exo: Chạy AI tiên phong trên chính các thiết bị của bạn (45K Stars) — Hướng dẫn thực chiến 2026
exo biến các máy Mac, PC và cả điện thoại của bạn thành một cụm duy nhất để chạy các mô hình AI tiên phong ngay tại chỗ. 45.088 sao GitHub, giấy phép Apache-2.0. Bao gồm cài đặt, bảng điều khiển, API tương thích OpenAI/Claude/Ollama, các lệnh thực tế và một so sánh thẳng thắn.
- ⭐ 45088
- Apache-2.0
- Cập nhật 2026-06-02
Giới thiệu #
Các mô hình tiên phong rất đồ sộ. Một mô hình 671 tỉ tham số không thể nhét vừa vào một chiếc laptop, còn nếu tự thuê đủ GPU đám mây để chạy thì chi phí leo thang rất nhanh. exo chọn một hướng đi khác: nó ghép các thiết bị bạn đã có—Mac, máy Linux, thậm chí điện thoại—thành một cụm duy nhất, rồi chia mô hình ra trên các thiết bị đó để chúng cùng nhau suy luận. Với hơn 45.000 sao trên GitHub, nó đã trở thành một trong những dự án được theo dõi nhiều nhất cho việc chạy mô hình lớn trên phần cứng do chính bạn kiểm soát. Hướng dẫn này sẽ đưa bạn đi qua việc cài đặt exo, mở bảng điều khiển, và trò chuyện với nó qua API tương thích OpenAI, Claude và Ollama.
exo là gì? #
exo là một công cụ mã nguồn mở chạy các mô hình AI tiên phong tại chỗ bằng cách kết hợp nhiều thiết bị thành một cụm phân tán duy nhất. Thay vì ép một máy phải chứa cả mô hình, exo phân mảnh các lớp của mô hình ra mọi nút mà nó phát hiện trên mạng, nhờ vậy một mô hình vốn quá lớn với bất kỳ thiết bị đơn lẻ nào vẫn có thể chạy được.
Dự án do nhóm exo-explore (exo labs) duy trì và phát hành theo giấy phép Apache-2.0, nên bạn được tự do sử dụng, xem xét và chỉnh sửa mã nguồn.
exo hoạt động thế nào #
Đây là những gì exo làm ở bên dưới:
- Thực thi tại chỗ: mô hình chạy trên chính các thiết bị của bạn, nên prompt và dữ liệu không rời khỏi mạng của bạn, đồng thời tránh được chi phí đám mây tính theo token.
- Tự động lập cụm: exo tự tìm ra các thiết bị khác đang chạy exo trong cùng mạng—không có tệp cấu hình liệt kê các nút, cũng không phải tự tay viết thiết lập kiểu “máy chủ/máy thợ”.
- Phân chia theo tô-pô mạng: exo đo tài nguyên và độ trễ của từng nút theo thời gian thực, rồi quyết định cách chia các lớp của mô hình lên chúng, nhờ vậy một mô hình quá lớn với bất kỳ máy đơn lẻ nào vẫn chạy được trên cả cụm.
Kết quả là khi thêm một chiếc Mac hay PC nữa vào mạng, cụm đơn giản có thêm bộ nhớ và sức tính toán để dùng, mà bạn không phải viết lại bất kỳ cấu hình nào.
Cài đặt & Thiết lập #
Nếu bạn muốn exo luôn sẵn sàng truy cập suốt ngày đêm (chẳng hạn một điểm cuối dùng chung trong nội bộ), bạn sẽ cần một máy luôn bật—có thể dựng một máy trên DigitalOcean (tài khoản mới có tín dụng dùng thử miễn phí), hoặc dùng HTStack cho VPS Hồng Kông độ trễ thấp (cùng IDC đang host dibi8.com). Về suy luận tăng tốc bằng GPU, lưu ý rằng exo hiện tăng tốc trên Apple Silicon; Linux tạm thời chỉ chạy bằng CPU, hỗ trợ GPU đang được phát triển.
Ứng dụng macOS (dễ nhất) #
Cách đơn giản nhất trên Mac là dùng ứng dụng đã dựng sẵn. Cài bằng Homebrew:
brew install --cask exo
Hoặc tải trực tiếp bản DMG mới nhất từ https://assets.exolabs.net/EXO-latest.dmg. Ứng dụng yêu cầu một bản macOS tương đối mới.
Dựng từ mã nguồn (macOS hoặc Linux) #
Để chạy mã mới nhất, hãy clone kho và khởi động bằng uv. Trước tiên bạn cần cài uv, Node 18+ và bộ công cụ Rust phiên bản nightly (trên macOS còn cần Xcode, Homebrew và macmon):
git clone https://github.com/exo-explore/exo
cd exo/dashboard && npm install && npm run build && cd ..
uv run exo
Nếu bạn dùng Nix, có thể bỏ qua hoàn toàn các yêu cầu tiên quyết:
nix run .#exo
Lỗi thường gặp và cách khắc phục #
Một trục trặc hay gặp ở lần chạy đầu là bảng điều khiển không tải được vì phần giao diện chưa bao giờ được dựng. Giao diện web được biên dịch từ thư mục dashboard/, nên nếu bạn clone kho rồi chạy uv run exo mà chưa dựng nó, hãy dựng lại bảng điều khiển trước khi khởi động:
cd dashboard && npm install && npm run build && cd ..
uv run exo
Nếu gặp vấn đề khác trong lúc cài đặt, hãy xem tệp README chính thức trong kho.
- Image:
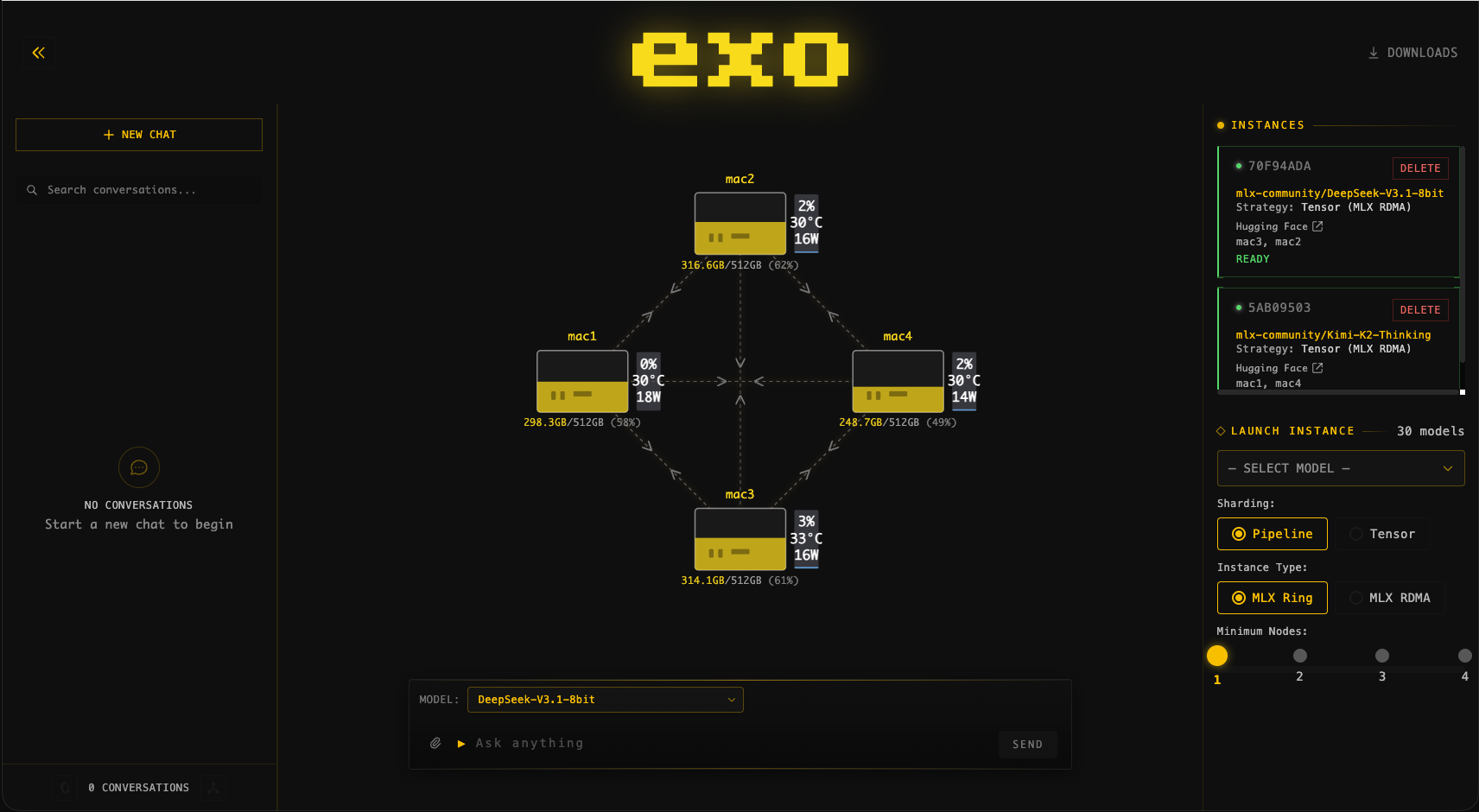
- Source: exo-explore/exo GitHub
Cách dùng cốt lõi #
Sau khi cài exo xong, quy trình ngắn gọn đến mức dễ chịu: khởi động nó trên từng thiết bị, mở bảng điều khiển, rồi gửi yêu cầu tới API của nó.
Khởi động một nút #
Chạy exo trên mọi thiết bị bạn muốn đưa vào cụm:
uv run exo
Mỗi nút tự động tìm ra các nút khác trong cùng mạng—không cần đăng ký thủ công. Vài cờ tiện dụng:
--no-worker: chạy nút chỉ làm điều phối, bản thân nó không thực hiện suy luận.--legacy-daemon: chạy exo dưới dạng tiến trình nền (daemon).
Giám sát cụm #
exo phục vụ một bảng điều khiển ở cổng 52415. Mở nó trong trình duyệt:
http://localhost:52415
Bạn sẽ thấy mọi thiết bị mà exo đã phát hiện, mô hình hiện tại được chia trên chúng ra sao, cùng thông lượng và mức dùng bộ nhớ theo thời gian thực.
Gọi mô hình #
exo cung cấp một API HTTP tương thích với các định dạng OpenAI, Claude (Anthropic Messages) và Ollama, nên hầu hết mã client sẵn có dùng được mà không phải sửa. Một yêu cầu chat dạng streaming trông như sau:
curl -X POST http://localhost:52415/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{"model": "model-id", "messages": [{"role": "user", "content": "prompt"}], "stream": true}'
Cùng điểm cuối đó cũng hiểu Claude Messages API tại /v1/messages và Ollama API tại /ollama/api/chat.
Kết luận #
Toàn bộ vòng lặp là vậy: khởi động một nút trên từng thiết bị, ngắm cụm hợp lại trong bảng điều khiển, rồi trỏ bất kỳ client OpenAI/Claude/Ollama nào vào nó. Vì API này dùng đúng định dạng mà các công cụ vốn đã “nói” được, việc đổi một điểm cuối lưu trữ trên đám mây sang cụm exo của riêng bạn thường chỉ là một thay đổi một dòng.
Tích hợp #
Vì exo “nói” được API của OpenAI, Claude và Ollama, nó hòa vào hầu hết các quy trình sẵn có chỉ bằng cách đổi base URL—không cần SDK chuyên dụng.
Tái sử dụng client OpenAI sẵn có #
Trỏ bất kỳ client tương thích OpenAI nào tới điểm cuối exo cục bộ và nó chạy ngay:
# Nói chuyện với cụm exo cục bộ bằng client OpenAI chuẩn
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:52415/v1",
api_key="not-needed", # dùng cục bộ thì exo không cần khóa
)
response = client.chat.completions.create(
model="model-id",
messages=[{"role": "user", "content": "Summarize the exo project in one sentence."}],
)
print(response.choices[0].message.content)
Dùng trong Jupyter notebook #
Cùng một client cũng chạy được trong notebook, rất tiện để thử nghiệm nhanh với cụm:
# Thử nhanh trong Jupyter notebook
from openai import OpenAI
client = OpenAI(base_url="http://localhost:52415/v1", api_key="not-needed")
response = client.chat.completions.create(
model="model-id",
messages=[{"role": "user", "content": "List three uses for a local AI cluster."}],
)
print(response.choices[0].message.content)
Vì mọi thứ đều đi qua một API HTTP chuẩn, bạn có thể tích hợp exo với bất kỳ ngôn ngữ hay framework nào có thể gửi một yêu cầu POST.
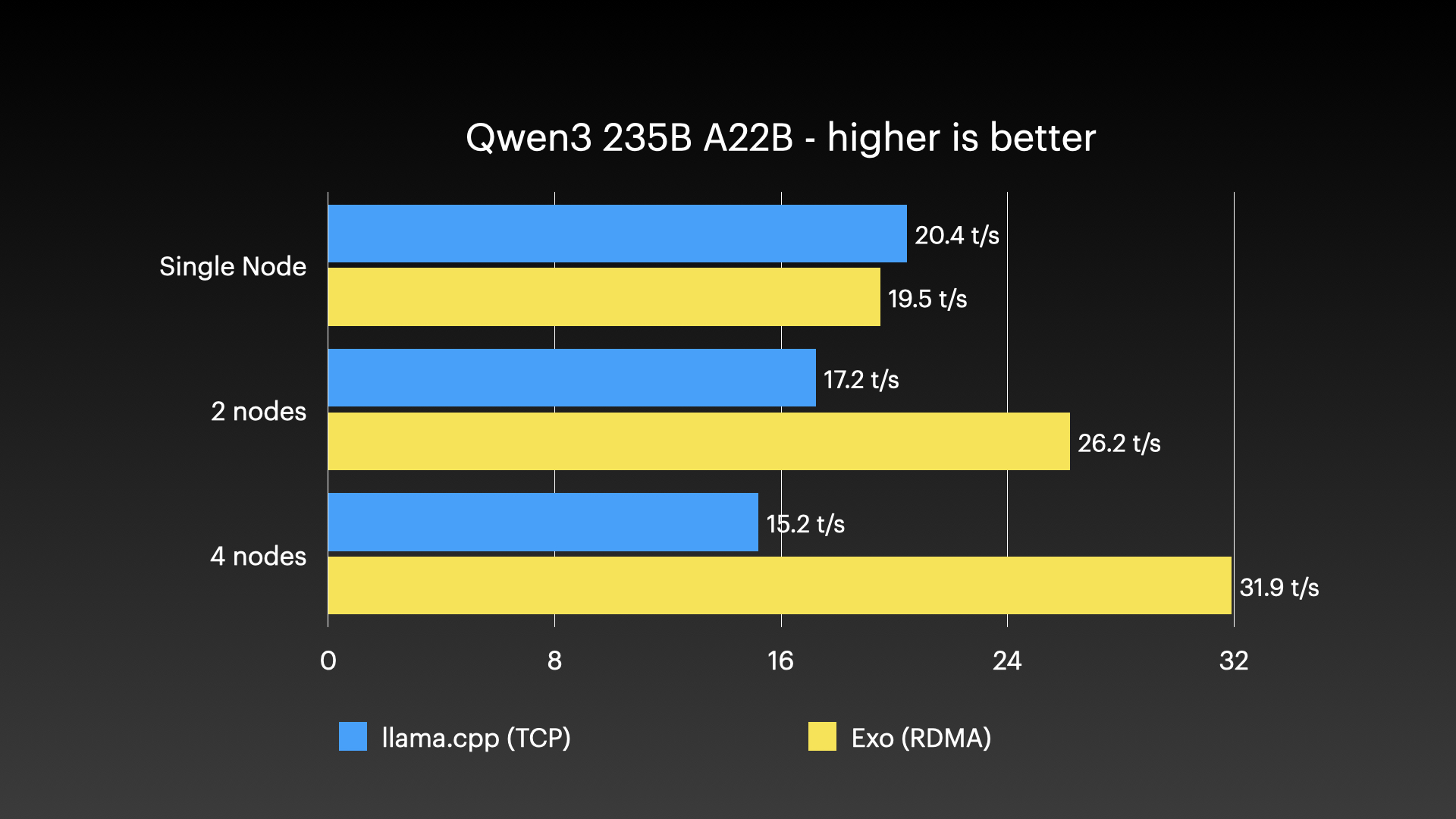
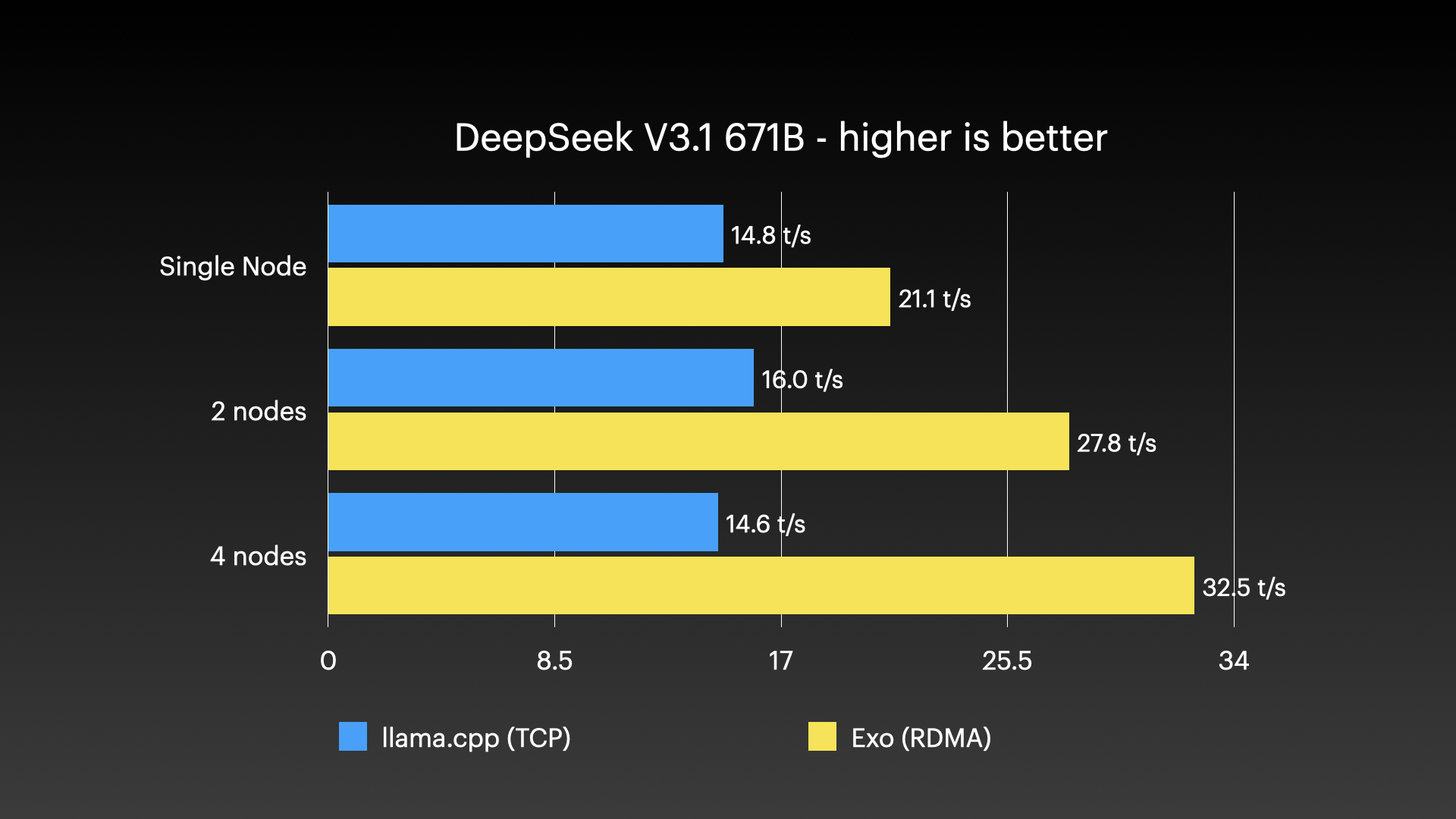
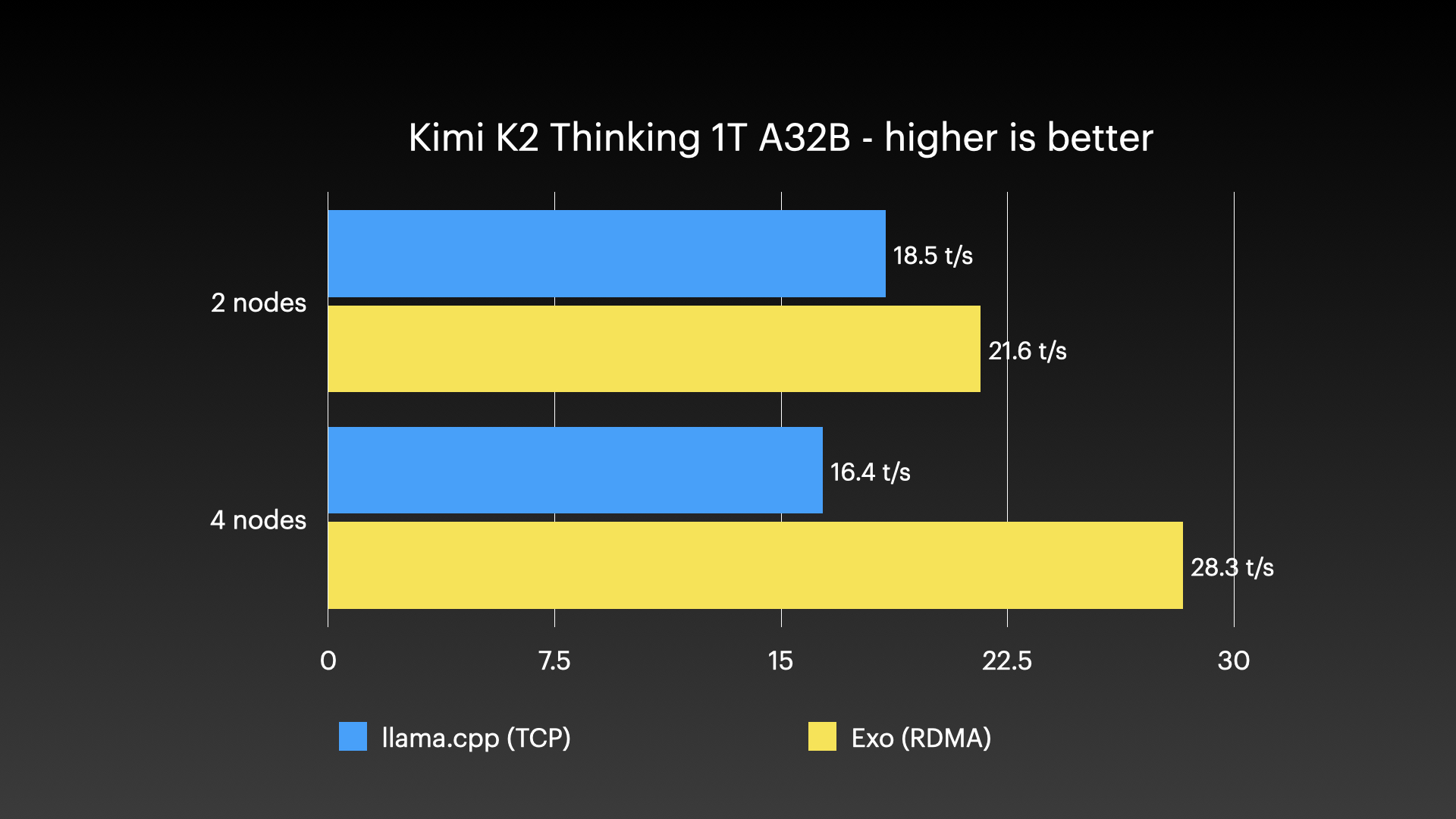
Benchmark & Sử dụng thực tế #
Các benchmark hiệu năng #
exo đã được trình diễn chạy những mô hình rất lớn trên các cụm gồm nhiều máy Mac Apple Silicon—kiểu khối lượng công việc mà không một máy tiêu dùng đơn lẻ nào kham nổi. Các hình dưới đây cho thấy những lần chạy cụm thực tế:
Các tình huống dùng thực tế #
Suy luận cục bộ riêng tư: chạy các mô hình tiên phong trên phần cứng của chính bạn để prompt và dữ liệu ở lại trong mạng của bạn.
Chạy mô hình không vừa một máy: gộp bộ nhớ của nhiều thiết bị để phục vụ những mô hình hàng trăm tỉ tham số.
Giám sát cụm: bảng điều khiển cho một góc nhìn duy nhất về mọi nút, cách mô hình được phân mảnh và thông lượng theo thời gian thực.
Thay thế API kiểu cắm-là-chạy: vì exo phản chiếu API của OpenAI, Claude và Ollama, nó có thể thay cho một điểm cuối lưu trữ trên đám mây chỉ bằng việc đổi base URL.
Phòng lab Apple Silicon: các nhóm có vài máy Mac có thể nối chúng qua Thunderbolt để dựng nên một cụm suy luận đủ mạnh từ phần cứng đã có sẵn.
So sánh với các lựa chọn khác #
Xem thêm bài viết của chúng tôi về các công cụ mã nguồn mở liên quan.
exo không phải cách duy nhất để chạy mô hình tại chỗ, và nó giải quyết một bài toán rất cụ thể—trải một mô hình lớn ra nhiều thiết bị—mà các công cụ một-máy không làm được. Bảng dưới đây phác họa nó so với hai lựa chọn phổ biến: ollama/ollama (phục vụ cục bộ trên một máy) và ggml-org/llama.cpp (động cơ suy luận mà nhiều công cụ cục bộ xây dựng dựa trên).
| Tính năng | exo-explore/exo | ollama/ollama | ggml-org/llama.cpp |
|---|---|---|---|
| Giấy phép | Apache-2.0 | MIT | MIT |
| Ngôn ngữ chính | Python / Rust | Go | C/C++ |
| Cụm nhiều thiết bị | Có (tự phát hiện) | Không (một máy) | Không (một máy) |
| Tăng tốc GPU | Apple Silicon (Linux tạm CPU) | NVIDIA / Apple / khác | NVIDIA / Apple / CPU |
| Cài đặt | Dựng từ nguồn hoặc app macOS | Cài một dòng | Biên dịch từ nguồn |
| Tương thích API | OpenAI + Claude + Ollama | OpenAI + Ollama gốc | Máy chủ tương thích OpenAI |
| Hợp nhất cho | Mô hình không vừa một thiết bị | Phục vụ cục bộ một máy dễ dàng | Động cơ cấp thấp / embedding |
| Bảng điều khiển | Bảng điều khiển web (cổng 52415) | CLI + REST API | CLI / máy chủ tối giản |
Tóm tắt thẳng thắn: nếu mô hình của bạn vừa thoải mái trong một máy, một công cụ một-máy như Ollama sẽ đơn giản hơn và được hỗ trợ tốt hơn trên nhiều loại GPU. exo phát huy giá trị khi mô hình quá lớn với bất kỳ thiết bị đơn lẻ nào và bạn muốn gộp nhiều máy—đặc biệt là một dàn Mac Apple Silicon—thành một cụm.
Hạn chế & Đánh giá thẳng thắn #
exo thực sự hữu ích, nhưng đây là một dự án còn trẻ và biến đổi nhanh. Vài lưu ý thành thật:
Apple Silicon là con đường mạnh. Tăng tốc GPU hiện nhắm tới Apple Silicon. Linux tạm thời chỉ chạy CPU (hỗ trợ GPU đang được làm), nên một máy Linux có GPU có thể không nhanh như bạn tưởng.
Nó sinh ra cho cụm mô hình lớn. Nếu mô hình của bạn đã vừa một máy, bộ máy phân tán của exo là thừa thãi—một công cụ một-máy sẽ đơn giản hơn.
Dựng từ nguồn có yêu cầu tiên quyết thật sự. Chạy từ nguồn cần
uv, Node, bộ công cụ Rust nightly và (trên macOS) Xcode cùng các công cụ phụ. Ứng dụng macOS tránh được điều này, nhưng người dùng bản nguồn nên chuẩn bị cho một quá trình thiết lập nặng hơn so với cài một dòng.Mã nguồn biến đổi nhanh. Là một dự án đang phát triển sôi nổi, API và hành vi có thể thay đổi giữa các phiên bản. Hãy ghim vào một commit đã biết là ổn nếu bạn cần sự ổn định.
Phụ thuộc mạng. Hiệu năng trên toàn cụm phụ thuộc vào đường truyền giữa các thiết bị; mạng chậm giữa các nút có thể trở thành nút thắt cổ chai cho suy luận, đó là lý do kết nối Thunderbolt quan trọng với những thiết lập nhanh nhất.
Những đánh đổi này chỉ ra nơi exo có thể không phù hợp, nhưng cũng làm nổi bật thế mạnh thực sự của nó: chạy những mô hình mà ở nơi khác đơn giản là không thể chạy, trên chính phần cứng bạn đã có.
Kết luận #
exo của exo-explore là một công cụ hấp dẫn để chạy AI tiên phong trên phần cứng của chính bạn: hơn 45.000 sao GitHub, giấy phép Apache-2.0, tự động lập cụm, và một API vốn đã “nói” được OpenAI, Claude và Ollama. Điểm mạnh nhất của nó là chạy những mô hình không vừa một máy bằng cách gộp nhiều thiết bị—đặc biệt là các máy Mac Apple Silicon. Bước tiếp theo tự nhiên là cài ứng dụng hoặc clone kho, khởi động một nút trên từng thiết bị, và ngắm cụm hợp lại trong bảng điều khiển.
- Tham gia nhóm Telegram tiếng Anh của dibi8 để nhận tin về các công cụ AI mã nguồn mở.
- Đọc tiếp: các hướng dẫn liên quan trên dibi8.
Sources & Further Reading:
- GitHub repository: https://github.com/exo-explore/exo
- Official docs / README: https://github.com/exo-explore/exo#readme
Một số liên kết ở trên là liên kết tiếp thị (affiliate). dibi8.com có thể nhận hoa hồng nếu bạn đăng ký, mà bạn không phải trả thêm bất kỳ chi phí nào. Điều này giúp duy trì hoạt động của trang và giữ cho nội dung miễn phí.
💬 Bình luận & Thảo luận