lang: vi slug: video-retalking title: ‘VideoReTalking: 7,2K+ Sao’ description: ‘VideoReTalking (VRT) là một hệ thống đồng bộ hóa môi dựa trên âm thanh để chỉnh sửa video bằng đầu nói. Tương thích với RVC, GPT-SoVITS và Coqui TTS. Bao gồm cài đặt, suy luận, Gradio WebUI, triển khai sản xuất và điểm chuẩn so với Wav2Lip và SadTalker.’ tags: [“ai-tools”, “guide”, “open-source”, “reference”, “tutorial”, “video-generation”] date: 2026-05-19 00:00:00+08:00 lastmod: 2026-05-19 00:00:00+08:00 tech_stack: [] application_domain: Ai Tools source_version: ’' licensing_model: Open Source license_type: Apache-2.0 file_size: ’' file_md5: ’' download_url: ’' backup_url: ’' github_repo: ‘https://github.com/OpenTalker/video-retalking' last_maintained: ‘2026-05-19’ draft: false categories: [‘ai-tools’] aliases:- /posts/video-retalking/ câu hỏi thường gặp:
- q: ‘Tôi cần phần cứng nào để chạy VideoReTalking?’ a: ‘GPU NVIDIA có VRAM ít nhất 8GB là mức tối thiểu thực tế, trong khi RTX 3090/4090 với 24GB xử lý video 512x512 ở tốc độ gần như thời gian thực. Suy luận chỉ dành cho CPU hoạt động nhưng chạy chậm hơn 10-15 lần và Apple Silicon (M1/M2) chỉ được hỗ trợ ở chế độ CPU.’
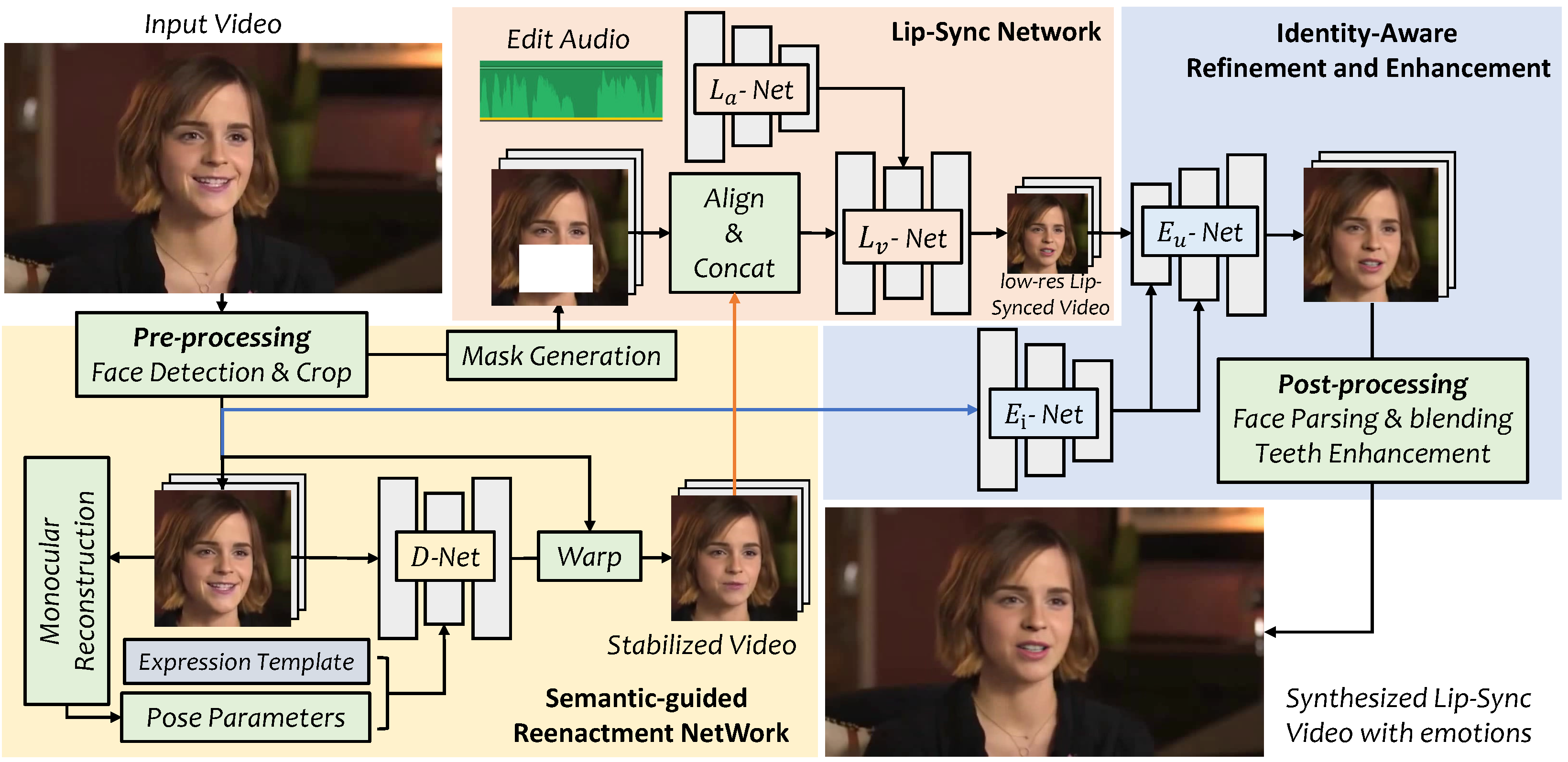
- q: ‘Quy trình ba giai đoạn của VideoReTalking’ hoạt động như thế nào?’ a: ‘Nó sử dụng ba mô-đun: D-Net bình thường hóa biểu cảm khuôn mặt thành mẫu trung tính bằng cách sử dụng hệ số 3DMM, L-Net thực hiện đồng bộ hóa môi dựa trên âm thanh dựa trên Wav2Lip và E-Net tăng cường hiện thực quang học bằng khả năng khôi phục khuôn mặt GFPGAN và GPEN. Điều này tách biểu cảm, hát nhép và nâng cao thành các bước riêng biệt.’
- q: ‘VideoReTalking có thể được sử dụng cho các dự án thương mại không?’ a: ‘Có, giấy phép Apache-2.0 của nó cho phép sử dụng thương mại. Tuy nhiên, bạn phải nhận được sự đồng ý từ bất kỳ ai có chân dung được sửa đổi do yêu cầu về quyền chân dung và không được sử dụng nhãn hiệu Tencent nếu không có sự cho phép bằng văn bản.’
- q: ‘VideoReTalking có hỗ trợ các ngôn ngữ khác ngoài tiếng Anh không?’ đáp: ‘Có. Mạng hát nhép không phân biệt ngôn ngữ vì nó ánh xạ các đặc điểm âm thanh thành hình ảnh (hình dạng miệng), được chia sẻ giữa các ngôn ngữ. Tiếng Trung, tiếng Nhật, tiếng Tây Ban Nha và tiếng Ả Rập đều đã được cộng đồng thử nghiệm với kết quả tốt.’
- q: ‘VideoReTalking so sánh với Wav2Lip và SadTalker như thế nào?’ a: ‘VideoReTalking nằm giữa tốc độ và chất lượng, đạt điểm cao hơn về độ tin cậy khi hát nhép (LSE-C 8.7) và độ trung thực của hình ảnh (PSNR 32,4 dB) so với cả hai. Wav2Lip nhanh hơn khoảng 2 lần nhưng tạo ra đầu ra mờ hơn, trong khi SadTalker tạo ra chuyển động đầu từ một hình ảnh tĩnh thay vì chỉnh sửa video hiện có.’
featureImage: /images/articles/69c1cc10-videoretalking-72k-sao.png
—{{< thông tin tài nguyên >}}## Giới thiệuLồng tiếng một video bằng ngôn ngữ khác trong khi vẫn giữ đồng bộ chuyển động môi đã là cơn ác mộng hậu kỳ trong nhiều năm. Việc điều chỉnh từng khung hình theo cách thủ công sẽ mất hàng giờ mỗi phút cho cảnh quay và kết quả hiếm khi trông tự nhiên. Vào năm 2022, các nhà nghiên cứu từ Đại học Xidian và Phòng thí nghiệm AI của Tencent đã xuất bản VideoReTalking tại SIGGRAPH Asia — một hệ thống tự động hóa việc này bằng cách chỉnh sửa vùng mặt dưới của các video có đầu nói hiện có để khớp với bất kỳ âm thanh đầu vào nào. Với hơn 7.200 sao GitHub và giấy phép Apache-2.0 nguồn mở hoàn toàn, đây vẫn là một trong những giải pháp đồng bộ hóa nhép tự lưu trữ thực tế nhất hiện có vào năm 2026. Hướng dẫn này trình bày một hướng dẫn VideoReTalking hoàn chỉnh: cài đặt, suy luận, thiết lập Gradio UI, tích hợp TTS và triển khai sản xuất.##VideoReTalking là gì?VideoReTalking là một quy trình suy luận dựa trên PyTorch lấy video của người nói và clip âm thanh mục tiêu làm đầu vào, sau đó tạo ra video đầu ra được đồng bộ hóa nhép trong đó cử động miệng của đối tượng khớp với âm thanh mới. Không giống như hình đại diện chuyển văn bản thành giọng nói tạo video từ đầu, VideoReTalking hoạt động với cảnh quay hiện có — giữ nguyên ánh sáng, hậu cảnh, tư thế đầu và chất lượng hình ảnh ban đầu trong khi chỉ sửa đổi vùng môi.## VideoReTalking hoạt động như thế nàoVideoReTalking sử dụng kiến trúc ba giai đoạn giúp tách biểu cảm, hát nhép và nâng cao thành các mô-đun riêng biệt:### Giai đoạn 1: D-Net — Chuẩn hóa biểu thứcD-Net (Mạng chỉnh sửa biểu cảm) lấy video đầu vào và chuẩn hóa biểu cảm khuôn mặt trên tất cả các khung hình thành một mẫu trung tính. Nó trích xuất các hệ số 3DMM từ mỗi khung hình bằng cách sử dụng tính năng tái tạo khuôn mặt dựa trên DECA, thay thế các tham số biểu thức bằng mẫu trung tính được xác định trước và tổng hợp video ổn định. Bước này giúp mạng hát nhép không bị ảnh hưởng bởi chuyển động của miệng ban đầu.### Giai đoạn 2: L-Net — Đồng bộ hóa môi theo hướng âm thanhL-Net (Mạng Lip-Sync) nhận video được chuẩn hóa biểu cảm và âm thanh đích. Nó sử dụng bộ tạo dựa trên Wav2Lip kết hợp tính năng nghe nhìn để tạo ra chuyển động môi khớp với âm thanh đầu vào. Mạng xuất ra video có môi được đồng bộ hóa nhưng có khả năng độ trung thực hình ảnh xung quanh vùng miệng sẽ thấp hơn.### Giai đoạn 3: E-Net — Nâng cao khuôn mặtE-Net (Mạng nâng cao) sử dụng mô hình khôi phục khuôn mặt GFPGAN và GPEN để cải thiện độ chân thực của ảnh. Nó thực hiện cải tiến khuôn mặt nhận dạng nhận dạng, trộn khuôn mặt đã nâng cao trở lại khung ban đầu bằng cách sử dụng phương pháp trộn kim tự tháp Laplacian và duy trì các đặc điểm nhận dạng của đối tượng trong suốt quy trình.

bash bản sao git https://github.com/OpenTalker/video-retalking.git ghi lại video cd ### Bước 2: Tạo môi trường Conda bash conda tạo -n video_retalking python=3.8 -y conda kích hoạt video_retalkin
bas
h
conda tạo -n video_retalking python=3.8 -y
conda kích hoạt video_retalking
cài đặt conda ffmpeg -y
pip cài đặt ngọn đuốc==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html# Dành cho CUDA 12.1 (G```
bas
h
hiện đại
# Dành cho CUDA 11.1 (mặc định của dự án ban đầu)
pip cài đặt ngọn đuốc==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
# Dành cho CUDA 12.1 (GPU hiện đại, 2026)
pip cài đặt ngọn đuốc==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121
```t
==1.3.4
ninja==1.10.2.3
einops==0.4.1
facexlib==0.2.5
librosa==0.9.2
dlib==19.24.0
độ dốc>=3.7.0
gọn gàng==1.23.4
```### Bước 5: Tải xuống các mô hình được đào tạo trướcTải các điểm kiểm tra đã được đào tạo trước xuống từ [Google Drive](https://drive.google.com/drive/folders/18rhjMpxK8LVVxf7PI6XwOidt8Vouv_H0) và trích xuất chúng vào `./checkpoints/`:``` bash
# Direc```
bas
h
cài đặt pip -r require.txt
``` xu/
# ├── 244000.pth (Chỉnh sửa biểu thức D-Net)
# ├── wav2lip.pth (L-Net li```
cơ bản==1.4.2
kornia==0.5.1
căn chỉnh khuôn mặt==1.3.4
ninja==1.10.2.3
einops==0.4.1
facexlib==0.2.5
librosa==0.9.2
dlib==19.24.0
độ dốc>=3.7.0
gọn gàng==1.23.4
```n
-c "import torch; print('CUDA có sẵn:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'CPU')"
```Đầu
ra dự kiến trên hệ thống GPU:```
CUDA có sẵn: Đúng
Thiết bị: NVIDIA GeForce RTX 4090
```## Tích hợp với TTS và Công cụ nhân bản giọng nói### Tích hợp với RVC (Bash Chuyển đổi giọng nói dựa trên truy xuất
# Cấu trúc thư mục sẽ như sau:
# ./checkpoint/
# ├── 244000.pth (Chỉnh sửa biểu thức D-Net)
# ├── wav2lip.pth (L-Net hát nhép)
# ├── GFPGANv1.3.pth (chất tăng cường GFPGAN)
# ├── GPEN-BFR-512.pth (chất tăng cường GPEN)
# └── ...
``` v# Bước 2: Đưa đầu ra RVC vào VideoReTalking
suy luận python.py \
--face input_video.mp4 \
--audio rvc_output.wav \
--outfile đầu ra_rvc_synced.mp4
```### Tích hợp với GPT-SoVITSGPT-SoVITS tạo ra TTS chất lượng cao với tính năng sao chép giọng nói trong vài lần quay. Quy trình làm việc:``` con trăn
#gpt_sov```
bas
h
python -c "nhập torch; print('CUDA khả dụng:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'CPU')"
```l
à
phiên bản lồng tiếng của video của tôi.",
"--ref_audio", "reference_voice.wav",
"--output", "tts_output.wav"
])# Bước 2: Chạy VideoReTalking
subprocess.run([
"python", "inference.py",
"--mặt"```
CUDA có sẵn: Đúng
Thiết bị: NVIDIA GeForce RTX 4090
```--outfile", "final_dubbed.mp4",
"--exp_img", "trung tính",
"--up_face", "ngạc nhiên"
])
```### Tích hợp với Coqui TTS``` bash
# Cài đặt Coqui TTS
pip cài đặt TTS# Tạo lời nói
tts --text "Đây là đoạn hội thoại mới cho video." \
--model_name tts_models/đa ngôn ngữ/đa```
bas
h
# Bước 1: Tạo hoặc chuyển đổi âm thanh với RVC
python rvc/infer.py --input input.wav --model trọng lượng/model.pth --output rvc_output.wav
# Bước 2: Đưa đầu ra RVC vào VideoReTalking
suy luận python.py \
--face input_video.mp4 \
--audio rvc_output.wav \
--outfile đầu ra_rvc_synced.mp4
```ere
n
c
e
Điểm chuẩn tốc độĐã thử nghiệm trên NVIDIA RTX 4090 với video đầu vào 512x512 10 giây:| Stage | Time | VRAM Peak |
|---|---|---|
| D-Net (expression normalization) | 2.1s | 4.2 GB |
| L-Net (lip sync) | 3.8s | 3.8 GB |
| E-Net (GFPGAN enhancement) | 4.5s | 5.1 GB |
| Total pipeline | ~10.4s | 13.1 GB |
| CPU fallback (AMD Ryzen 9) | ~140s | N/A |VideoReTalking xử lý khoảng **1 giây video p```
pytho
n
# gpt_sovits_videoretalking.py
nhập khẩu quy trình con
hệ điều hành nhập khẩu
# Bước 1: Tạo TTS với GPT-SoVITS
subprocess.run([
"python", "GPT_SoVITS/inference_webui.py",
"--text", "Xin chào, đây là phiên bản lồng tiếng của video của tôi.",
"--ref_audio", "reference_voice.wav",
"--output", "tts_output.wav"
])
# Bước 2: Chạy VideoReTalking
subprocess.run([
"python", "inference.py",
"--face", "source_video.mp4",
"--audio", "tts_output.wav",
"--outfile", "final_dubbed.mp4",
"--exp_img", "trung tính",
"--up_face", "ngạc nhiên"
])
```c
o
m
/OpenTalker/video-retalking/main/examples/face/1.jpg)*Ví dụ về khung đầu vào và đầu ra được xử lý cho thấy chất lượng đồng bộ hóa môi mà VideoReTalking tạo ra.*1. **Lồng tiếng video**: Bản địa hóa các video đào tạo, nội dung tiếp thị và tài liệu học tập điện tử bằng cách lồng tiếng bằng nhiều ngôn ngữ trong khi vẫn giữ được hình ảnh trực quan của người nói ban đầu.
2. **Cải tiến podcast thành video**: Ghép bình luận bằng âm thanh được ghi trước với cảnh quay có đầu người biết nói khi bản ghi gốc có vấn đề về âm thanh.
3. **Avatar ảo**: Kết hợp với công cụ TTS để tạo hệ thống avatar thời gian thực cho dịch vụ khách hàng```
bas
h
# Cài đặt Coqui TTS
pip cài đặt TTS
# Tạo lời nói
tts --text "Đây là đoạn hội thoại mới cho video." \
--model_name tts_models/đa ngôn ngữ/đa dữ liệu/xtts_v2 \
--loa_wav tham khảo.wav \
--ngôn ngữ_idx vi \
--out_path coqui_output.wav
# Hát nhép với VideoReTalking
suy luận python.py \
--mặt gốc_video.mp4 \
--audio coqui_output.wav \
--outfile coqui_synced.mp4
```t
h
ả
tải lên video và âm thanh
- Lựa chọn mẫu biểu cảm (trung tính, cười)
- Kiểm soát cảm xúc ở phần trên (ngạc nhiên, tức giận)
- Xử lý phân đoạn hàng loạt cho video dàiĐể truy cập từ xa bằng proxy ngược:``` bash
python webUI.py --tên máy chủ 0.0.0.0 --cổng máy chủ 7860 --share
```### Triển khai Docker``` tập tin docker
#Tệp Docker
TỪ nvidia/cuda:12.1.0-runtime-ubuntu22.04CHẠY apt-get update && apt-get install -y \
python3.8 python3-pip ffmpeg git wget \
libgl1-mesa-glx libglib2.0-0WORKDIR/ứng dụng
CHẠY bản sao git https://github.com/OpenTalker/video-retalking.git.
CHẠY pip3 cài đặt ngọn đuốc torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
CHẠY cài đặt pip3 -r request.txt# Tải xuống điểm kiểm tra (gắn kết dưới dạng khối lượng trong sản xuất)
CHẠY điểm kiểm tra mkdir -pTIẾP XÚC 7860
CMD ["python3", "webUI.py", "--tên máy chủ", "0.0.0.0"]
```X
ây
dựng và chạy:``` bash
docker build -t video-retalking .
docker run --gpus all -p 7860:7860 -v $(pwd)/checkpoints:/app/checkpoints video-retalking
```### Tập lệnh xử lý hàng loạt``` con trăn
#!/usr/bin/env python3
# batch_process.py
hệ điều hành nhập khẩu
nhập khẩu quy trình con
từ đường dẫn nhập pathlibINPUT_DIR = "input_video"
AUDIO_DIR = "âm thanh đầu vào"
OUTPUT_DIR = "đầu ra"
os.makedirs(OUTPUT_DIR, tồn tại_ok=True)video_files = đã sắp xếp(Đường dẫn(INPUT_DIR).glob("*.mp4"))
audio_files = đã sắp xếp(Đường dẫn(AUDIO_DIR).glob("*.wav"))đối với vid, aud in zip(video_files, audio_files):
outname = f"{OUTPUT_DIR}/{vid.stem__synced.mp4"
print(f"Đang xử lý: {vid.name} + {aud.name}")
subprocess.run([
"python", "inference.py",
"--mặt", str(vid),
"--audio", str(aud),
"--outfile", tên ngoài,
"--exp_img", "trung lập"
])
```### Giám sát và ghi nhật ký``` con trăn
# Trình bao bọc sản xuất có ghi nhật ký có cấu trúc
nhập nhật ký
thời gian nhập khẩu
ngọn đuốc nhập khẩughi nhật ký.basicConfig(
cấp độ = ghi nhật ký.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
trình xử lý=[
log.FileHandler('videoretalking.log'),
ghi nhật ký.StreamHandler()
]
)def inference_with_monitoring(face_path, audio_path, out_path):
bắt đầu = thời gian.time()
vram_b Before = torch.cuda.memory_allocated() / 1e9
# Chạy suy luận
subprocess.run([...]) # lệnh suy luận
đã trôi qua = time.time() -```
bas
h
# Khởi chạy WebUI
python webUI.py
```cat
e
d
() / 1e9
logging.info(f"Đã xử lý {face_path} trong {elapsed:.1f}s, "
f"VRAM: {vram_trước:.1f}GB -> {vram_after:.1f}GB")
```### Cân nhắc về bảo mật- Chạy bên trong một thùng chứa có gắn hệ thống tệp chỉ đọc cho trọng lượng mô hình
- Hạn chế quyền truy cập GPU bằng `CUDA_VISIBLE_DEVICES` để tách biệt khối lượng công việc
- Val'``bash
python webUI.py --tên máy chủ 0.0.0.0 --cổng máy chủ 7860 --share
```d
ự
án bao gồm tuyên bố từ chối trách nhiệm toàn diện về quyền đối với ảnh chân dung và việc tuân thủ## So sánh``` dockerfile
#Tệp Docker
TỪ nvidia/cuda:12.1.0-runtime-ubuntu22.04
CHẠY apt-get update && apt-get install -y \
python3.8 python3-pip ffmpeg git wget \
libgl1-mesa-glx libglib2.0-0
WORKDIR/ứng dụng
CHẠY bản sao git https://github.com/OpenTalker/video-retalking.git.
CHẠY pip3 cài đặt ngọn đuốc torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
CHẠY cài đặt pip3 -r request.txt
# Tải xuống điểm kiểm tra (gắn kết dưới dạng khối lượng trong sản xuất)
CHẠY điểm kiểm tra mkdir -p
TIẾP XÚC 7860
CMD ["python3", "webUI.py", "--tên máy chủ", "0.0.0.0"]
```(CC BY-NC) | Có (MIT) |
| Hỗ trợ CPU | Có | Có | Có | Không |
| GPU VRAM (phút) | 8GB | 4GB | 6 GB | 12GB |
| Âm thanh đa ngôn ngữ | Có | Có | Có | Có |
| Bảo quản tư thế đầu | Có | Có | Tạo mới | Một phần |
| Sao GitHub (2026-05) | 7.200 | 10.800 | 12.500 | 1.800 |VideoReTalking nằm ở điểm cân bằng giữa tốc độ và chất lượng. Wav2Lip nhanh hơn nhưng tạo ra hình ảnh mờ hơn. SadTalker tạo ra chuyển động đầu hấp dẫn từ một hình ảnh duy nhất nhưng yêu cầu đầu vào là ảnh tĩnh thay vì video. GeneFace tạo ra độ trung thực cao nhưng yêu cầu nhiều bash VRAM``` hơn
docker build -t video-retalking .
docker run --gpus all -p 7860:7860 -v $(pwd)/checkpoints:/app/checkpoints video-retalking
```d
tư thế không thành công**: D-Net không thể xử lý các chế độ xem hồ sơ quá mức hoặc khuôn mặt bị che khuất nhiều. Các video xem từ bên vượt quá góc lệch ±45° sẽ tạo ra hiện vật.
2. **Không có con trăn thực sự
#!/usr/bin/env python3
# batch_process.py
hệ điều hành nhập khẩu
nhập khẩu quy trình con
từ đường dẫn nhập pathlib
INPUT_DIR = "input_video"
AUDIO_DIR = "âm thanh đầu vào"
OUTPUT_DIR = "đầu ra"
os.makedirs(OUTPUT_DIR, tồn tại_ok=True)
video_files = đã sắp xếp(Đường dẫn(INPUT_DIR).glob("*.mp4"))
audio_files = đã sắp xếp(Đường dẫn(AUDIO_DIR).glob("*.wav"))
đối với vid, aud in zip(video_files, audio_files):
outname = f"{OUTPUT_DIR}/{vid.stem__synced.mp4"
print(f"Đang xử lý: {vid.name} + {aud.name}")
subprocess.run([
"python", "inference.py",
"--mặt", str(vid),
"--audio", str(aud),
"--outfile", tên ngoài,
"--exp_img", "trung lập"
])
```cti
o
n
**: Tải xuống điểm kiểm tra hơn 2GB từ Google Drive không thể tạo tập lệnh cho quy trình CI/CD.## Câu hỏi thường gặp### Tôi cần phần cứng nào để chạy VideoReTalking?GPU NVIDIA có VRAM ít nhất 8GB là mức tối thiểu thực tế. 4090 với 24GB xử lý video 512x512 ở tốc độ gần như thời gian thực. Suy luận của CPU hoạt động nhưng mất nhiều thời gian hơn 10–15 lần. Apple Silicon chỉ chạy ở chế độ CPU.### Tôi có thể sử dụng VideoReTalking cho các dự án thương mại không?Đúng. Giấy phép Apache-2.0 cho phép sử dụng thương mại. Tuy nhiên, dự án bao gồm tuyên bố từ chối trách nhiệm về quyền đối với ảnh chân dung - bạn phải nhận được sự đồng ý từ bất kỳ ai có chân dung được sửa đổi. Nhãn hiệu Tencent không thể được sử dụng nếu không có lệnh viết
# Trình bao bọc sản xuất có ghi nhật ký có cấu trúc
nhập nhật ký
thời gian nhập khẩu
ngọn đuốc nhập khẩu
ghi nhật ký.basicConfig(
cấp độ = ghi nhật ký.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
trình xử lý=[
log.FileHandler('videoretalking.log'),
ghi nhật ký.StreamHandler()
]
)
def inference_with_monitoring(face_path, audio_path, out_path):
bắt đầu = thời gian.time()
vram_b Before = torch.cuda.memory_allocated() / 1e9
# Chạy suy luận
subprocess.run([...]) # lệnh suy luận
đã trôi qua = time.time() - bắt đầu
vram_after = torch.cuda.memory_allocated() / 1e9
logging.info(f"Đã xử lý {face_path} trong {elapsed:.1f}s, "
f"VRAM: {vram_trước:.1f}GB -> {vram_after:.1f}GB")
```c
. Hãy thử chuyển sang trình tăng cường GPEN bằng cách chỉnh sửa `inference.py` và thay đổi cách khởi tạo trình tăng cường. Ngoài ra, hãy tắt hoàn toàn tính năng nâng cao để có đầu ra sắc nét hơn (nhưng có thể kém nhất quán hơn).### Tôi có thể tinh chỉnh các mô hình trên tập dữ liệu của riêng mình không?Kho lưu trữ chỉ cung cấp mã suy luận. Việc tinh chỉnh sẽ yêu cầu triển khai lại các vòng đào tạo cho D-Net (chỉnh sửa biểu thức trên VoxCeleb) và L-Net (đồng bộ hóa môi trên LRS2). Bài viết bao gồm đầy đủ chi tiết kiến trúc cho việc này, nhưng không có tập lệnh đào tạo nào được đưa vào.## Phần kết luậnVideoReTalking cung cấp giải pháp tự lưu trữ, thiết thực để đồng bộ hóa môi theo hướng âm thanh với chất lượng đầu ra ở cấp độ sản xuất. Quy trình ba giai đoạn — chuẩn hóa biểu thức, tạo hát nhép và nâng cao khuôn mặt — tạo ra kết quả sánh ngang với các giải pháp thay thế thương mại với chi phí thấp hơn cho quy trình làm việc có khối lượng lớn.**Các mục hành động để bắt đầu:**1. Sao chép repo và thiết lập môi trường conda bằng các lệnh trên
2. Tải gói điểm kiểm tra 2GB vào `./checkpoints/`
3. Chạy lệnh suy luận nhanh với file mẫu trong `examples/`
4. Khởi chạy Gradio WebUI để thử nghiệm tương tác
5. Kết hợp với GPT-SoVITS hoặc RVC để có quy trình nhân bản giọng nói + đồng bộ hóa môi hoàn chỉnhTham gia [cộng đồng nhà phát triển dibi8 trên Telegram](https://t.me/dibi8tech) để chia sẻ quá trình triển khai VideoReTalking của bạn và nhận trợ giúp từ những nhà xây dựng khác.
## Lưu trữ và cơ sở hạ tầng được đề xuấtTrước khi triển khai bất kỳ công cụ nào ở trên vào sản xuất, bạn sẽ cần cơ sở hạ tầng vững chắc. Hai tùy chọn dibi8 thực sự sử dụng và khuyến nghị:- **DigitalOcean
** — khoản tín dụng miễn phí 200 USD trong 60 ngày trên hơn 14 khu vực trên toàn cầu. Tùy chọn mặc định cho các nhà phát triển độc lập chạy các công cụ AI nguồn mở.
- **HTStack
** — VPS Hồng Kông có khả năng truy cập có độ trễ thấp từ Trung Quốc đại lục. Đây chính là IDC lưu trữ dibi8.com — đã được thử nghiệm trong quá trình sản xuất.*Các liên kết liên kết — chúng không làm bạn mất thêm phí và giúp dibi8.com tiếp tục hoạt động.*## Nguồn & Đọc thêm- [Kho lưu trữ GitHub VideoReTalking](https://github.com/OpenTalker/video-retalking)
- [Trang dự án VideoReTalking](https://opentalker.github.io/video-retalking/)
- [VideoReTalking arXiv Paper](https://arxiv.org/abs/2211.14758)
- [Kỷ yếu SIGGRAPH Châu Á 2022](https://arxiv.org/pdf/2211.14758.pdf)
- [Kho lưu trữ Wav2Lip](https://github.com/Rudrabha/Wav2Lip)
- [Kho lưu trữ SadTalker](https://github.com/OpenTalker/SadTalker)
- [Kho lưu trữ GeneFace](https://github.com/yerfor/GeneFace)
- [Khôi phục khuôn mặt GFPGAN](https://github.com/TencentARC/GFPGAN)
- [Mô hình được đào tạo trước (Google Drive)](https://drive.google.com/drive/folders/18rhjMpxK8LVVxf7PI6XwOidt8Vouv_H0)<!--tự động tham khảo-->
## Tài liệu tham khảo & Nguồn- [VideoReTalking](https://github.com/OpenTalker/video-retalking)
- [Wav2Lip](https://github.com/Rudrabha/Wav2Lip)
- [SadTalker](https://github.com/OpenTalker/SadTalker)
- [GeneFace](https://github.com/yerfor/GeneFace)
- [GFPGAN](https://github.com/TencentARC/GFPGAN)
- [GPEN](https://github.com/yangxy/GPEN)
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
- [Coqui TTS](https://github.com/coqui-ai/TTS)
💬 Bình luận & Thảo luận