Promptfoo: LLM 프롬프트를 테스트·평가·레드팀하기 — 2026 실전 가이드
Promptfoo는 LLM 앱을 평가하고 레드팀하기 위한 오픈소스 CLI이자 라이브러리입니다. 간단한 선언형 설정만으로 GPT, Claude, Gemini, DeepSeek를 비교하고 CLI와 CI/CD에 매끄럽게 연동할 수 있습니다. 이 2026 가이드에서는 설치, promptfooconfig.yaml, 어서션, 레드팀 테스트를 다룹니다.
- ⭐ 21825
- MIT
- 업데이트 2026-06-02
들어가며 #
GPT, Claude, Gemini, DeepSeek 같은 모델로 개발해 본 사람이라면 “플레이그라운드에서 잘 나온다"는 것과 “프로덕션에서 안정적으로 동작한다"는 것이 전혀 다른 이야기임을 잘 알 것입니다. Promptfoo는 LLM 애플리케이션을 평가하고 레드팀하기 위한 오픈소스 CLI이자 라이브러리입니다. 시행착오식 접근을, 로컬에서도 돌리고 CI/CD에도 연결할 수 있는 선언형 테스트 설정으로 바꿔 줍니다. 이 가이드에서는 설치부터 promptfooconfig.yaml 작성, 평가 실행, 모델 비교, 그리고 레드팀 스캔까지 차례로 진행합니다.
Promptfoo란? #
Promptfoo는 LLM 앱을 평가하고 레드팀하기 위한 CLI이자 라이브러리입니다. 여러분은 프롬프트, 실행 대상으로 삼을 provider(모델), 그리고 어서션이 달린 테스트 케이스 묶음만 기술하면 됩니다. Promptfoo는 모든 프롬프트를 모든 테스트 케이스에 통과시키고 어서션을 하나씩 확인한 뒤, 각 모델의 성능을 나란히 비교한 화면을 보여 줍니다.
핵심 기능은 다음과 같습니다.
- 평가 — 프롬프트를 여러 provider에서 실행하고 어서션(정확 일치, 포함, 의미 유사도, LLM 채점 루브릭 등)으로 출력을 채점합니다.
- 모델 비교 — 동일한 입력으로 GPT, Claude, Gemini, DeepSeek 등을 비교합니다.
- 레드팀 — 적대적 테스트 케이스를 생성해 배포 전에 앱의 취약점을 탐색합니다.
- CI/CD 연동 — 선언형 설정은 터미널이 있는 곳이라면 어디서든 실행되며, GitHub Actions도 포함됩니다.
이 프로젝트는 TypeScript로 작성되었고 MIT 라이선스로 배포되며 promptfoo 팀이 유지보수합니다.
Promptfoo의 동작 방식 #
작업 흐름은 설정 우선입니다.
선언형 설정 — 하나의
promptfooconfig.yaml에prompts,providers,tests를 정의합니다. 일반적인 경우에는 별도의 연결 코드가 필요 없습니다.명령줄 인터페이스(CLI) —
promptfoo eval로 평가를 실행합니다. 결과 표를 터미널에 출력하고 결과를 로컬에 저장합니다.로컬 웹 뷰어 —
promptfoo view는 평가 결과를 시각화하는 로컬 웹 UI를 열어, 모델별 출력을 셀 단위로 비교할 수 있게 해 줍니다.
다음은 최소한의 promptfooconfig.yaml 예시입니다.
# promptfooconfig.yaml
description: "GPT vs Claude on a couple of prompts"
prompts:
- "What is the capital of {{country}}?"
- "Explain quantum mechanics in one sentence."
providers:
- openai:gpt-4o-mini
- anthropic:messages:claude-3-5-sonnet-20241022
tests:
- vars:
country: France
assert:
- type: contains
value: Paris
이 설정은 두 프롬프트를 각각 두 provider에서 실행합니다. 첫 프롬프트에서는 {{country}}를 치환하고, 출력에 “Paris"가 포함되어 있는지 어서션으로 확인합니다. API 키는 설정 파일이 아니라 환경 변수(예: OPENAI_API_KEY, ANTHROPIC_API_KEY)에서 읽어 옵니다.
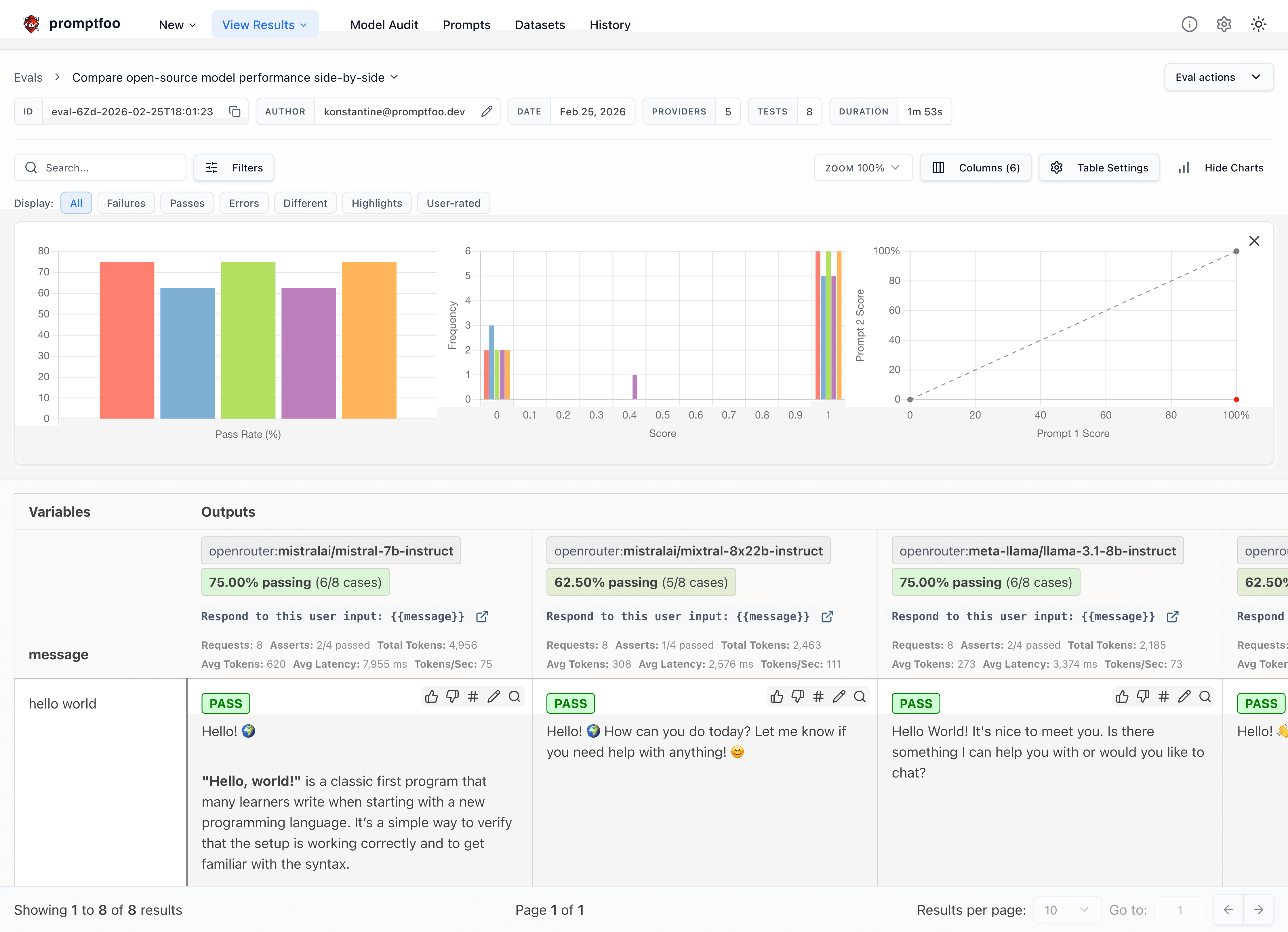
- Source Code: promptfoo GitHub

promptfoo 자가 채점 화면 (출처: promptfoo/promptfoo 저장소, dibi8 분석 정리)
설치 및 설정 #
promptfoo를 예약된 프로덕션 작업으로 돌리고 싶다면 항상 켜져 있는 서버가 필요합니다 — DigitalOcean에서 한 대 띄우거나(신규 계정 무료 크레딧 제공), 낮은 지연을 원한다면 HTStack의 홍콩 VPS를 쓰면 됩니다(dibi8.com을 호스팅하는 바로 그 IDC입니다).
Promptfoo는 Node.js ^20.20.0 또는 >=22.22.0이 필요합니다. 버전을 확인하세요.
node -v
Node.js가 필요하면 공식 사이트에서 받으면 됩니다.
설치 #
promptfoo를 가장 빠르게 써 보는 방법은 아예 설치하지 않는 것입니다.
npx promptfoo@latest init --example getting-started
전역 설치를 원한다면 환경에 맞는 방법을 고르세요.
# npm
npm install -g promptfoo
# Homebrew
brew install promptfoo
# pip
pip install promptfoo
API 키 설정 #
Promptfoo는 provider 자격 증명을 환경 변수에서 읽습니다. OpenAI의 경우:
export OPENAI_API_KEY=sk-abc123
테스트하려는 provider에 맞는 변수를 사용하세요(예: Claude는 ANTHROPIC_API_KEY). 키 설정을 잊으면 평가 실행 시 provider가 인증 오류를 반환합니다 — 변수를 설정하고 다시 실행하면 됩니다.
첫 평가 실행하기 #
init을 실행하면 현재 디렉터리에 promptfooconfig.yaml이 생깁니다. 평가를 실행하고 뷰어를 엽니다.
promptfoo eval
promptfoo view
promptfoo eval은 결과를 터미널에 출력하고, promptfoo view는 더 풍부한 나란히 비교를 위한 로컬 웹 UI를 엽니다. 막히면 공식 문서를 참고하거나 GitHub에 이슈를 남기세요.
핵심 사용법 #
예제 1: 간단한 어서션 #
기대하는 부분 문자열을 확인하는 설정을 만들어 봅니다.
# promptfooconfig.yaml
description: "Basic prompt test"
prompts:
- "What is the capital of {{country}}?"
providers:
- openai:gpt-4o-mini
tests:
- vars:
country: France
assert:
- type: contains
value: Paris
실행:
promptfoo eval
Promptfoo가 해당 테스트 케이스를 실행하고 어서션 통과 여부를 보고합니다.
예제 2: 여러 어서션 유형으로 모델 비교하기 #
여러 provider를 나열하고 정확·의미·LLM 채점 등 어서션 유형을 섞어 쓸 수 있습니다.
# promptfooconfig.yaml
description: "GPT vs Claude comparison"
prompts:
- "Answer concisely: {{question}}"
providers:
- openai:gpt-4o
- anthropic:messages:claude-3-5-sonnet-20241022
defaultTest:
assert:
- type: llm-rubric
value: does not describe itself as an AI, model, or chatbot
tests:
- vars:
question: "What is the meaning of life?"
assert:
- type: similar
value: "It depends on the person"
threshold: 0.6
같은 명령을 실행한 뒤 promptfoo view로 두 모델을 셀 단위로 비교합니다.
promptfoo eval
예제 3: CI/CD 파이프라인에서 실행하기 #
터미널이 있는 곳이라면 promptfoo는 어디서든 돌아갑니다. 다음은 어서션이 실패하면 빌드를 실패시키는 GitHub Actions 워크플로입니다.
# .github/workflows/eval.yml
name: Promptfoo Eval
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
eval:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: '22'
- name: Run promptfoo eval
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: npx promptfoo@latest eval
push와 pull request마다 평가 스위트를 실행해, 병합 전에 회귀를 잡아냅니다.
레드팀 #
일반 평가를 넘어, promptfoo는 적대적 테스트 케이스를 생성해 프롬프트 인젝션, 탈옥(jailbreak), 안전하지 않은 출력 같은 취약점을 탐색할 수 있습니다. 레드팀 작업 흐름에는 별도의 하위 명령이 있습니다.
# 대상과 공격 유형을 설정하는 설정 UI 실행
npx promptfoo@latest redteam setup
# 또는 GUI 없이 설정
promptfoo redteam init --no-gui
# 적대적 케이스를 생성해 대상에 실행
promptfoo redteam run
# 발견된 문제 보고서 보기
promptfoo redteam report
보고서는 취약점 범주와 심각도별로 분류되며, 권장 완화책도 함께 제시합니다.
벤치마크와 실제 활용 #
Promptfoo는 프롬프트와 모델 평가에 널리 쓰입니다. 다만 핵심은 단일 리더보드에 의존하는 것이 아니라, 여러분 자신의 프롬프트와 테스트 케이스로 벤치마크하는 것입니다 — 의미 있는 수치는 범용 스위트가 아니라 여러분의 애플리케이션에서 나옵니다.
전형적인 작업 흐름은 다음과 같습니다.
npx promptfoo@latest eval && npx promptfoo@latest view
후보 모델 전체에 테스트 세트를 돌린 뒤 뷰어를 열면, 어떤 프롬프트·어떤 케이스에서 각 모델이 통과했는지 실패했는지를 정확히 볼 수 있습니다. 설정이 선언형이므로 같은 스위트를 개발 중에는 로컬에서, CI에서는 커밋마다 실행할 수 있습니다.
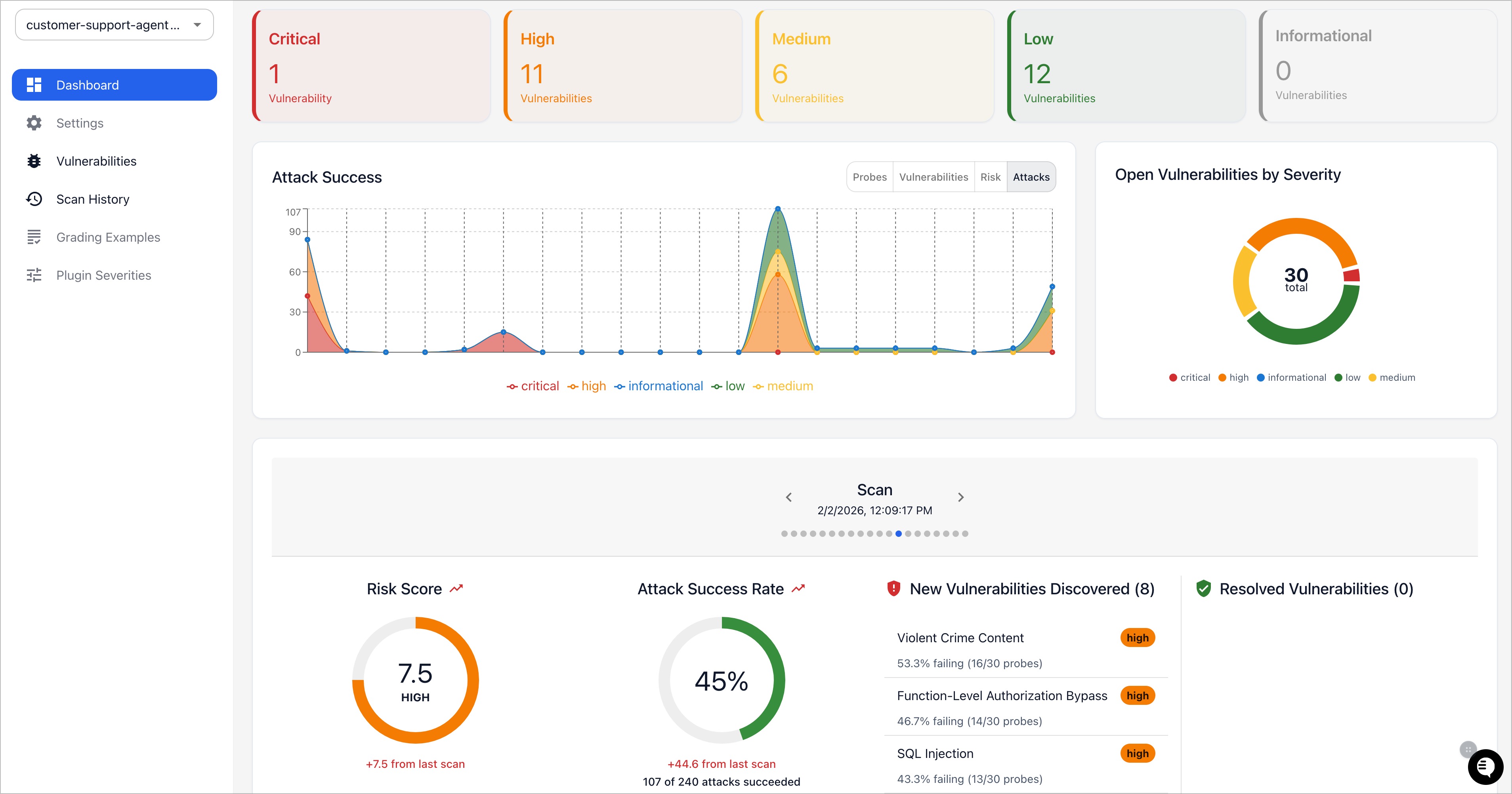
promptfoo 레드팀 대시보드 (출처: promptfoo/promptfoo 저장소, dibi8 분석 정리)
대안과의 비교 #
관련 오픈소스 도구 정리도 함께 참고하세요.
LLM 평가·레드팀 도구를 고를 때 promptfoo의 가장 큰 매력은 선언형 설정, 로컬 우선 작업 흐름, 그리고 내장 레드팀 기능의 결합입니다.
| 항목 | promptfoo |
|---|---|
| Star 수 | 21,825 |
| 라이선스 | MIT |
| 유지보수 | promptfoo |
| 언어 | TypeScript |
| 기본 브랜치 | main |
| 설정 방식 | 선언형 promptfooconfig.yaml(prompts / providers / tests / assert) |
| 인터페이스 | CLI(promptfoo eval / view) 및 라이브러리 사용 |
| 모델 지원 | GPT, Claude, Gemini, DeepSeek 등 다수 provider |
| 레드팀 | 내장(promptfoo redteam 하위 명령) |
| CI/CD | 어떤 터미널에서든 실행; GitHub Actions 일급 지원 |
세부 분석 #
- Star 수 — promptfoo는 GitHub에서 약 21,825개의 star를 보유하고 있으며, 이는 LLM 개발자 사이의 폭넓은 채택을 보여 주는 강력한 신호입니다.
- 선언형 설정 — 테스트를
promptfooconfig.yaml에 작성하면 평가 스위트를 코드와 함께 버전 관리할 수 있어, 로컬과 CI가 동일한 검사를 실행하게 됩니다.
한계와 솔직한 평가 #
Promptfoo는 유능한 도구지만, 알아 둘 만한 트레이드오프가 있습니다.
- 복잡도에 따라 설정이 비대해진다 — 선언형 형식은 일반적인 경우에 훌륭하지만, provider가 많고 동적 변수와 커스텀 어서션이 많은 대형 스위트는 장황해집니다. 프롬프트와 테스트 케이스를 별도 파일로 분리하게 되는 경우가 많습니다.
- 모델 접근은 직접 마련해야 한다 — promptfoo는 평가를 조율할 뿐, 여러분의 provider API 키와 쿼터에 의존합니다. 비용과 속도 제한은 여러분 몫입니다.
- 평가에는 토큰과 시간이 든다 — 여러 provider에 걸친 대형 스위트는 많은 API 호출을 발생시킵니다. 큰 테스트 세트에서는 지연과 비용이 누적됩니다.
- 어서션 설계에 고민이 필요하다 — LLM 채점 루브릭(
llm-rubric)과 의미 검사는 강력하지만 비결정적입니다. 신뢰할 수 있고 의미 있는 어서션을 만들려면 반복이 필요합니다. - 활발히 진화 중이다 — promptfoo는 자주 릴리스됩니다. 그만큼 빠르게 개선되지만 가끔 호환성을 깨는 변경도 있으니, 안정성을 위해 CI에서는 버전을 고정하세요.
이를 표준 도구로 정하기 전에 이런 점들을 따져 볼 만합니다.
맺으며 #
Promptfoo는 프롬프트와 모델 테스트를 막연한 추측에서 재현 가능하고 버전 관리되는 프로세스로 바꿔 줍니다. 하나의 promptfooconfig.yaml만으로 프롬프트를 평가하고, 여러분 자신의 데이터에서 GPT·Claude·Gemini·DeepSeek를 비교하며, 앱의 취약점까지 레드팀할 수 있습니다 — 이 모든 것을 CLI와 CI/CD 안에서요. 가장 좋은 다음 단계는 npx promptfoo@latest init --example getting-started를 실행해 여러분의 프롬프트를 가리킨 뒤, 뷰어를 열어 모델이 실제로 어떻게 동작하는지 확인하는 것입니다.
대규모 스크래핑에는 회전 프록시가 필요합니다 — WebShare가 업계 표준 선택지입니다.
- 오픈소스 AI 도구 소식을 받으려면 dibi8 영어 Telegram 그룹에 참여하세요.
- 이어 읽기: dibi8의 관련 가이드.
출처 및 참고 자료:
- GitHub 저장소: https://github.com/promptfoo/promptfoo
- 공식 문서 / README: https://github.com/promptfoo/promptfoo#readme
위 링크 중 일부는 제휴 링크입니다. 가입 시 dibi8.com이 수수료를 받을 수 있으며, 추가 비용은 발생하지 않습니다. 사이트 운영과 무료 콘텐츠 유지에 도움이 됩니다.
💬 댓글 토론