Marker: PDF, DOCX, EPUB를 Markdown/JSON으로 빠르게 변환 — 2026 실전 가이드
Marker(datalab-to/marker)는 PDF, DOCX, EPUB 등 문서를 Markdown, JSON, HTML, chunks로 빠르고 정확하게 변환합니다. GitHub 스타 35,694개, 코드 라이선스는 GPL-3.0. 설치, CLI와 Python API, 실제 코드 예제, LLM 모드, 그리고 대안 도구와의 솔직한 비교를 다룹니다.
- ⭐ 35694
- GPL-3.0
- 업데이트 2026-06-02
들어가며 #
문서를 깔끔하고 구조화된 텍스트로 바꾸는 일은 말로는 간단해 보이지만, 표와 수식, 다단 레이아웃이 가득한 실제 PDF에 직접 적용해 보면 결코 쉽지 않습니다. datalab-to/marker는 바로 이 문제를 위해 만들어졌습니다. 딥러닝 파이프라인을 통해 PDF를 비롯한 다양한 문서 유형을 Markdown, JSON, HTML, 또는 RAG에 바로 쓸 수 있는 chunks로 변환하며, 까다로운 콘텐츠는 선택적으로 LLM을 한 번 더 거치게 할 수 있습니다. 이 가이드에서는 설치, 명령줄 도구, Python API, 그리고 대안과의 솔직한 비교를 차례로 살펴보며 여러분의 프로젝트에 맞는지 판단할 수 있도록 돕겠습니다.
자, 시작해 봅시다!
![]()
marker overview (source: datalab-to/marker repo, via dibi8 analysis)
marker란? #
Marker는 Datalab이 만든 Python 문서 변환 도구로, PDF(그리고 이미지, PPTX, DOCX, XLSX, HTML, EPUB)를 Markdown, JSON, HTML, 그리고 청크(chunks) 형태로 변환합니다. 개발자들 사이에서 큰 인기를 얻어 GitHub 스타가 35,694개를 넘어섰습니다. 단일 OCR 단계가 아니라, 텍스트를 추출하고 페이지 레이아웃과 읽기 순서를 감지한 뒤, 블록을 정리·서식화하고, 선택적으로 LLM을 적용해 표·양식·인라인 수식의 정확도를 높이는 하나의 파이프라인으로 동작합니다.
marker의 동작 원리 #
marker는 문서를 Markdown, JSON, HTML, chunks로 빠르고 정확하게 변환하도록 설계되었습니다. 파이프라인이 어떻게 작동하는지 단계별로 살펴보겠습니다.
- 텍스트 추출: 가능한 경우 문서에서 텍스트를 직접 가져오고, 스캔본이나 이미지 기반 페이지에서는 OCR로 대체합니다.
- 레이아웃 및 읽기 순서: 딥러닝 모델이 페이지 레이아웃과 올바른 읽기 순서를 감지합니다. 다단 PDF가 읽기 좋게 출력되는 것은 바로 이 단계 덕분입니다.
- 블록 정리 및 서식화: 각 블록(제목, 문단, 표, 수식, 코드)을 정리하고 서식화하며, 표는 Markdown/HTML로, 수식은 LaTeX로 렌더링합니다.
- 선택적 LLM 보정:
--use_llm을 사용하면 모델(Gemini, Claude, OpenAI, 또는 로컬 Ollama 모델)을 활용해 표·양식·수식의 정확도를 높입니다. - 렌더링 및 후처리: 블록들을 합쳐 후처리한 뒤, 선택한 출력 형식으로 만들어 냅니다.
이 모든 과정을 가장 간단하게 다루는 방법은 CLI이며, 다음에서 다룹니다.
marker architecture (source: datalab-to/marker repo, via dibi8 analysis)
설치 및 설정 #
marker를 예약 실행되는 프로덕션 작업으로 돌리려면 항상 켜져 있는 서버가 필요합니다. DigitalOcean에서 한 대 띄우거나(신규 계정에는 무료 체험 크레딧 제공), dibi8.com을 호스팅하는 것과 같은 IDC에서 제공하는 저지연 홍콩 VPS인 HTStack을 이용할 수 있습니다.
datalab-to/marker를 시작하려면 PyPI에서 설치하면 됩니다.
pip 사용 #
먼저 시스템에 Python이 설치되어 있는지 확인한 뒤, marker-pdf 패키지를 설치합니다.
pip install marker-pdf
PDF가 아닌 형식(DOCX, PPTX, XLSX, EPUB, HTML, 이미지)을 변환하려면 전체 추가 의존성과 함께 설치하세요.
pip install marker-pdf[full]
저장소 클론 #
또는 로컬 개발을 위해 GitHub에서 저장소를 직접 클론할 수도 있습니다.
git clone https://github.com/datalab-to/marker.git
cd marker
pip install -e .
흔한 오류와 해결 #
흔한 문제 중 하나는 시스템 환경과 가상 환경의 설치가 뒤섞여 marker_single 명령을 찾지 못하거나 의존성 충돌이 발생하는 경우입니다. 설치하고 실행하기 전에 가상 환경이 활성화되어 있는지 확인하세요.
# Activate the virtual environment (assuming you're using venv)
source .venv/bin/activate
# Install, then run
pip install marker-pdf
marker_single /path/to/file.pdf
첫 실행 시 GPU나 모델 다운로드 관련 문제가 발생하면, 저장소의 README.md에서 안내를 확인하거나 GitHub에 이슈를 등록하세요.
핵심 사용법 #
marker-pdf를 설치하면 두 개의 CLI 진입점이 생깁니다. 단일 파일용 marker_single과 폴더 전체용 marker입니다.
예제 1: 단일 파일 변환 #
문서 하나를 Markdown(기본 출력 형식)으로 변환하려면:
marker_single /path/to/report.pdf
변환 결과는 출력 디렉터리에 기록되며, 형식은 --output_format으로 제어할 수 있습니다.
예제 2: 출력 형식 선택 #
Marker는 markdown, json, html, chunks(RAG 파이프라인을 위해 설계된 평탄화된 JSON 레이아웃)를 지원합니다.
marker_single /path/to/report.pdf --output_format json
예제 3: 폴더 단위 변환 #
폴더 안의 모든 문서를 일괄 변환하려면:
marker /path/to/input/folder --output_format markdown
예제 4: 특정 페이지 변환 또는 LLM 사용 #
변환을 특정 페이지 범위로 제한하고 LLM 보조 정확도를 켤 수 있습니다.
marker_single /path/to/report.pdf --page_range "0,5-10,20" --use_llm
--page_range는 쉼표로 구분된 페이지와 범위를 받으며, --use_llm은 까다로운 표·양식·인라인 수식을 모델(Gemini, Claude, OpenAI, 또는 Ollama)로 보내 정확도를 높입니다. 대규모 멀티 GPU 작업을 위해 marker_chunk_convert도 있습니다.
NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
이 예제들이면 시작하기에 충분합니다. 전체 플래그 목록은 GitHub의 공식 README를 참고하세요.
통합 #
marker는 CLI이면서 Python 라이브러리이기도 하므로, 스크립트·노트북·파이프라인에 깔끔하게 녹아듭니다.
Python API 사용 #
몇 줄의 코드로 파일을 변환하고, 렌더링된 텍스트와 추출된 이미지를 얻을 수 있습니다.
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = PdfConverter(artifact_dict=create_model_dict())
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
출력 형식을 바꾸거나 LLM 서비스를 켜려면 ConfigParser를 통해 구동하세요.
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.config.parser import ConfigParser
config_parser = ConfigParser({"output_format": "json"})
converter = PdfConverter(
config=config_parser.generate_config_dict(),
artifact_dict=create_model_dict(),
processor_list=config_parser.get_processors(),
renderer=config_parser.get_renderer(),
llm_service=config_parser.get_llm_service(),
)
rendered = converter("FILEPATH")
Marker에는 전용 변환기도 함께 제공됩니다. 표만 처리하는 TableConverter, OCR 결과만 출력하는 OCRConverter, 그리고 Pydantic JSON 스키마에 따라 구조화된 데이터를 추출하는 베타 버전 ExtractionConverter입니다.
CI/CD 파이프라인 통합 #
순수 CLI이기 때문에, marker를 어떤 CI/CD 작업의 한 단계로도 실행할 수 있습니다. 다음은 push가 있을 때마다 PDF를 변환하는 최소한의 GitHub Actions 예시입니다.
name: Convert PDF to Markdown
on:
push:
branches: [ master ]
jobs:
convert-pdf:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install marker
run: pip install marker-pdf
- name: Convert PDF to Markdown
run: marker_single docs/report.pdf --output_format markdown
이렇게 하면 노트북에서든 자동화된 빌드 파이프라인에서든 marker를 손쉽게 통합할 수 있습니다.
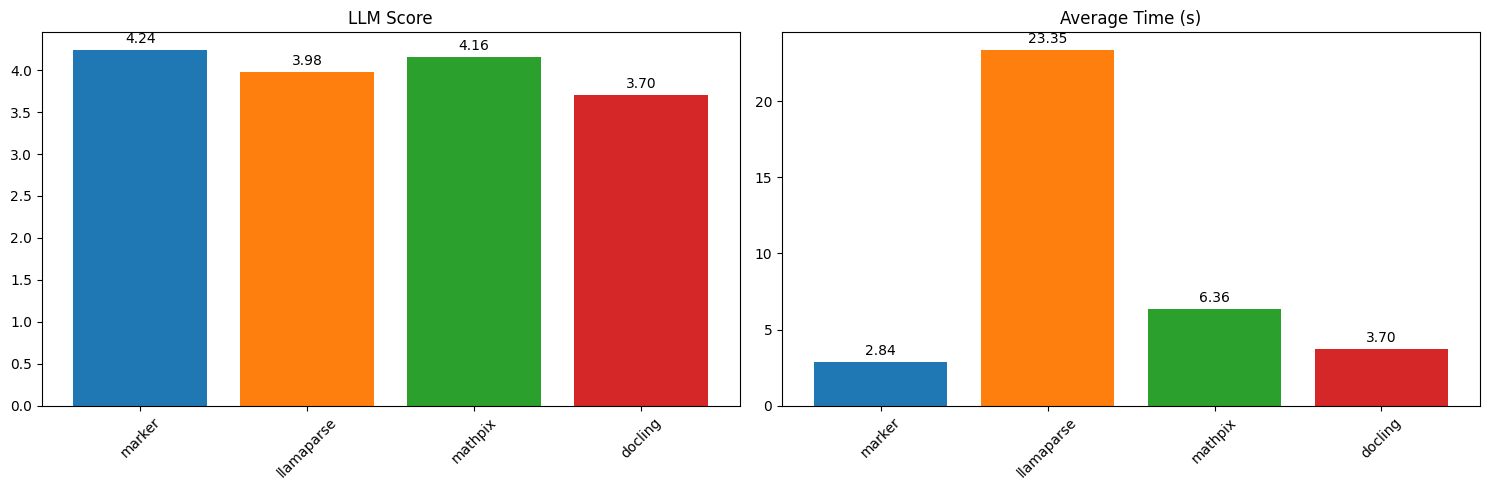
벤치마크 및 실제 사용 #
처리량 #
프로젝트의 README에 따르면, marker는 H100 GPU에서 배치 모드로 초당 약 25페이지에 도달할 수 있습니다. 실제 처리량은 하드웨어, 문서 복잡도, 그리고 --use_llm 사용 여부(LLM 단계는 속도를 정확도와 맞바꿉니다)에 크게 좌우됩니다. 어떤 단일 수치든 보장이 아니라 상한선으로 여기고, 직접 자신의 문서로 벤치마크하세요.
실제 사용 사례 #
Marker는 문서 검색·RAG 코퍼스 구축, 보고서에서 표와 양식 추출, 학술 논문·매뉴얼·도서를 후속 처리를 위한 깔끔한 Markdown으로 변환하는 등의 작업에 흔히 쓰입니다. 특히 chunks 출력 형식은 검색 증강 생성(RAG) 파이프라인을 겨냥한 것으로, 각 블록이 자체 완결된 HTML로 제공됩니다.

marker benchmark results (source: datalab-to/marker repo, via dibi8 analysis)
대안과의 비교 #
관련 오픈소스 도구 정리도 함께 참고하세요.
PDF를 Markdown으로 바꾸는 도구를 고를 때는 정확도, 형식 지원 범위, 속도, 라이선스를 따져봐야 합니다. 아래는 marker와 두 가지 흔한 오픈소스 대안인 pdfplumber(텍스트/표 추출)와 pymupdf4llm(PyMuPDF 기반 Markdown 익스포터)의 개략적인 비교입니다.
| 항목 | datalab-to/marker | pdfplumber | pymupdf4llm |
|---|---|---|---|
| 언어 | Python | Python | Python |
| 접근 방식 | 딥러닝 레이아웃 + OCR + 선택적 LLM | 규칙 기반 텍스트 추출 | PyMuPDF 기반 추출 |
| 입력 형식 | PDF, 이미지, PPTX, DOCX, XLSX, HTML, EPUB | PDF만 | PDF 및 일부 |
| 출력 형식 | Markdown, JSON, HTML, chunks | 텍스트, 표(dict) | Markdown |
| OCR / 스캔본 | 내장 OCR | 기본 OCR 없음 | 제한적 |
| LLM 모드 | 선택적(--use_llm) | 없음 | 없음 |
| 적합한 용도 | 복잡한 레이아웃, 표, RAG, 스캔본 | 정밀한 표/좌표 작업 | 빠르고 단순한 Markdown 출력 |
marker는 문서가 복잡할 때—다단 레이아웃, 수식, 스캔 페이지, 표—가장 빛을 발합니다. 레이아웃 모델과 선택적 LLM 단계가 규칙 기반 도구가 놓치는 구조까지 처리하기 때문입니다. pdfplumber나 pymupdf4llm 같은 더 가벼운 도구는 속도가 빠르고 의존성이 적어, PDF가 본래 단순하고 디지털 원본이며 순수 텍스트일 때 더 적합합니다. 실제 문서가 얼마나 지저분한지에 따라 고르면 됩니다.
한계 및 솔직한 평가 #
marker는 복잡한 문서에 강하지만, 미리 알아둘 만한 실질적인 절충점들이 있습니다.
- 무거운 의존성과 높은 하드웨어 요구: marker는 딥러닝 모델에 의존하므로 GPU 유무가 큰 차이를 만듭니다. CPU 전용 머신에서도 동작하지만 훨씬 느리고, 설치 용량도 규칙 기반 라이브러리보다 큽니다.
- 복잡한 표는 완벽하지 않음: 페이지를 넘나드는 표나 깊게 중첩·병합된 셀이 있는 표는 여전히 어긋나게 나올 수 있어 수동 정리가 필요할 수 있습니다.
- LLM 모드는 비용과 지연을 더함:
--use_llm은 정확도를 높이지만 외부 모델 호출(그리고 로컬 Ollama 모델을 쓰지 않는 한 API 비용)을 추가하므로 더 느리고 무료가 아닙니다. - 속도 편차가 큼: 헤드라인 처리량 수치는 고급 GPU와 배치 처리를 전제로 합니다. 평범한 하드웨어나 LLM 모드에서는 훨씬 느려질 수 있습니다.
- 라이선스의 미묘한 점: 코드는 GPL-3.0이지만 모델 가중치는 수정된 AI Pubs Open Rail-M 라이선스를 따릅니다. 연구·개인 사용과 소규모 기업에는 무료이고, 대규모 조직에는 상업용 라이선스가 필요합니다. 대규모 배포 전에 조항을 확인하세요.
marker가 여러분의 구체적인 용도에 맞는지 판단할 때 이러한 절충점은 중요하게 고려해야 합니다.
마치며 #
35,694개가 넘는 스타와, 실제 세계의 지저분한 문서를 다루기 위해 설계된 파이프라인 덕분에, PDF·Office 파일·EPUB에서 정확한 Markdown, JSON, HTML, 또는 청크 출력이 필요할 때—특히 표·수식·스캔 페이지가 포함된 경우—marker는 든든한 선택지입니다. 다음 단계는 설치한 뒤, 여러분의 문서 중 하나로 직접 돌려보는 것입니다.
pip install marker-pdf
marker_single /path/to/your/file.pdf
- 오픈소스 AI 도구 소식을 받으려면 dibi8 영어 Telegram 그룹에 참여하세요.
- 이어서 읽기: dibi8의 관련 가이드.
출처 및 더 읽어보기:
- GitHub 저장소: https://github.com/datalab-to/marker
- 공식 문서 / README: https://github.com/datalab-to/marker#readme
위 링크 중 일부는 제휴 링크입니다. 이를 통해 가입하시면 dibi8.com이 수수료를 받을 수 있으며, 추가 비용은 들지 않습니다. 사이트 운영과 무료 콘텐츠 유지에 도움이 됩니다.
💬 댓글 토론