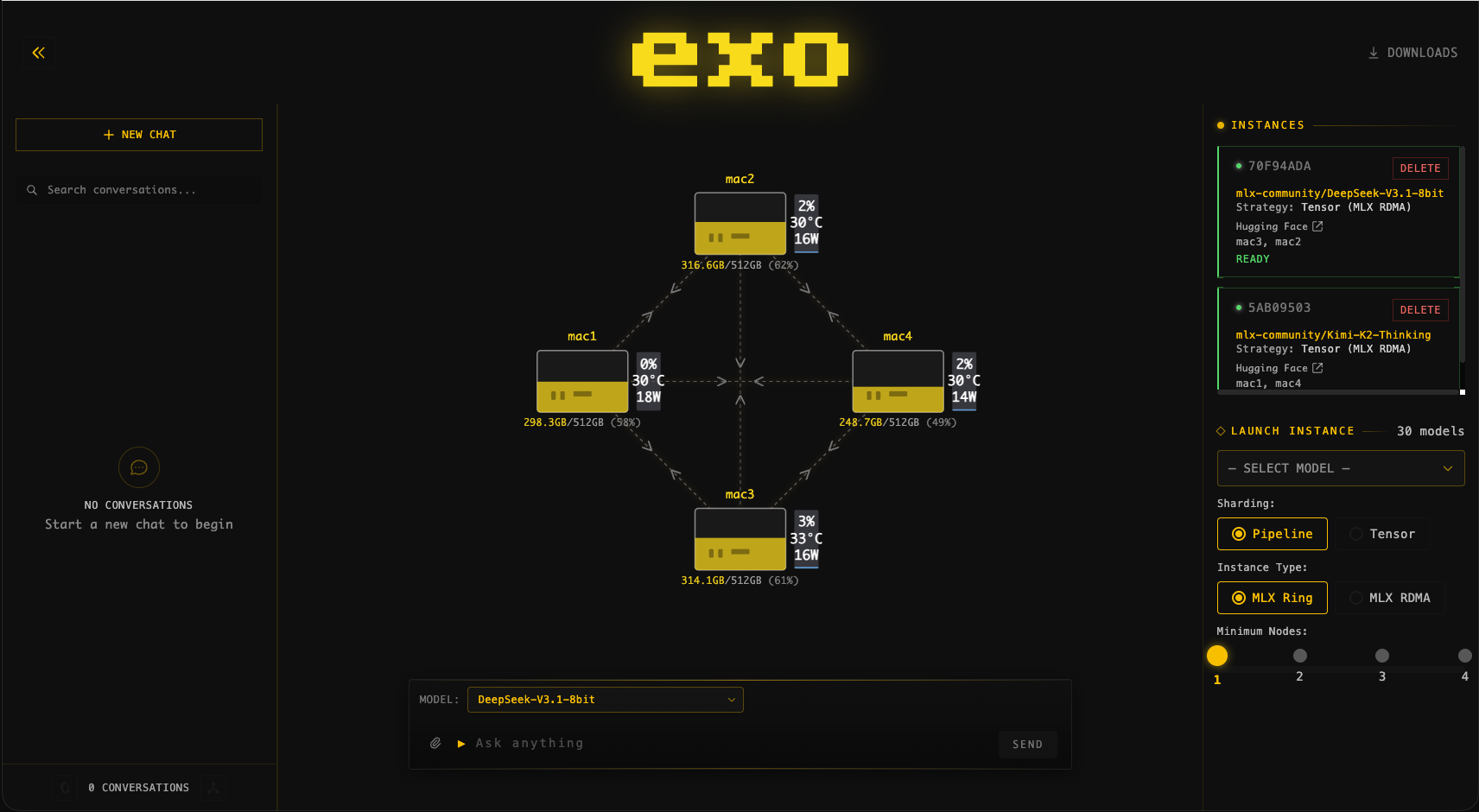
exo는 Apple Silicon Mac 여러 대로 이뤄진 클러스터에서 아주 큰 모델을 돌리는 모습으로 시연된 바 있습니다—단일 소비자용 머신 한 대로는 감당할 수 없는 종류의 작업입니다. 아래 이미지는 실제 클러스터 실행을 보여줍니다.
실사용 사례 #
사적인 로컬 추론: 자신의 하드웨어에서 프런티어 모델을 돌려, 프롬프트와 데이터를 네트워크 안에 머무르게 합니다.
한 대로는 못 올리는 모델 실행: 여러 기기의 메모리를 모아 수천억 파라미터급 모델을 서빙합니다.
클러스터 모니터링: 대시보드가 모든 노드, 모델의 분할 방식, 실시간 처리량을 하나의 화면으로 보여줍니다.
드롭인 API 대체: exo가 OpenAI, Claude, Ollama API를 그대로 흉내 내므로, base URL만 바꾸면 호스팅 엔드포인트를 대신할 수 있습니다.
Apple Silicon 랩: Mac을 여러 대 가진 팀이라면 Thunderbolt로 이어 붙여, 이미 가진 하드웨어로 쓸 만한 추론 클러스터를 꾸릴 수 있습니다.
대안과의 비교 #
관련 오픈소스 도구 소개도 함께 보세요.
exo가 로컬에서 모델을 돌리는 유일한 방법은 아니며, 단일 머신 도구가 못 하는 매우 구체적인 문제—큰 모델 하나를 여러 기기에 펼치기—를 해결합니다. 아래 표는 흔한 대안 두 가지와의 차이를 대략 그려 봅니다. ollama/ollama(단일 머신 로컬 서빙)과 ggml-org/llama.cpp(많은 로컬 도구가 기반으로 삼는 추론 엔진)입니다.
| 항목 | exo-explore/exo | ollama/ollama | ggml-org/llama.cpp |
|---|---|---|---|
| 라이선스 | Apache-2.0 | MIT | MIT |
| 주요 언어 | Python / Rust | Go | C/C++ |
| 멀티 기기 클러스터 | 지원(자동 발견) | 미지원(단일 머신) | 미지원(단일 머신) |
| GPU 가속 | Apple Silicon(리눅스는 당분간 CPU) | NVIDIA / Apple / 기타 | NVIDIA / Apple / CPU |
| 설치 | 소스 빌드 또는 macOS 앱 | 한 줄 설치 | 소스 컴파일 |
| API 호환성 | OpenAI + Claude + Ollama | OpenAI + 네이티브 Ollama | OpenAI 호환 서버 |
| 가장 적합한 곳 | 한 대로 안 들어가는 모델 | 손쉬운 단일 머신 로컬 서빙 | 저수준 엔진 / 임베딩 |
| 대시보드 | 웹 대시보드(52415 포트) | CLI + REST API | CLI / 최소 서버 |
솔직한 요약은 이렇습니다. 모델이 한 머신에 넉넉히 들어간다면 Ollama 같은 단일 머신 도구가 더 단순하고 더 많은 GPU에서 잘 지원됩니다. exo는 모델이 어느 한 기기에는 너무 크고, 여러 머신—특히 Apple Silicon Mac들—을 하나의 클러스터로 묶고 싶을 때 진가를 발휘합니다.
한계와 솔직한 평가 #
exo는 분명 쓸모 있지만, 빠르게 변하는 신생 프로젝트입니다. 솔직한 주의사항 몇 가지를 짚어 둡니다.
Apple Silicon이 강력한 경로입니다. 현재 GPU 가속은 Apple Silicon을 겨냥합니다. 리눅스는 당분간 CPU 전용(GPU 지원은 진행 중)이라, 리눅스 GPU 머신이 기대만큼 빠르지 않을 수 있습니다.
큰 모델 클러스터를 위해 만들어졌습니다. 모델이 이미 한 머신에 들어간다면 exo의 분산 장치는 과합니다—단일 머신 도구가 더 단순할 것입니다.
소스 빌드에는 실제 사전 요구사항이 있습니다. 소스에서 실행하려면
uv, Node, nightly Rust 툴체인, (macOS에서는) Xcode와 추가 도구가 필요합니다. macOS 앱은 이를 피할 수 있지만, 소스 사용자는 한 줄 설치보다 무거운 설정을 각오해야 합니다.빠르게 변하는 코드베이스. 활발히 개발 중인 프로젝트라 버전 간에 API와 동작이 바뀔 수 있습니다. 안정성이 필요하다면 검증된 커밋에 고정하세요.
네트워크 의존적. 클러스터 전반의 성능은 기기 간 연결에 좌우됩니다. 노드 사이 네트워크가 느리면 추론의 병목이 될 수 있으며, 가장 빠른 구성에서 Thunderbolt 연결이 중요한 이유가 바로 이것입니다.
이런 트레이드오프는 exo가 맞지 않을 수 있는 지점을 짚어 주지만, 동시에 진짜 강점도 또렷이 드러냅니다. 이미 가진 하드웨어로, 다른 데서는 아예 돌릴 수 없는 모델을 돌린다는 점입니다.
마치며 #
exo-explore의 exo는 자신의 하드웨어에서 프런티어 AI를 돌릴 수 있게 해 주는 매력적인 도구입니다. GitHub 스타 45,000개 이상, Apache-2.0 라이선스, 자동 클러스터링, 그리고 OpenAI·Claude·Ollama를 이미 말할 줄 아는 API까지 갖췄습니다. 가장 빛나는 지점은, 여러 기기—특히 Apple Silicon Mac—를 모아 한 대로는 못 올리는 모델을 돌리는 것입니다. 자연스러운 다음 단계는 앱을 설치하거나 저장소를 클론하고, 각 기기에서 노드를 띄운 뒤, 대시보드에서 클러스터가 모이는 모습을 지켜보는 일입니다.
- 오픈소스 AI 도구 소식을 가장 먼저 받으려면 dibi8 영어 텔레그램 그룹에 참여하세요.
- 다음 읽을거리: dibi8의 관련 가이드.
Sources & Further Reading:
- GitHub repository: https://github.com/exo-explore/exo
- Official docs / README: https://github.com/exo-explore/exo#readme
위 링크 중 일부는 제휴(affiliate) 링크입니다. 이 링크를 통해 가입하시면 dibi8.com이 약간의 수수료를 받을 수 있으며, 여러분에게는 추가 비용이 들지 않습니다. 사이트 운영과 무료 콘텐츠 유지에 도움이 됩니다.
💬 댓글 토론