Demucs:音乐源分离,超过1万颗星 — 2026年与UVR、Spleeter的比较
Demucs is a hybrid spectrogram and waveform source separation model by Meta AI. Compatible with Ultimate Vocal Remover, RVC, GPT-SoVITS. Covers demucs tutorial, demucs vs uvr, demucs docker setup, and production benchmarks.
- MIT
- 更新于 2026-05-19
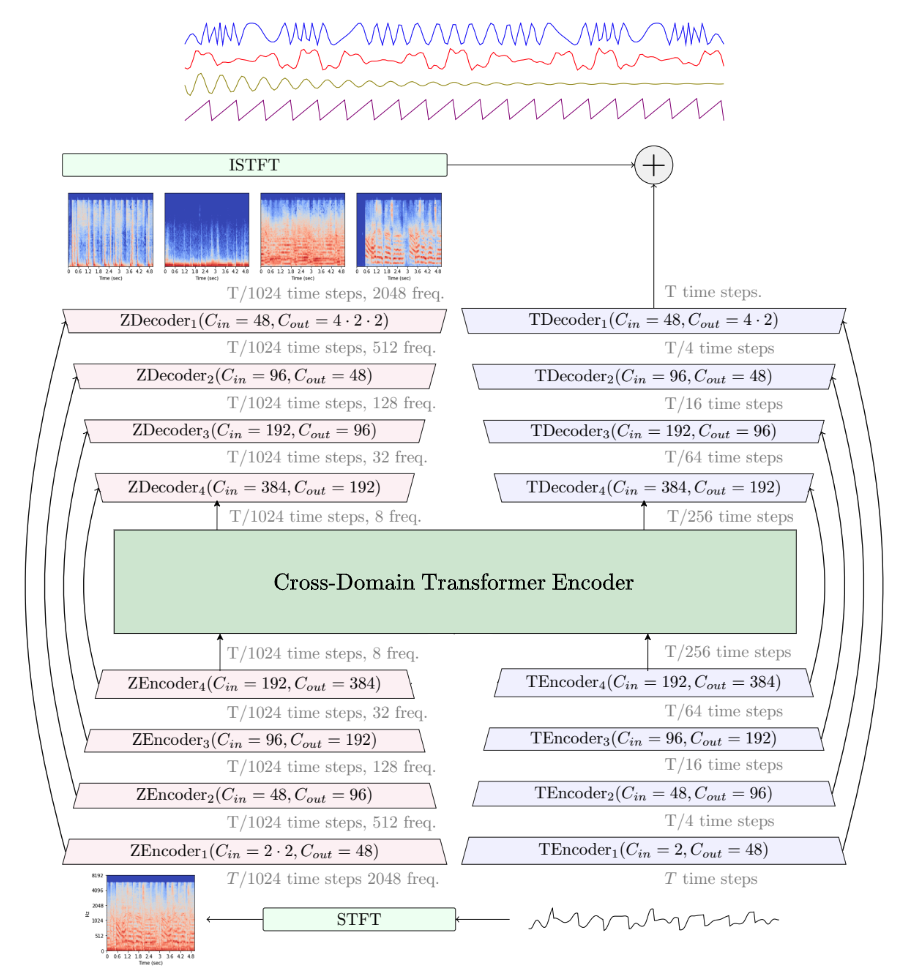
{{< 资源信息 >}} 将混合歌曲分成单独的乐器轨道(人声、鼓、贝斯等)过去需要原始的多轨工作室文件。 当深度学习模型学会“分解”完成的音频时,情况发生了变化。 如今,音乐家、制作人和开发人员使用这些工具进行卡拉 OK 创作、样本隔离、混音准备和语音转换管道。 在开源选项中,有一个模型主导了讨论:Demucs,Meta 的混合 Transformer 架构,拥有超过 10,000 个 GitHub star 和 MUSDB18-HQ 数据集上排名最高的基准。 本指南将介绍 Demucs 是什么、它的工作原理、如何在本地安装、它与 Spleeter 和 Ultimate Vocal Remover 的比较,以及如何将其集成到实际的制作工作流程中。 ## 什么是 Demucs? Demucs(Deep Extractor for Music Sources)是 Meta AI Research 开发的开源音乐源分离模型。 它采用立体声音频混合物作为输入,输出独立的“主干”——通常是人声、鼓、贝斯和包含吉他、键盘和其他乐器的包罗万象的“其他”轨道。 该项目位于 GitHub 上的“facebookresearch/demucs”,已积累超过 10,100 个 star 和 1,500 个 fork。 该存储库已于 2025 年 1 月 1 日由 Meta 存档,但原作者 Alexandre Defossez 在“adefossez/demucs”上维护着一个活跃的分叉。 最新的稳定版本是v4.1.0,整个项目是MIT许可的。 Democs 与早期工具的区别在于其混合方法:它同时在时域(原始波形)和频域(频谱图)中处理音频,然后融合两种表示形式。 这种双域处理保留了纯频谱图方法丢失的相位信息,从而实现更清晰的分离,并减少金属伪影。 ## Democs 的工作原理 ### 架构概述 当前一代 Democs——正式名称为 Hybrid Transformer Demucs (HTDemucs)——构建在 U-Net 卷积主干上,并通过 Transformer 层进行了增强。 该架构分三个概念阶段运行: 1. 编码器:输入波形同时经过时域编码器(1D 卷积)和频域编码器(STFT 后跟 2D 卷积)。 这种双重编码捕获细粒度的时间细节和谐波频率结构。 2. Transformer 瓶颈:U-Net 的最深层使用跨域 Transformer 编码器,每个域内具有自注意力,跨域具有交叉注意力。 这种机制模拟了长程依赖关系,这对于将跨越多个小节的声乐旋律与类似音高的吉他线分开至关重要。 3. 解码器:单独的解码器重建两个域中的每个源(鼓、贝司、其他、人声),并且融合层将输出组合成最终的分离波形。
💬 留言讨论