Marker: Chuyển PDF, DOCX & EPUB sang Markdown/JSON nhanh chóng — Hướng dẫn thực dụng 2026
Marker (datalab-to/marker) chuyển PDF, DOCX, EPUB và nhiều định dạng khác sang Markdown, JSON, HTML và chunks một cách nhanh chóng, chính xác. 35.694 sao GitHub, mã nguồn theo giấy phép GPL-3.0. Bao gồm cài đặt, CLI và Python API, ví dụ mã thực tế, chế độ LLM, cùng so sánh khách quan với các công cụ thay thế.
- ⭐ 35694
- GPL-3.0
- Cập nhật 2026-06-02
Giới thiệu #
Biến tài liệu thành văn bản sạch, có cấu trúc nghe thì đơn giản, cho đến khi bạn thực sự thử với một file PDF đầy bảng, công thức và bố cục nhiều cột. datalab-to/marker được xây dựng đúng cho việc đó: nó chuyển PDF và nhiều loại tài liệu khác sang Markdown, JSON, HTML hoặc chunks sẵn sàng cho RAG thông qua một pipeline học sâu, kèm tùy chọn cho LLM xử lý thêm những phần khó. Hướng dẫn này sẽ dẫn bạn qua phần cài đặt, công cụ dòng lệnh, Python API, và một so sánh khách quan với các lựa chọn thay thế để bạn quyết định liệu nó có phù hợp với dự án của mình hay không.
Bắt đầu thôi nào!
![]()
marker overview (source: datalab-to/marker repo, via dibi8 analysis)
marker là gì? #
Marker là một công cụ chuyển đổi tài liệu bằng Python của Datalab, biến PDF (cùng hình ảnh, PPTX, DOCX, XLSX, HTML và EPUB) thành Markdown, JSON, HTML và đầu ra dạng khối (chunks). Nó được giới lập trình viên ưa chuộng, với hơn 35.694 sao trên GitHub. Thay vì chỉ một bước OCR đơn lẻ, nó chạy một pipeline: trích xuất văn bản, phát hiện bố cục trang và thứ tự đọc, làm sạch và định dạng các khối, rồi tùy chọn áp dụng LLM để cải thiện độ chính xác trên bảng, biểu mẫu và công thức nội dòng.
marker hoạt động như thế nào #
marker được thiết kế để chuyển tài liệu sang Markdown, JSON, HTML và chunks một cách nhanh chóng và chính xác. Dưới đây là cách pipeline vận hành:
- Trích xuất văn bản: Marker lấy văn bản trực tiếp từ tài liệu khi có thể, và quay về OCR cho các trang quét hoặc trang dạng ảnh.
- Bố cục & thứ tự đọc: Các mô hình học sâu phát hiện bố cục trang và thứ tự đọc đúng — đây chính là điều khiến PDF nhiều cột cho ra kết quả dễ đọc.
- Làm sạch & định dạng khối: Mỗi khối (tiêu đề, đoạn văn, bảng, công thức, mã) được làm sạch và định dạng, với bảng được dựng thành Markdown/HTML và công thức thành LaTeX.
- Tinh chỉnh tùy chọn bằng LLM: Với
--use_llm, một mô hình (Gemini, Claude, OpenAI hoặc mô hình Ollama cục bộ) được dùng để cải thiện độ chính xác trên bảng, biểu mẫu và công thức. - Dựng & hậu xử lý: Các khối được ghép lại, hậu xử lý thành định dạng đầu ra bạn chọn.
Cách đơn giản nhất để điều khiển tất cả những điều này là qua CLI, được trình bày ngay sau đây.
marker architecture (source: datalab-to/marker repo, via dibi8 analysis)
Cài đặt & Thiết lập #
Để chạy marker như một tác vụ sản xuất theo lịch, bạn cần một máy luôn bật — hãy dựng một máy trên DigitalOcean (tài khoản mới có tín dụng dùng thử miễn phí), hoặc HTStack cho VPS Hồng Kông độ trễ thấp (cùng IDC đang host dibi8.com).
Để bắt đầu với datalab-to/marker, hãy cài đặt từ PyPI.
Dùng pip #
Trước hết, hãy đảm bảo hệ thống của bạn đã có Python. Sau đó cài gói marker-pdf:
pip install marker-pdf
Nếu bạn cần chuyển các định dạng không phải PDF (DOCX, PPTX, XLSX, EPUB, HTML, hình ảnh), hãy cài kèm phần phụ thuộc đầy đủ:
pip install marker-pdf[full]
Clone kho mã #
Hoặc bạn có thể clone trực tiếp kho mã từ GitHub để phát triển cục bộ:
git clone https://github.com/datalab-to/marker.git
cd marker
pip install -e .
Lỗi thường gặp và cách khắc phục #
Một vấn đề phổ biến là trộn lẫn việc cài đặt ở môi trường hệ thống và môi trường ảo, dẫn đến “command not found” cho marker_single hoặc xung đột phụ thuộc. Hãy đảm bảo môi trường ảo đã được kích hoạt trước khi cài đặt và chạy:
# Activate the virtual environment (assuming you're using venv)
source .venv/bin/activate
# Install, then run
pip install marker-pdf
marker_single /path/to/file.pdf
Nếu bạn gặp vấn đề về GPU hoặc tải mô hình trong lần chạy đầu tiên, hãy xem README.md của kho mã để được hướng dẫn, hoặc mở một issue trên GitHub.
Cách dùng cốt lõi #
Sau khi cài marker-pdf, bạn có hai điểm vào CLI: marker_single cho một file và marker cho cả một thư mục.
Ví dụ 1: Chuyển một file đơn lẻ #
Để chuyển một tài liệu sang Markdown (định dạng đầu ra mặc định):
marker_single /path/to/report.pdf
Kết quả chuyển đổi được ghi vào một thư mục đầu ra; bạn có thể điều khiển định dạng bằng --output_format.
Ví dụ 2: Chọn định dạng đầu ra #
Marker hỗ trợ markdown, json, html và chunks (một bố cục JSON phẳng được thiết kế cho pipeline RAG):
marker_single /path/to/report.pdf --output_format json
Ví dụ 3: Chuyển cả một thư mục tài liệu #
Để chuyển hàng loạt mọi tài liệu trong một thư mục:
marker /path/to/input/folder --output_format markdown
Ví dụ 4: Chuyển các trang cụ thể, hoặc dùng LLM #
Bạn có thể giới hạn việc chuyển đổi theo một khoảng trang và bật độ chính xác có LLM hỗ trợ:
marker_single /path/to/report.pdf --page_range "0,5-10,20" --use_llm
--page_range nhận các trang và khoảng trang ngăn cách bằng dấu phẩy, còn --use_llm chuyển những bảng, biểu mẫu và công thức nội dòng khó nhằn qua một mô hình (Gemini, Claude, OpenAI hoặc Ollama) để tăng độ chính xác. Với các tác vụ đa GPU lớn, còn có marker_chunk_convert:
NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
Những ví dụ này đủ để bạn khởi đầu. Để xem danh sách đầy đủ các cờ, hãy tham khảo README chính thức trên GitHub.
Tích hợp #
marker vừa là thư viện Python vừa là CLI, nên nó hòa vào script, notebook và pipeline một cách gọn gàng.
Dùng Python API #
Chuyển một file và lấy về văn bản đã dựng cùng hình ảnh trích xuất chỉ với vài dòng:
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = PdfConverter(artifact_dict=create_model_dict())
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
Để đổi định dạng đầu ra hoặc bật dịch vụ LLM, hãy điều khiển qua ConfigParser:
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.config.parser import ConfigParser
config_parser = ConfigParser({"output_format": "json"})
converter = PdfConverter(
config=config_parser.generate_config_dict(),
artifact_dict=create_model_dict(),
processor_list=config_parser.get_processors(),
renderer=config_parser.get_renderer(),
llm_service=config_parser.get_llm_service(),
)
rendered = converter("FILEPATH")
Marker cũng đi kèm các bộ chuyển đổi chuyên dụng — TableConverter chỉ cho bảng, OCRConverter chỉ cho đầu ra OCR, và một ExtractionConverter bản beta dùng để trích xuất dữ liệu có cấu trúc theo một schema JSON của Pydantic.
Tích hợp với pipeline CI/CD #
Vì nó là một CLI thuần túy, bạn có thể chạy marker như một bước trong bất kỳ tác vụ CI/CD nào. Dưới đây là ví dụ GitHub Actions tối giản, chuyển một PDF mỗi khi có push:
name: Convert PDF to Markdown
on:
push:
branches: [ master ]
jobs:
convert-pdf:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install marker
run: pip install marker-pdf
- name: Convert PDF to Markdown
run: marker_single docs/report.pdf --output_format markdown
Nhờ vậy, việc đưa marker vào cả notebook lẫn pipeline build tự động đều dễ dàng.
Đánh giá hiệu năng & Sử dụng thực tế #
Thông lượng #
Theo chính README của dự án, marker có thể đạt khoảng 25 trang mỗi giây ở chế độ xử lý theo lô trên GPU H100. Thông lượng thực tế phụ thuộc rất nhiều vào phần cứng, độ phức tạp của tài liệu, và việc có bật --use_llm hay không (bước LLM đánh đổi tốc độ lấy độ chính xác). Hãy xem mọi con số đơn lẻ là mức trần chứ không phải lời bảo đảm, và tự đo trên chính tài liệu của bạn.
Tình huống sử dụng thực tế #
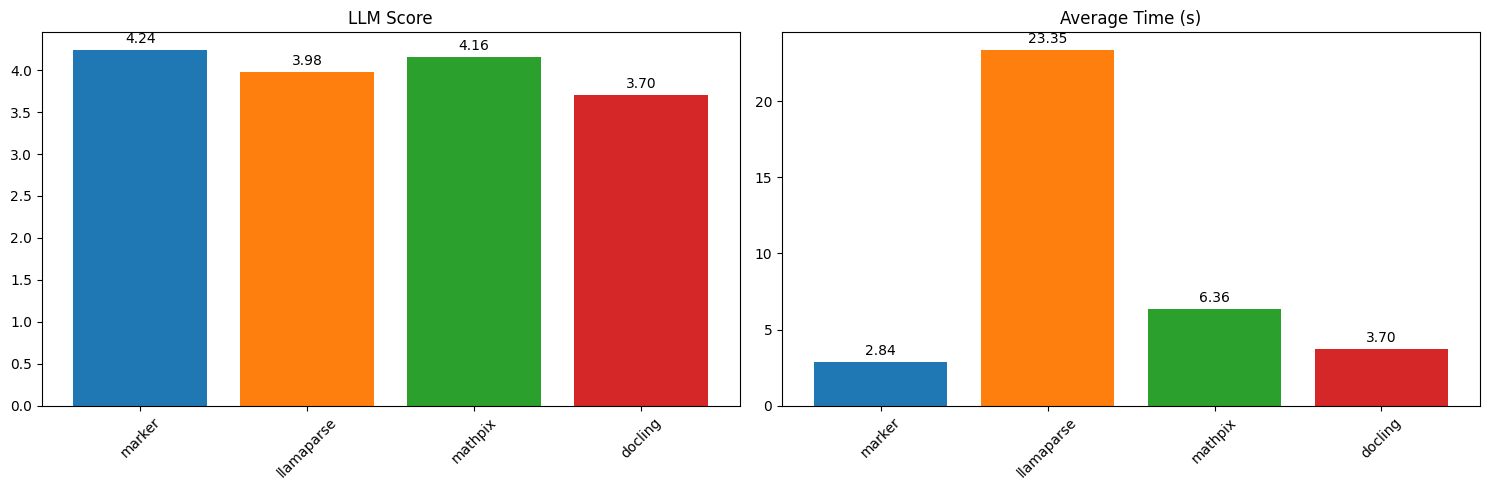
Marker thường được dùng cho các tác vụ như xây dựng kho tài liệu cho tìm kiếm và RAG, trích xuất bảng và biểu mẫu từ báo cáo, cũng như chuyển các bài báo học thuật, sổ tay và sách thành Markdown sạch để xử lý tiếp. Đặc biệt, định dạng đầu ra chunks hướng tới các pipeline sinh tăng cường truy hồi (RAG), nơi mỗi khối được đưa ra dưới dạng HTML tự đứng độc lập.

marker benchmark results (source: datalab-to/marker repo, via dibi8 analysis)
So sánh với các lựa chọn thay thế #
Bạn cũng có thể xem bài tổng hợp các công cụ mã nguồn mở liên quan của chúng tôi.
Khi chọn một công cụ chuyển PDF sang Markdown, hãy cân nhắc độ chính xác, mức độ hỗ trợ định dạng, tốc độ và giấy phép. Dưới đây là so sánh tổng quan giữa marker và hai lựa chọn mã nguồn mở phổ biến: pdfplumber (trích xuất văn bản/bảng) và pymupdf4llm (bộ xuất Markdown dựa trên PyMuPDF).
| Tính năng | datalab-to/marker | pdfplumber | pymupdf4llm |
|---|---|---|---|
| Ngôn ngữ | Python | Python | Python |
| Cách tiếp cận | Bố cục học sâu + OCR + LLM tùy chọn | Trích xuất văn bản theo luật | Trích xuất dựa trên PyMuPDF |
| Định dạng vào | PDF, ảnh, PPTX, DOCX, XLSX, HTML, EPUB | Chỉ PDF | PDF và vài định dạng |
| Định dạng ra | Markdown, JSON, HTML, chunks | Văn bản, bảng (dict) | Markdown |
| OCR / bản quét | OCR tích hợp sẵn | Không có OCR gốc | Hạn chế |
| Chế độ LLM | Tùy chọn (--use_llm) | Không | Không |
| Phù hợp nhất | Bố cục phức tạp, bảng, RAG, bản quét | Xử lý bảng/tọa độ chính xác | Xuất Markdown nhanh, đơn giản |
marker nổi bật khi tài liệu phức tạp — bố cục nhiều cột, công thức, trang quét hay bảng — bởi các mô hình bố cục và bước LLM tùy chọn của nó xử lý được cấu trúc mà những công cụ theo luật bỏ sót. Các công cụ nhẹ hơn như pdfplumber và pymupdf4llm thì nhanh hơn, ít phụ thuộc hơn, và phù hợp hơn khi PDF của bạn đơn giản, là bản số gốc và chỉ có văn bản. Hãy chọn dựa trên mức độ “lộn xộn” của tài liệu thực tế của bạn.
Hạn chế & Đánh giá thẳng thắn #
Dù marker rất mạnh với tài liệu phức tạp, nó có những đánh đổi thực tế đáng biết trước:
- Phụ thuộc nặng & yêu cầu phần cứng cao: marker dựa vào các mô hình học sâu, nên có GPU hay không tạo khác biệt lớn. Trên máy chỉ có CPU thì vẫn chạy được nhưng chậm hơn nhiều, và bản cài đặt cũng nặng hơn so với các thư viện theo luật.
- Bảng phức tạp chưa hoàn hảo: Bảng trải dài qua nhiều trang hoặc có ô lồng/gộp sâu vẫn có thể bị lệch và cần dọn dẹp thủ công.
- Chế độ LLM thêm chi phí và độ trễ:
--use_llmcải thiện độ chính xác nhưng thêm một lệnh gọi mô hình bên ngoài (và chi phí API, trừ khi bạn chạy mô hình Ollama cục bộ), nên chậm hơn và không miễn phí. - Tốc độ dao động lớn: Các con số thông lượng nổi bật giả định GPU cao cấp và xử lý theo lô; trên phần cứng phổ thông hoặc khi bật chế độ LLM, hãy chuẩn bị cho việc chạy chậm hơn đáng kể.
- Sắc thái về giấy phép: Mã nguồn theo GPL-3.0, nhưng trọng số mô hình dùng giấy phép AI Pubs Open Rail-M đã sửa đổi — miễn phí cho nghiên cứu, sử dụng cá nhân và các công ty nhỏ, còn các tổ chức lớn cần giấy phép thương mại — hãy kiểm tra điều khoản trước khi triển khai ở quy mô lớn.
Những đánh đổi này rất quan trọng khi cân nhắc liệu marker có phải là công cụ phù hợp cho trường hợp cụ thể của bạn hay không.
Kết luận #
Với hơn 35.694 sao và một pipeline được xây dựng để xử lý những tài liệu lộn xộn của thực tế, marker là một lựa chọn vững chắc khi bạn cần đầu ra Markdown, JSON, HTML hoặc chunks chính xác từ PDF, file Office và EPUB — đặc biệt khi có bảng, công thức hay trang quét. Bước tiếp theo là cài nó và chạy thử trên một trong các tài liệu của chính bạn:
pip install marker-pdf
marker_single /path/to/your/file.pdf
- Tham gia nhóm Telegram tiếng Anh của dibi8 để nhận tin về các công cụ AI mã nguồn mở.
- Đọc tiếp: các hướng dẫn liên quan trên dibi8.
Nguồn & Đọc thêm:
- Kho mã GitHub: https://github.com/datalab-to/marker
- Tài liệu chính thức / README: https://github.com/datalab-to/marker#readme
Một số liên kết ở trên là liên kết tiếp thị liên kết. dibi8.com có thể nhận được hoa hồng nếu bạn đăng ký, mà bạn không phải trả thêm chi phí nào. Điều này giúp duy trì hoạt động của trang web và giữ cho nội dung được miễn phí.
💬 Bình luận & Thảo luận