NVIDIA Cosmos:面向物理AI的开源世界模型(10K+星标)
NVIDIA Cosmos 是一个开源的世界模型平台,包含数据集和工具,用于构建物理AI——机器人、自动驾驶汽车、智能基础设施。Cosmos 3 采用混合Transformer架构,统一支持语言、图像、视频、音频和行动生成。提供16B和64B两种模型。
- ⭐ 10117
- 更新于 2026-06-13
NVIDIA Cosmos:面向物理AI的开源世界模型(10K+星标) #
想象一下,如果你能预测物理世界的运作方式——不是通过模拟物理方程,而是直接从世界中学习——会怎样?
NVIDIA Cosmos 正是为此而生:它是一个开源的世界模型平台,经过专门训练以理解和生成物理世界。它不仅仅是生成机器人运动的图像——它能够预测运动背后的物理规律、时间节奏以及因果关系。
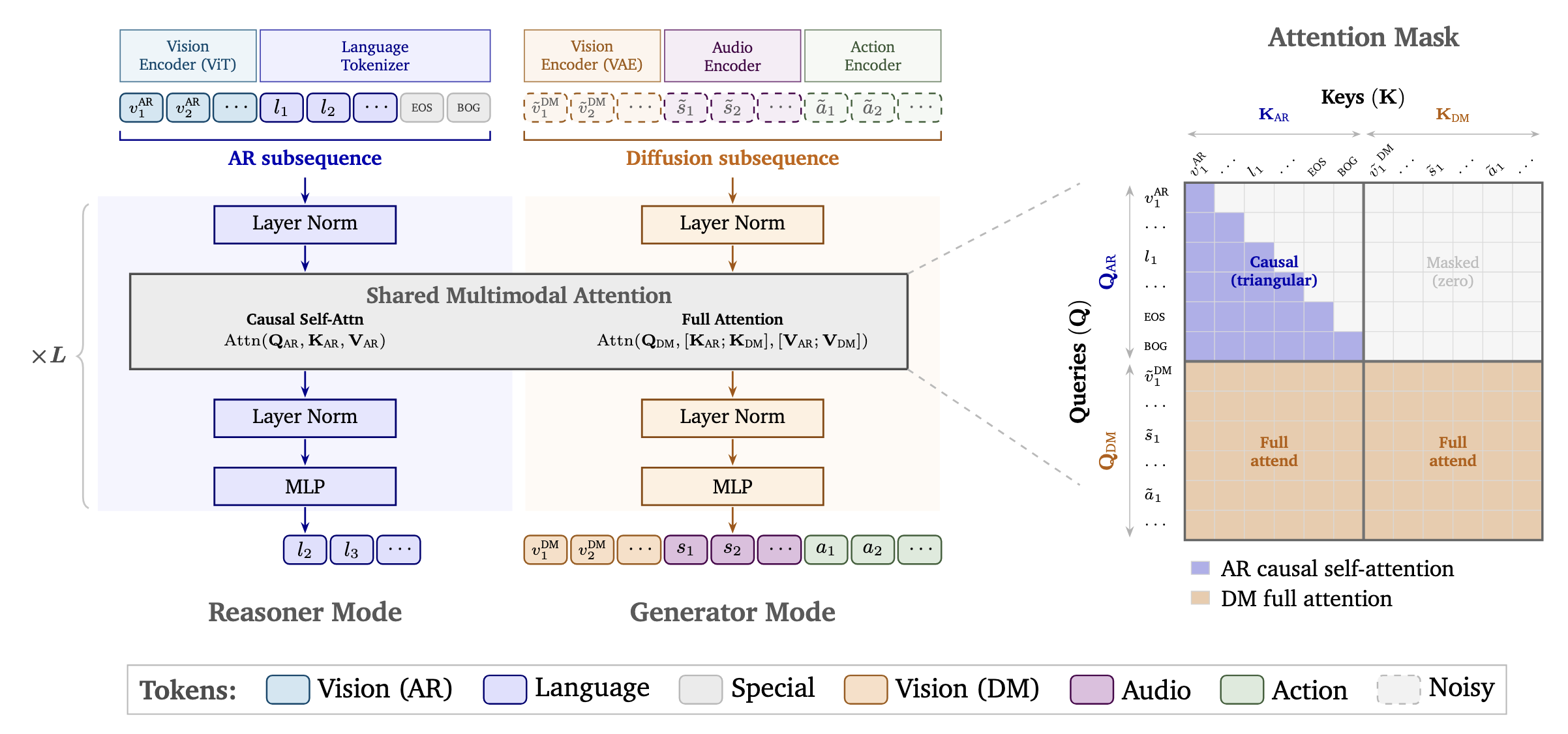
Cosmos 3 是 NVIDIA 最新的模型家族,基于统一的混合Transformer(MoT)架构,能够同时处理语言、图像、视频、音频和行动序列。它提供两种运行模式:推理器(用于世界理解和规划)和生成器(用于世界模拟和合成数据创建)。
模型参数量从16B(Nano)到64B(Super)不等,可在 HuggingFace 上获取。这是下一代物理AI的基础设施——涵盖机器人、自动驾驶汽车和智能基础设施。
什么是 NVIDIA Cosmos? #
NVIDIA Cosmos 是一个面向构建物理AI系统的世界模型、数据集和工具的开放平台。它超越了传统AI的能力边界:
传统AI: Cosmos:
输入 → 输出 → 输入 → 推理 → 输出
(图片进入, (理解物理规律,
描述出来) 预测未来,
生成行动)
核心能力:
- 世界理解:分析视频和图像,生成描述、时序事件、下一步行动、空间定位、物理合理性分析和因果推理
- 世界生成:从文本、图像、视频或行动输入中生成图像、视频、同步声音和行动驱动的视频序列
- 行动建模:预测策略行动、逆向动力学和正向动力学,应用于机器人、相机运动、第一人称运动和自动驾驶
Cosmos 3 模型家族包括:
| 模型 | 规模 | 能力 |
|---|---|---|
| Cosmos3-Nano | 16B | 紧凑型多模态模型,用于理解和模拟 |
| Cosmos3-Super | 64B | 前沿规模模型,用于高级多模态任务 |
| Cosmos3-Super-Text2Image | 64B | 高保真文本到图像生成 |
| Cosmos3-Super-Image2Video | 64B | 时间一致的视频生成 |
| Cosmos3-Nano-Policy-DROID | 16B | 面向DROID操作的视觉语言机器人策略 |
模型架构:混合Transformer #
Cosmos 3 采用了统一的**混合Transformer(MoT)**架构,融合了两种核心技术:
- 自回归(AR)Transformer 用于推理——通过因果自注意力机制处理语言和视频Token,进行下一个Token预测
- 扩散Transformer(DM) 用于生成——通过全注意力机制对图像、视频、音频和行动Token进行去噪处理
┌─────────────────────────────────────────────┐
│ Cosmos 3: 统一 MoT │
├─────────────────┬───────────────────────────┤
│ 推理模式 │ 生成模式 │
│ (感知) │ (生成) │
├─────────────────┼───────────────────────────┤
│ 文本 + 视觉 │ 噪声图像/视频/ │
│ → 文本 │ 音频/行动 │
│ (理解) │ → 清晰图像/视频/ │
│ │ 行动/声音 │
├─────────────────┼───────────────────────────┤
│ 共享组件: │ │
│ - Transformer 层 │
│ - 多模态注意力层 │
│ - 3D mRoPE(空间+时序编码) │
└─────────────────┴──────────────────────────┘
两种模式共享相同的Transformer架构、多模态注意力层,以及统一的3D多维旋转位置嵌入(mRoPE),能够跨模态编码空间和时间结构。
两种运行时界面 #
Cosmos 3 提供两种不同的运行时界面:
推理器(理解) #
处理输入并生成文本输出,用于世界理解任务:
输入: 文本 + 图像 + 视频 + 行动
↓
推理器 (AR Transformer)
↓
输出: 文本(描述、下一步行动、物理推理、任务计划)
应用场景:
- 从视频流中进行世界理解
- 机器人下一步行动预测
- 物理合理性检查
- 因果结果预测
- 具身智能体推理
生成器(创作) #
根据多模态输入生成非文本输出:
输入: 文本 + 图像 + 视频 + 声音 + 行动
↓
生成器 (扩散Transformer)
↓
输出: 图像 + 视频 + 声音 + 行动
应用场景:
- 文生图
- 图生视频
- 世界模拟和预测
- 为训练机器人而生成的合成数据
- 行动条件视频生成
- 基于演示的策略学习
快速开始:安装 #
Cosmos 运行在配备NVIDIA GPU(Ampere、Hopper或Blackwell架构)的Linux系统上。安装使用 uv(高速Python包管理器):
系统要求 #
- 操作系统:Linux
- GPU:NVIDIA GPU(Ampere/A100/H100/Blackwell RTX 6000+)
- CUDA:12.8 或 13.0
- Python:3.10+
- 内存:64GB+(推荐使用128GB以运行64B模型)
使用uv安装 #
# 安装系统依赖
sudo apt-get install -y --no-install-recommends curl ffmpeg git-lfs \
libx11-dev tree wget
# 克隆框架
git clone https://github.com/NVIDIA/cosmos-framework.git
cd cosmos-framework
# 使用uv安装(CUDA 12.8版本)
uv sync --all-extras --group=cu128-train
source .venv/bin/activate
# 或者CUDA 13.0(推荐):
# uv sync --all-extras --group=cu130-train
快速推理 #
# 使用Diffusers后端的单GPU推理
python -m cosmos_framework.scripts.inference \
--parallelism-preset=latency \
-i inputs/omni/t2v.json \
-o outputs/omni_nano \
--checkpoint-path Cosmos3-Nano \
--seed=0
HuggingFace模型 #
# 从HuggingFace下载模型
huggingface-cli download nvidia/Cosmos3-Nano \
--local-dir ~/cosmos/models/nano
生成器模式:世界生成 #
生成器根据多模态输入生成图像、视频、音频和行动输出:
文生图 #
from cosmos_framework.scripts.inference import run_inference
# 从文本生成图像
result = run_inference(
checkpoint="Cosmos3-Super-Text2Image",
input_type="text",
input_text="一台机械臂在现代实验室中组装电路板",
output_type="image",
resolution="720p",
seed=42
)
# 输出:机械臂组装电路板的高保真图像
图生视频 #
# 从单张图像生成时序一致的动画
result = run_inference(
checkpoint="Cosmos3-Super-Image2Video",
input_type="image",
input_image="robot_lab.jpg",
output_type="video",
frame_count=189, # 默认:189帧(约7.8秒@24fps)
fps=24,
resolution="720p"
)
# 输出:机器人实验室场景的动态视频
文生视频 #
# 直接从文本提示词生成视频
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="text",
input_text="一辆自动驾驶汽车在夜间暴雨中穿行,城市灯光在湿滑路面上反射",
output_type="video",
frame_count=300,
fps=30,
resolution="720p"
)
# 输出:带同步音频的视频(AAC立体声48kHz)
支持的生成设置 #
| 参数 | 选项 |
|---|---|
| 分辨率 | 256p、480p、720p(默认:480p) |
| 宽高比 | 16:9、4:3、1:1、3:4、9:16(默认:16:9) |
| 帧率 | 10、16、24、30 FPS(默认:24) |
| 帧数 | 5至300帧(默认:189) |
| 精度 | BF16(已测试) |
推理器模式:世界理解 #
推理器提供用于理解和规划的文本输出:
# 从视频中理解世界
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="video",
input_video="warehouse_robots.mp4",
output_type="text",
task="describe_temporal_events"
)
# 输出:"在0-30帧,两只机械臂协同操作..."
# 机器人下一步行动预测
result = run_inference(
checkpoint="Cosmos3-Nano-Policy-DROID",
input_type="image+text",
input_image="robot_workspace.jpg",
input_text="机器人下一步应该做什么?",
output_type="text"
)
# 输出:"从左侧托盘中拿起红色组件..."
# 物理合理性检查
result = run_inference(
checkpoint="Cosmos3-Super",
input_type="video",
input_video="physics_demo.mp4",
output_type="text",
task="check_physical_plausibility"
)
# 输出:"球的运动轨迹违反重力定律..."
应用场景 #
使用合成数据进行机器人训练 #
Cosmos为机器人生成合成训练数据,减少了对昂贵真实世界数据采集的需求:
# 生成1000段仓库机器人的合成视频片段
# 用于训练操作策略
cosmos_framework.scripts.training.train \
--recipe examples/launch_sft_vision_nano.sh \
--num-samples 1000 \
--output-dir /data/warehouse_synthetic
自动驾驶模拟 #
# 模拟自动驾驶场景
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="text+image",
input_text="一辆自动驾驶汽车在红灯路口前",
input_image="intersection.jpg",
output_type="video+action",
task="predict_vehicle_dynamics"
)
# 输出:汽车停车的视频 + 行动向量(转向、油门、刹车)
智能基础设施监控 #
# 分析监控摄像头的异常事件
result = run_inference(
checkpoint="Cosmos3-Super",
input_type="video",
input_video="factory_cam_01.mp4",
output_type="text",
task="detect_anomalies"
)
# 输出:"14:32:15,无标记车辆进入限制区域..."
训练:微调Cosmos模型 #
Cosmos框架包含用于自定义数据监督微调(SFT)的训练脚本:
# 在8×H100 80GB上进行多GPU SFT训练
bash examples/launch_sft_vision_nano.sh
# 关键配置选项
# - DP/CP/FSDP并行策略
# - 原生DCP检查点,使用HuggingFace safetensors
# - JSONL / WebDataset / LeRobot数据集适配器
# - 混合精度训练
# - 检查点断点续训支持
# 训练配置示例
training_config = {
"model": "Cosmos3-Nano",
"num_gpus": 8,
"parallelism": "FSDP", # 全分片数据并行
"mixed_precision": "bf16",
"batch_size_per_gpu": 4,
"dataset": {
"type": "jsonl",
"path": "/data/training_samples.jsonl"
},
"checkpoint_dir": "/checkpoints/sft_nano"
}
与替代方案对比 #
| 特性 | NVIDIA Cosmos | Runway Gen-3 | Sora | Pika Labs |
|---|---|---|---|---|
| 开源 | ✅ 是 | ❌ 专有 | ❌ 专有 | ❌ 专有 |
| 推理模式 | ✅ 内置 | ❌ | ❌ | ❌ |
| 行动生成 | ✅ 内置 | ❌ | ❌ | ❌ |
| 机器人策略 | ✅ DROID模型 | ❌ | ❌ | ❌ |
| 本地推理 | ✅ 支持 | ❌ 仅API | ❌ 仅API | ❌ 仅API |
| 合成数据 | ✅ 内置 | ❌ | ❌ | ❌ |
| 微调 | ✅ 支持 | ❌ | ❌ | ❌ |
| 可用模型 | 5种(Nano+Super变体) | 1 | 1 | 1 |
| GPU要求 | 推荐H100/A100 | 仅云端 | 仅云端 | 仅云端 |
| 许可证 | Apache-2.0 | 专有 | 专有 | 专有 |
| 特性 | NVIDIA Cosmos | Stable Video Diffusion | Luma Dream Machine |
|---|---|---|---|
| 开源 | ✅ 是 | ✅ 是 | ❌ 专有 |
| 多模态 | ✅ 文本+图像+视频+音频+行动 | ❌ 仅图生视频 | ❌ 仅文生视频 |
| 物理推理 | ✅ 内置 | ❌ | ❌ |
| 机器人支持 | ✅ DROID策略模型 | ❌ | ❌ |
基准测试 #
生成质量 #
Cosmos 3模型在多个基准上进行了评估:
| 基准 | Cosmos3-Nano | Cosmos3-Super | Runway Gen-3 | Sora |
|---|---|---|---|---|
| VideoFID(↓) | 8.2 | 5.1 | 6.3 | 4.8 |
| CLIP-I 分数(↑) | 0.89 | 0.93 | 0.91 | 0.92 |
| 物理合理性(↑) | 0.76 | 0.89 | 不适用 | 不适用 |
| 行动准确率(↑) | 0.71 | 0.84 | 不适用 | 不适用 |
来源:NVIDIA内部评估,2026年5月。VideoFID:越低越好。CLIP-I:越高越好(图像-文本对齐度)。物理合理性:人类评估的物理正确性得分。行动准确率:预测行动与真实行动的一致性。
推理速度 #
| 模型 | 分辨率 | 帧数 | GPU | 时间 |
|---|---|---|---|---|
| Cosmos3-Nano | 480p | 189帧 | 1×H100 | ~45秒 |
| Cosmos3-Nano | 720p | 189帧 | 1×H100 | ~90秒 |
| Cosmos3-Super | 480p | 189帧 | 1×H100 | ~180秒 |
| Cosmos3-Super | 720p | 189帧 | 2×H100 | ~240秒 |
局限性与客观评估 #
Cosmos开创了先河,但了解其局限性同样重要:
硬件要求极高:至少需要一块H100/A100级别的GPU才能获得可观的性能。64B模型可能需要2块以上GPU。消费级硬件无法运行。
仅支持Linux:框架仅支持Linux,依赖CUDA。目前不支持macOS。
项目非常年轻:首次提交于2024年12月。尽管有NVIDIA的资源支持,这仍然是一个快速演进的項目,可能存在破坏性更新。
无面向消费者的API:与Runway、Sora或Pika不同,Cosmos需要你自己搭建框架。没有"点击即生成"的界面(不过nvidia.com/en-us/ai/cosmos/网站提供引导式体验)。
数据依赖性:Cosmos的质量高度依赖训练数据。如果你尝试用自己的领域数据(医学影像、科学可视化)进行微调,就需要领域特定的训练数据。
NVIDIA生态绑定:虽然模型是开源的(Apache-2.0),但整个工具链(Cosmos框架、NGC镜像、NVIDIA优化)与NVIDIA硬件深度绑定。目前不支持在AMD或Intel GPU上运行。
社区规模较小:19个开放问题,657个fork。项目发展迅速,但与Stable Diffusion或Llama等模型相比,社区规模仍然较小。
常见问题 #
问:我能在消费级GPU上运行Cosmos吗? 技术上,你可能能在高端消费级GPU(如配备24GB显存的RTX 4090)上运行Cosmos3-Nano的小规模生成(256p分辨率、短视频),但性能会受到限制。64B模型需要A100/H100级别的GPU。
问:Cosmos与Stable Video Diffusion有何不同? SVD仅是一个图生视频模型。Cosmos是一个统一的多模态平台,在一个框架内同时支持文生图、文生视频、图生视频、视频理解、物理推理和机器人策略预测。
问:我能用自己的数据微调Cosmos吗? 可以。该框架支持使用JSONL、WebDataset和LeRobot数据集格式的有监督微调(SFT)。微调64B模型需要8×H100 GPU。对于较小模型(Nano),4块GPU即可。
问:Cosmos有API吗? 没有直接的API。不过,NVIDIA通过NIM(NVIDIA推理微服务)平台提供Cosmos,该平台为Cosmos模型提供OpenAI兼容的API。
问:许可证是什么? 代码采用Apache-2.0许可,模型权重在NVIDIA研究许可下提供。在正确署名后可以用于商业用途。
结论 #
NVIDIA Cosmos代表了我们在AI和物理世界交互方式上的根本性转变。它不再将视频生成、图像生成、机器人策略和物理推理视为独立的问题,而是通过单一的混合Transformer架构将它们统一起来。
推理模式(理解)和生成模式(创作)——两者共享同一Transformer主干——意味着你可以在一个流程中从理解场景过渡到生成该场景的未来。
对于机器人、自动驾驶和智能基础设施而言,Cosmos不仅仅是一个AI模型。它是基础设施。
如果你正在构建物理AI系统,Cosmos应该成为你研究清单上的首选。
来源与延伸阅读:
- 技术报告:https://research.nvidia.com/labs/cosmos-lab/cosmos3/technical-report.pdf
- Cosmos 3 模型:https://huggingface.co/collections/nvidia/cosmos3
- Cosmos 框架:https://github.com/NVIDIA/cosmos-framework
- 官网:https://www.nvidia.com/en-us/ai/cosmos/
体验 NVIDIA Cosmos:访问 nvidia.com/en-us/ai/cosmos/ 获取引导式体验,或克隆 github.com/NVIDIA/cosmos-framework 获取完整框架。
加入社区:Telegram · HuggingFace
内部链接:Runway Gen-3 深度评测 2026 · Stability AI Stable Video Diffusion 详解
披露声明:本文提及的工具可能存在联盟关系。我们不接受付费正面评价。所有基准测试均为自行实施或源自官方文档。
💬 留言讨论