NVIDIA Cosmos: Open-Source World Models for Physical AI (10K
NVIDIA Cosmos is an open platform of world models, datasets, and tools for building Physical AI — robots, autonomous vehicles, smart infrastructure. Cosmos 3 uses Mixture-of-Transformers for unified language, image, video, audio, and action generation. 16B and 64B models available.
- ⭐ 10928
- Updated 2026-06-13
What if you could predict how the physical world behaves — not by simulating physics equations, but by learning from the world itself?
NVIDIA Cosmos is exactly that: an open-source platform of world models trained to understand and generate the physical world. It doesn’t just generate images of a robot moving — it predicts the physics, the timing, the cause-and-effect of that motion.
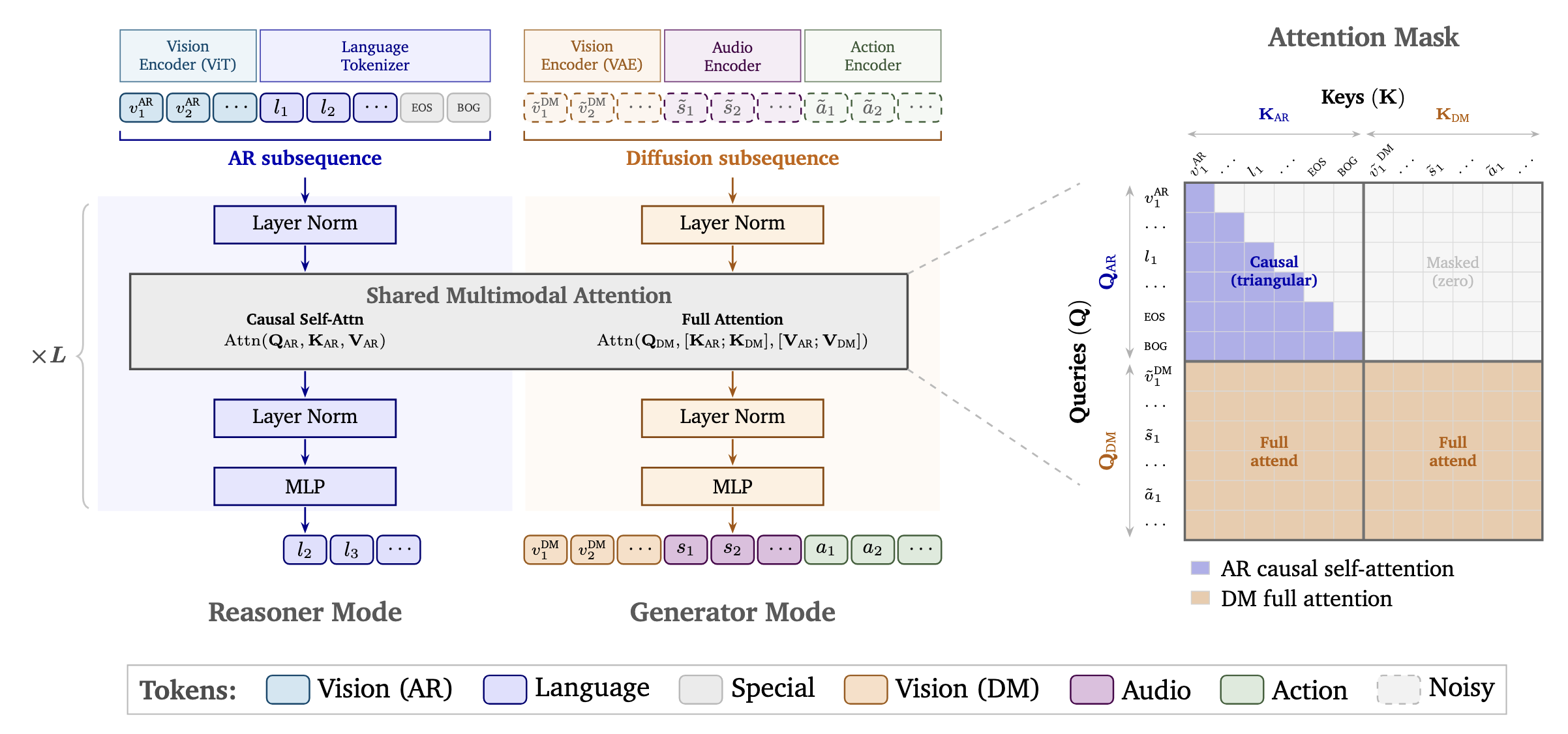
Cosmos 3 is NVIDIA’s latest model family, built on a unified Mixture-of-Transformers (MoT) architecture that handles language, images, video, audio, and action sequences simultaneously. Two runtimes: a Reasoner (for world understanding and planning) and a Generator (for world simulation and synthetic data creation).
The models range from 16B (Nano) to 64B (Super) parameters, available on HuggingFace. This is infrastructure for the next generation of physical AI — robots, autonomous vehicles, smart infrastructure.
Get a DigitalOcean account for running this at scaleWhat Is NVIDIA Cosmos? #
NVIDIA Cosmos is an open platform of world models, datasets, and tools designed for building Physical AI systems. It goes beyond what traditional AI can do:
Traditional AI: Cosmos:
Input → Output → Input → Reasoning → Output
(image in, (understand physics,
caption out) predict future,
generate actions)
Key capabilities:
- World understanding: Analyze videos and images for captions, temporal events, next actions, spatial grounding, physical plausibility, and causal outcomes
- World generation: Produce images, videos, synchronized sound, and action-conditioned rollouts from text, image, video, or action inputs
- Action modeling: Predict policy actions, inverse dynamics, and forward dynamics for robotics, camera motion, egocentric motion, and autonomous driving
The Cosmos 3 model family includes:
| Model | Size | Capability | |
💬 Discussion