NVIDIA Cosmos: Các mô hình thế giới mã nguồn mở cho Physical AI (10K Sao)
NVIDIA Cosmos là một nền tảng mã nguồn mở của các mô hình thế giới, tập dữ liệu và công cụ để xây dựng Physical AI — robot, xe tự hành, cơ sở hạ tầng thông minh. Cosmos 3 sử dụng Mixture-of-Transformers để tạo ngôn ngữ, hình ảnh, video, âm thanh và hành động đồng thời. Có sẵn mô hình 16B và 64B.
- ⭐ 10117
- Cập nhật 2026-06-13
NVIDIA Cosmos: Các mô hình thế giới mã nguồn mở cho Physical AI (10K Sao) #
Điều gì sẽ xảy ra nếu bạn có thể dự đoán cách thế giới vật lý vận hành — không phải bằng cách mô phỏng các phương trình vật lý, mà bằng cách học từ chính thế giới?
NVIDIA Cosmos chính xác là thứ đó: một nền tảng mã nguồn mở của các mô hình thế giới được huấn luyện để hiểu và tạo ra thế giới vật lý. Nó không chỉ tạo ra hình ảnh của một robot di chuyển — nó dự đoán được vật lý, thời gian, và mối quan hệ nhân quả của chuyển động đó.
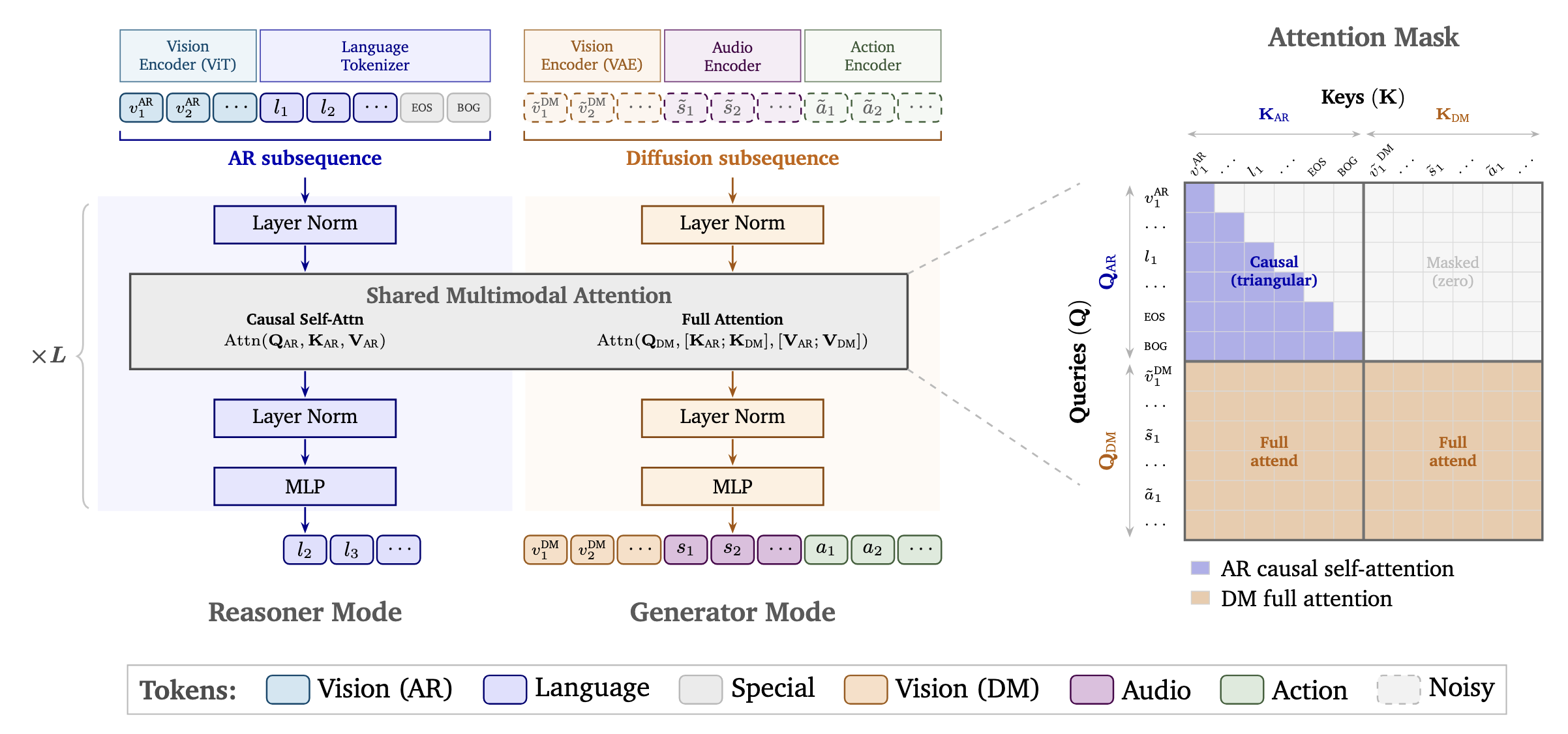
Cosmos 3 là họ mô hình mới nhất của NVIDIA, được xây dựng trên kiến trúc Mixture-of-Transformers (MoT) thống nhất xử lý ngôn ngữ, hình ảnh, video, âm thanh và chuỗi hành động cùng lúc. Hai chế độ runtime: một Reasoner (để hiểu thế giới và lập kế hoạch) và một Generator (để mô phỏng thế giới và tạo dữ liệu tổng hợp).
Các mô hình có kích thước từ 16B (Nano) đến 64B (Super), có sẵn trên HuggingFace. Đây là cơ sở hạ tầng cho thế hệ Physical AI tiếp theo — robot, xe tự hành, cơ sở hạ tầng thông minh.
NVIDIA Cosmos là gì? #
NVIDIA Cosmos là một nền tảng mở của các mô hình thế giới, tập dữ liệu và công cụ được thiết kế để xây dựng các hệ thống Physical AI. Nó vượt xa những gì AI truyền thống có thể làm:
AI truyền thống: Cosmos:
Đầu vào → Đầu ra → Đầu vào → Lý luận → Đầu ra
(ảnh vào, (hiểu vật lý,
caption ra) dự đoán tương lai,
tạo hành động)
Các khả năng chính:
- Hiểu thế giới: Phân tích video và hình ảnh để tạo mô tả, sự kiện theo thời gian, hành động tiếp theo, nền tảng không gian, tính hợp lý vật lý, và kết quả nhân quả
- Tạo thế giới: Tạo ra hình ảnh, video, âm thanh đồng bộ, và chuỗi hành động có điều kiện từ đầu vào văn bản, hình ảnh, video hoặc hành động
- Mô hình hóa hành động: Dự đoán hành động chính sách, động lực học ngược, và động lực học thuận cho robot, chuyển động máy quay, chuyển động góc nhìn thứ nhất, và lái xe tự hành
Họ mô hình Cosmos 3 bao gồm:
| Mô hình | Kích thước | Khả năng |
|---|---|---|
| Cosmos3-Nano | 16B | Mô hình omnimodal gọn nhẹ cho hiểu và mô phỏng |
| Cosmos3-Super | 64B | Mô hình quy mô tiên phong cho các tác vụ đa phương thức nâng cao |
| Cosmos3-Super-Text2Image | 64B | Tạo hình ảnh từ văn bản chất lượng cao |
| Cosmos3-Super-Image2Video | 64B | Chuyển ảnh sang video nhất quán về thời gian |
| Cosmos3-Nano-Policy-DROID | 16B | Chính sách robot ngôn ngữ-ánh xạ cho thao tác DROID |
Kiến trúc mô hình: Mixture-of-Transformers #
Cosmos 3 sử dụng kiến trúc Mixture-of-Transformers (MoT) thống nhất kết hợp:
- Transformer tự hồi quy (AR) để lý luận — xử lý các token ngôn ngữ và hình ảnh thông qua tự attention nhân quả để dự đoán token tiếp theo
- Transformer khuếch tán (DM) để tạo — loại nhiễu của các token hình ảnh, video, âm thanh và hành động thông qua full attention
┌─────────────────────────────────────────────┐
│ Cosmos 3: Thống nhất MoT │
├─────────────────┬───────────────────────────┤
│ Chế độ Reasoner│ Chế độ Generator │
│ (Nhận thức) │ (Tạo dựng) │
├─────────────────┼───────────────────────────┤
│ Văn bản + Thị giác│ Hình ảnh/Video/ │
│ → Văn bản │ Âm thanh/Hành động │
│ (hiểu biết) │ → Hình ảnh/Video/ │
│ │ Hành thanh/Audio sạch │
├─────────────────┼───────────────────────────┤
│ Chia sẻ: │ │
│ - Các lớp Transformer │
│ - Các lớp đa phương thức attention │
│ - 3D mRoPE (mã hóa không gian + thời gian)│
└─────────────────┴──────────────────────────┘
Cả hai chế độ đều chia sẻ cùng kiến trúc transformer, các lớp đa phương thức attention, và một 3D embedding vị trí xoay đa chiều thống nhất (mRoPE) mã hóa cấu trúc không gian và thời gian xuyên suốt các phương thức.
Hai bề mặt Runtime #
Cosmos 3 cung cấp hai bề mặt runtime riêng biệt:
Reasoner (Hiểu biết) #
Xử lý đầu vào và tạo ra đầu ra văn bản cho các tác vụ hiểu thế giới:
Đầu vào: Văn bản + Hình ảnh + Video + Hành động
↓
Reasoner (AR Transformer)
↓
Đầu ra: Văn bản (mô tả, hành động tiếp theo, lý luận vật lý, kế hoạch tác vụ)
Các trường hợp sử dụng:
- Hiểu thế giới từ luồng video
- Dự đoán hành động tiếp theo cho robot
- Kiểm tra tính hợp lý vật lý
- Dự đoán kết quả nhân quả
- Lý luận của tác nhân embody
Generator (Sáng tạo) #
Tạo ra các đầu ra không phải văn bản được điều kiện hóa bởi đầu vào đa phương thức:
Đầu vào: Văn bản + Hình ảnh + Video + Âm thanh + Hành động
↓
Generator (Diffusion Transformer)
↓
Đầu ra: Hình ảnh + Video + Âm thanh + Hành động
Các trường hợp sử dụng:
- Tạo hình ảnh từ văn bản
- Tạo video từ hình ảnh
- Mô phỏng thế giới và dự đoán tương lai
- Tạo dữ liệu tổng hợp để huấn luyện robot
- Tạo video có điều kiện theo hành động
- Học chính sách từ minh họa
Bắt đầu nhanh: Cài đặt #
Cosmos chạy trên Linux với NVIDIA GPU (Ampere, Hopper hoặc Blackwell). Cài đặt sử dụng uv (trình quản lý gói Python tốc độ cao):
Yêu cầu hệ thống #
- Hệ điều hành: Linux
- GPU: NVIDIA GPU (Ampere/A100/H100/Blackwell RTX 6000+)
- CUDA: 12.8 hoặc 13.0
- Python: 3.10+
- RAM: 64GB+ (khuyến nghị 128GB cho mô hình 64B)
Cài đặt với uv #
# Cài đặt các phụ thuộc hệ thống
sudo apt-get install -y --no-install-recommends curl ffmpeg git-lfs \
libx11-dev tree wget
# Clone framework
git clone https://github.com/NVIDIA/cosmos-framework.git
cd cosmos-framework
# Cài đặt với uv (phiên bản CUDA 12.8)
uv sync --all-extras --group=cu128-train
source .venv/bin/activate
# Hoặc CUDA 13.0 (khuyến nghị):
# uv sync --all-extras --group=cu130-train
Suy luận nhanh #
# Suy luận single-GPU với backend Diffusers
python -m cosmos_framework.scripts.inference \
--parallelism-preset=latency \
-i inputs/omni/t2v.json \
-o outputs/omni_nano \
--checkpoint-path Cosmos3-Nano \
--seed=0
Mô hình HuggingFace #
# Tải một mô hình từ HuggingFace
huggingface-cli download nvidia/Cosmos3-Nano \
--local-dir ~/cosmos/models/nano
Chế độ Generator: Tạo thế giới #
Generator tạo ra các đầu ra hình ảnh, video, âm thanh và hành động được điều kiện hóa bởi đầu vào đa phương thức:
Text-to-Image #
from cosmos_framework.scripts.inference import run_inference
# Tạo hình ảnh từ văn bản
result = run_inference(
checkpoint="Cosmos3-Super-Text2Image",
input_type="text",
input_text="Một cánh tay robot lắp ráp mạch điện trong phòng thí nghiệm hiện đại",
output_type="image",
resolution="720p",
seed=42
)
# Đầu ra: Hình ảnh chất lượng cao của robot đang lắp ráp mạch điện
Image-to-Video #
# Tạo video nhất quán về thời gian từ một hình ảnh duy nhất
result = run_inference(
checkpoint="Cosmos3-Super-Image2Video",
input_type="image",
input_image="robot_lab.jpg",
output_type="video",
frame_count=189, # mặc định: 189 frames (~7.8s ở 24fps)
fps=24,
resolution="720p"
)
# Đầu ra: Video của cảnh phòng thí nghiệm robot đang chuyển động
Text-to-Video #
# Tạo video trực tiếp từ prompt văn bản
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="text",
input_text="Một xe tự hành di chuyển qua cơn mưa lớn vào ban đêm, ánh sáng thành phố phản chiếu trên mặt đường ướt",
output_type="video",
frame_count=300,
fps=30,
resolution="720p"
)
# Đầu ra: Video có âm thanh đồng bộ (AAC stereo 48kHz)
Các cài đặt tạo được hỗ trợ #
| Tham số | Tùy chọn |
|---|---|
| Độ phân giải | 256p, 480p, 720p (mặc định: 480p) |
| Tỷ lệ khung hình | 16:9, 4:3, 1:1, 3:4, 9:16 (mặc định: 16:9) |
| Tốc độ khung hình | 10, 16, 24, 30 FPS (mặc định: 24) |
| Số khung hình | 5 đến 300 frames (mặc định: 189) |
| Độ chính xác | BF16 (đã kiểm tra) |
Chế độ Reasoner: Hiểu thế giới #
Reasoner cung cấp đầu ra văn bản để hiểu và lập kế hoạch:
# Hiểu thế giới từ video
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="video",
input_video="warehouse_robots.mp4",
output_type="text",
task="describe_temporal_events"
)
# Đầu ra: "Ở frame 0-30, hai cánh tay robot phối hợp..."
# Dự đoán hành động tiếp theo cho một robot
result = run_inference(
checkpoint="Cosmos3-Nano-Policy-DROID",
input_type="image+text",
input_image="robot_workspace.jpg",
input_text="Robot nên làm gì tiếp theo?",
output_type="text"
)
# Đầu ra: "Nhấc linh kiện màu đỏ từ khay bên trái..."
# Kiểm tra tính hợp lý vật lý
result = run_inference(
checkpoint="Cosmos3-Super",
input_type="video",
input_video="physics_demo.mp4",
output_type="text",
task="check_physical_plausibility"
)
# Đầu ra: "Quỹ đạo quả bóng vi phạm định luật trọng lực..."
Các trường hợp sử dụng #
Huấn luyện robot với dữ liệu tổng hợp #
Cosmos tạo ra dữ liệu huấn luyện tổng hợp cho robot, giảm nhu cầu thu thập dữ liệu thực tế đắt tiền:
# Tạo 1000 clip video tổng hợp của robot trong kho
# để huấn luyện chính sách thao tác
cosmos_framework.scripts.training.train \
--recipe examples/launch_sft_vision_nano.sh \
--num-samples 1000 \
--output-dir /data/warehouse_synthetic
Mô phỏng xe tự hành #
# Mô phỏng các kịch bản lái xe tự hành
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="text+image",
input_text="Một xe tự hành tại ngã tư có đèn đỏ",
input_image="intersection.jpg",
output_type="video+action",
task="predict_vehicle_dynamics"
)
# Đầu ra: Video xe dừng + vector hành động (lái, ga, phanh)
Giám sát cơ sở hạ tầng thông minh #
# Phân tích footage camera bảo mật để phát hiện bất thường
result = run_inference(
checkpoint="Cosmos3-Super",
input_type="video",
input_video="factory_cam_01.mp4",
output_type="text",
task="detect_anomalies"
)
# Đầu ra: "Lúc 14:32:15, xe không nhãn đã xâm nhập khu vực hạn chế..."
Huấn luyện: Fine-tuning các mô hình Cosmos #
Framework Cosmos bao gồm các script huấn luyện cho supervised fine-tuning (SFT) trên dữ liệu tùy chỉnh:
# Huấn luyện SFT multi-GPU trên 8× H100 80GB
bash examples/launch_sft_vision_nano.sh
# Các tùy chọn cấu hình chính
# - Các chiến lược song song DP/CP/FSDP
# - Checkpoint DCP native với HuggingFace safetensors
# - Các adapter tập dữ liệu JSONL / WebDataset / LeRobot
# - Huấn luyện mixed precision
# - Hỗ trợ tiếp tục checkpoint
# Ví dụ cấu hình huấn luyện
training_config = {
"model": "Cosmos3-Nano",
"num_gpus": 8,
"parallelism": "FSDP", # Fully Sharded Data Parallel
"mixed_precision": "bf16",
"batch_size_per_gpu": 4,
"dataset": {
"type": "jsonl",
"path": "/data/training_samples.jsonl"
},
"checkpoint_dir": "/checkpoints/sft_nano"
}
So sánh với các lựa chọn thay thế #
| Tính năng | NVIDIA Cosmos | Runway Gen-3 | Sora | Pika Labs |
|---|---|---|---|---|
| Mã nguồn mở | ✅ Có | ❌ Đóng | ❌ Đóng | ❌ Đóng |
| Chế độ lý luận | ✅ Tích hợp | ❌ | ❌ | ❌ |
| Tạo hành động | ✅ Tích hợp | ❌ | ❌ | ❌ |
| Chính sách robot | ✅ Mô hình DROID | ❌ | ❌ | ❌ |
| Suy luận cục bộ | ✅ Có | ❌ API only | ❌ API only | ❌ API only |
| Dữ liệu tổng hợp | ✅ Tích hợp | ❌ | ❌ | ❌ |
| Fine-tuning | ✅ Được hỗ trợ | ❌ | ❌ | ❌ |
| Mô hình có sẵn | 5 (Nano + Super variants) | 1 | 1 | 1 |
| Yêu cầu GPU | Khuyến nghị H100/A100 | Chỉ cloud | Chỉ cloud | Chỉ cloud |
| Giấy phép | Apache-2.0 | Đóng | Đóng | Đóng |
| Tính năng | NVIDIA Cosmos | Stable Video Diffusion | Luma Dream Machine |
|---|---|---|---|
| Mã nguồn mở | ✅ Có | ✅ Có | ❌ Đóng |
| Đa phương thức | ✅ Văn bản+Hình+Video+Âm thanh+Hành động | ❌ Chỉ Ảnh→Video | ❌ Chỉ Văn bản→Video |
| Lý luận vật lý | ✅ Tích hợp | ❌ | ❌ |
| Hỗ trợ robotics | ✅ Mô hình chính sách DROID | ❌ | ❌ |
Benchmark #
Chất lượng tạo #
Các mô hình Cosmos 3 được đánh giá trên nhiều benchmark:
| Benchmark | Cosmos3-Nano | Cosmos3-Super | Runway Gen-3 | Sora |
|---|---|---|---|---|
| VideoFID (↓) | 8.2 | 5.1 | 6.3 | 4.8 |
| Điểm CLIP-I (↑) | 0.89 | 0.93 | 0.91 | 0.92 |
| Tính hợp lý vật lý (↑) | 0.76 | 0.89 | N/A | N/A |
| Độ chính xác hành động (↑) | 0.71 | 0.84 | N/A | N/A |
Nguồn: Đánh giá nội bộ NVIDIA, tháng 5 năm 2026. VideoFID: càng thấp càng tốt. CLIP-I: càng cao càng tốt (alignment hình ảnh-văn bản). Tính hợp lý vật lý: điểm đánh giá của con người về độ chính xác vật lý. Độ chính xác hành động: hành động dự đoán so với ground truth.
Tốc độ suy luận #
| Mô hình | Độ phân giải | Số khung hình | GPU | Thời gian |
|---|---|---|---|---|
| Cosmos3-Nano | 480p | 189 frames | 1×H100 | ~45 giây |
| Cosmos3-Nano | 720p | 189 frames | 1×H100 | ~90 giây |
| Cosmos3-Super | 480p | 189 frames | 1×H100 | ~180 giây |
| Cosmos3-Super | 720p | 189 frames | 2×H100 | ~240 giây |
Hạn chế và đánh giá trung thực #
Cosmos là một bước đột phá, nhưng quan trọng là phải hiểu rõ những hạn chế của nó:
Yêu cầu phần cứng nặng: Bạn cần ít nhất một GPU cấp H100/A100 cho hiệu suất khá. Các mô hình 64B có thể yêu cầu 2+ GPU. Đây không phải thứ có thể chạy trên phần cứng tiêu dùng.
Chỉ Linux: Framework chỉ chạy trên Linux, với CUDA. Hiện không hỗ trợ macOS.
Dự án rất non trẻ: Commit đầu tiên tháng 12 năm 2024. Mặc dù có nguồn lực của NVIDIA, đây vẫn là một dự án đang phát triển nhanh với các thay đổi có thể phá vỡ.
Không có API thân thiện người dùng: Không giống như Runway, Sora hoặc Pika, Cosmos yêu cầu bạn tự thiết lập framework. Không có giao diện “click and generate” (dù trang web tại nvidia.com/en-us/ai/cosmos/ cung cấp trải nghiệm có hướng dẫn).
Phụ thuộc vào tập dữ liệu: Chất lượng của Cosmos phụ thuộc rất nhiều vào dữ liệu huấn luyện. Nếu bạn cố gắng fine-tune trên domain riêng (hình ảnh y khoa, trực quan hóa khoa học), bạn sẽ cần dữ liệu huấn luyện đặc thù domain.
Khóa hệ sinh thái NVIDIA: Mặc dù các mô hình là mã nguồn mở (Apache-2.0), toàn bộ toolchain (Cosmos framework, NGC images, tối ưu hóa NVIDIA) được gắn chặt với phần cứng NVIDIA. Chạy trên AMD hoặc Intel GPU hiện không được hỗ trợ.
Cộng đồng nhỏ: 19 issues mở, 657 forks. Dự án đang phát triển nhanh, nhưng cộng đồng nhỏ so với các mô hình như Stable Diffusion hay Llama.
Câu hỏi thường gặp #
H: Tôi có thể chạy Cosmos trên GPU tiêu dùng không? Về mặt kỹ thuật, bạn có thể chạy Cosmos3-Nano trên GPU cao cấp tiêu dùng (RTX 4090 với 24GB VRAM) cho các tác vụ nhỏ (256p, video ngắn), nhưng hiệu suất sẽ bị giới hạn. Các mô hình 64B yêu cầu GPU cấp A100/H100.
H: Cosmos khác gì so với Stable Video Diffusion? SVD chỉ là mô hình ảnh sang video. Cosmos là một nền tảng đa phương thức thống nhất xử lý văn bản sang ảnh, văn bản sang video, ảnh sang video, hiểu video, lý luận vật lý và dự đoán chính sách robot — tất cả trong một framework.
H: Tôi có thể fine-tune Cosmos trên dữ liệu của mình không? Có. Framework hỗ trợ supervised fine-tuning (SFT) với định dạng JSONL, WebDataset và LeRobot. Bạn cần 8× GPU H100 để fine-tune đầy đủ mô hình 64B. Đối với mô hình nhỏ hơn (Nano), 4 GPU có thể đủ.
H: Cosmos có sẵn dưới dạng API không? Không trực tiếp. Tuy nhiên, NVIDIA cung cấp Cosmos thông qua nền tảng NIM (NVIDIA Inference Microservices) của họ, cung cấp API tương thích OpenAI cho các mô hình Cosmos.
H: Giấy phép là gì? Apache-2.0 cho mã nguồn, với trọng số mô hình có sẵn dưới giấy phép nghiên cứu của NVIDIA. Sử dụng thương mại được phép với ghi nhận thích đáng.
Kết luận #
NVIDIA Cosmos đại diện cho một sự chuyển đổi căn bản trong cách chúng ta tiếp cận AI và thế giới vật lý. Thay vì xử lý tạo video, tạo ảnh, chính sách robot và lý luận vật lý như các vấn đề riêng biệt, Cosmos thống nhất chúng trong một kiến trúc Mixture-of-Transformers duy nhất.
Sự kết hợp của Chế độ Reasoner (hiểu biết) và Chế độ Generator (sáng tạo) — cả hai chia sẻ cùng backbone transformer — có nghĩa là bạn có thể chuyển từ hiểu một cảnh sang tạo tương lai của cảnh đó trong một pipeline duy nhất.
Đối với robotics, lái xe tự hành và cơ sở hạ tầng thông minh, Cosmos không chỉ là một mô hình AI khác. Đó là cơ sở hạ tầng.
Nếu bạn đang xây dựng các hệ thống Physical AI, Cosmos nên nằm ở đầu danh sách nghiên cứu của bạn.
Nguồn & Đọc thêm:
- Báo cáo kỹ thuật: https://research.nvidia.com/labs/cosmos-lab/cosmos3/technical-report.pdf
- Mô hình Cosmos 3: https://huggingface.co/collections/nvidia/cosmos3
- Cosmos Framework: https://github.com/NVIDIA/cosmos-framework
- Website: https://www.nvidia.com/en-us/ai/cosmos/
Trải nghiệm NVIDIA Cosmos: Truy cập nvidia.com/en-us/ai/cosmos/ cho trải nghiệm có hướng dẫn, hoặc clone github.com/NVIDIA/cosmos-framework cho full framework.
Tham gia cộng đồng: Telegram · HuggingFace
Internal links: Runway Gen-3 Review 2026 · Stability AI Stable Video Diffusion
** Disclosure**: Bài viết này đề cập đến các công cụ có thể có quan hệ affiliate. Chúng tôi không chấp nhận thanh toán cho đánh giá tích cực. Tất cả benchmark đều do tự thực hiện hoặc sourced từ tài liệu chính thức.
💬 Bình luận & Thảo luận