浑元视频:12.1K+ 星标 — 生产部署指南 2026
HunyuanVideo (HYV) is an open-source video generation framework by Tencent with 13B parameters. Supports ComfyUI, Diffusers, Gradio API. Covers Docker setup, FP8 quantization, multi-GPU inference, and production hardening.
- Apache-2.0
- 更新于 2026-05-19
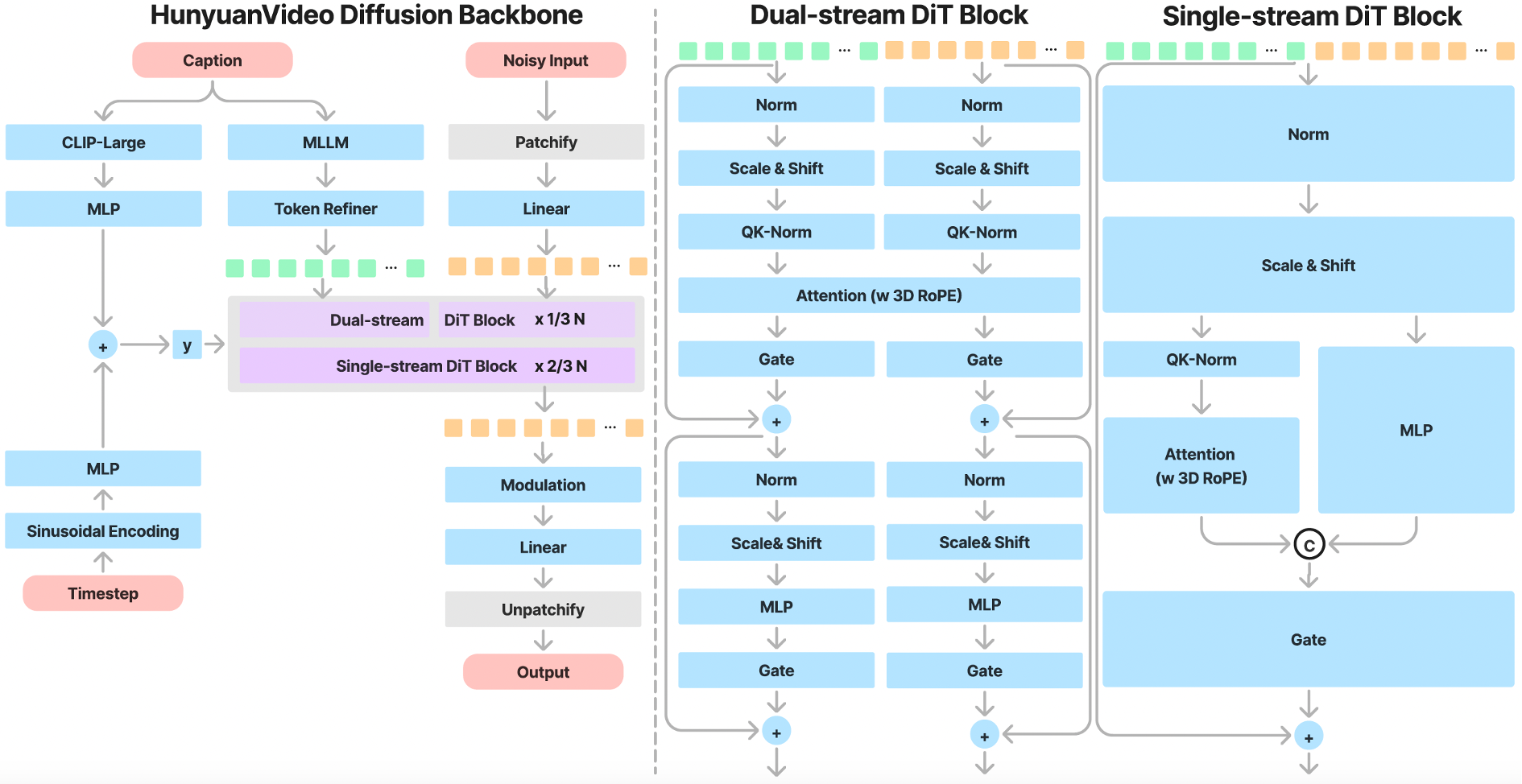
{{< 资源信息 >}} 需要 60GB VRAM 才能播放 5 秒 720p 剪辑的视频生成模型不是玩具,而是基础设施。 腾讯的混源视频是一款用于视频生成的 130 亿参数的补丁,已积累了超过 12,100 个 GitHub star,成为需要在自托管硬件上进行电影质量视频合成的团队的首要任务。 本 hunyuanvideo 教程将介绍完整的生产设置:从 hunyuanvideo Docker 部署到 FP8 量化、多 GPU 硬件推理、ComfyUI 集成以及大规模服务视频生成生产工作负载时所需的监控。 ## 混元视频是什么? 混源视频是腾讯公司开发的大型视频生成模型的系统框架。 原始版本(2024年12月)具有13B参数扩散变压器(DiT),可根据文本提示或参考图像生成720p视频剪辑。 2025年11月的后续版本HunyuanVideo-1.5将参数更新至8.3B,同时引入SSTA(选择性和滑动平铺焦点)机制并内置超分辨率升级器至1080p。 该版本均获得 Apache-2.0 许可,并在配备 NVIDIA GPU 的 Linux 上运行。 本 hunyuanvideo 我们的指南主要讲述了手动安装路径和 Docker 安装路径。 ## 混源视频的工作原理架构遵循包含三个主要组件的潜在扩展管道:

### 在 Ubuntu 上手动安装 #bas h
克隆存储库 git 克隆 https://github.com/Tencent-Hunyuan/HunyuanVideo.git cd混源视频 # 创建conda环境 conda create -n 混元 python==3.10.9 -y conda激活浑源 # 安装带有 CUDA 12.4 的 PyTorch conda安装pytorch==2.6.0 torchvision==0.19.0 torchaudio==2.4.0 \ pytorch-cuda=12.4 -c pytorch -c nvidia -y # 安装Python依赖项 python -m pip install -r requests.txt # 安装Flash Attention v2进行加速 python -m pip 安装 ninja python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3 # 安装xDiT进行多GPU硬件推理 python -m pip install xfuser==0.4.0 ### 下载模型权重 #
bas h
安装huggingface-cli pip 安装 Huggingface_hub # 下载主要的 DiT 权重 Huggingface-cli 下载腾讯/混元视频 \ –include“mp_rank_00_model_states.pt”\ –local-dir ./ckpts # 下载 FP8 量化权重(节省约 10GB VRAM) Huggingface-cli 下载腾讯/混元视频 \ –include“mp_rank_00_model_states_fp8.pt”\ –local-dir ./ckpts # 下载文本编码器模型 Huggingface-cli 下载腾讯/混元视频 \ –include“text_encoder”\ –local-dir ./ckpts ### 第一次推理运行 #
bas
h
conda激活浑源 python 样本_视频.py \ –视频大小 720 1280 \ –视频长度 129 \ –推断步骤 50 \ –提示“一只猫在草地上行走,写实风格,黄金时刻灯光”\ –流-方向 \ –use-cpu-offload \ –保存路径./结果 “--use-cpu-offload”标志对于 VRAM 小于 80GB 的 GPU 至关重要。 它在不使用时将模型权重卸载到系统RAM,以快速换取内存。 ## 与流行工具集成 ### ComfyUI(本机节点) ComfyUI 于 2025 年年初添加了原生视频支持。 从 Comfy-Org 下载重新资源的模型文件:
bas
h
模型文件转到ComfyUI/models/ # - text_encoders/clip_l.safetensors # - text_encoders/llava_llama3_vision.safetensors #-diffusion_models/hunyuan_video_720p_bf16.safetensors # - vae/hunyuan_video_vae_bf16.safetensors ````通过将 #
JSON 拖入 ComfyUI 来加载官方工作流程。 关键节点是HunyuanVideoSampler、HunyuanVideoDecode和TextEncodeHunyuanVideo。 ### Kijai 的 HunyuanVideoWrapper(高级) For FP8 推理、视频到视频和图像到视频,请使用社区包装器:````
bas
h
通过 ComfyUI Manager 或 git 安装 cd ComfyUI/custom_nodes git 克隆 https://github.com/kijai/ComfyUI-HunyuanVideoWrapper.git # 安装依赖项 cd ComfyUI-HunyuanVideoWrapper pip install -r 要求.txt 从 Hugging Face 上的“Kijai/Hunyuan Video comfy”下载 FP8 权重将其放置在“ComfyUI/models/diffusion_models/”中。 ### 扩管器管道蟒蛇 #
从扩散器导入浑源VideoPipeline 导入火炬管道 = HunyuanVideoPipeline.from_pretrained( “腾讯/混源视频-1.5”, torch_dtype=torch.bfloat16, 变体=“fp8” ) pipeline.enable_model_cpu_offload() 视频=管道( Prompt=“一只猫在爵士乐俱乐部弹钢琴,温暖的灯光”,帧数=121,高度=720,宽度=1280,num_inference_steps=30,指导规模=6.0 ).frames[0] # 保存视频 将 numpy 导入为 np 从PIL导入图片 帧 = [(f * 255).astype(np.uint8) for f in video] 帧 = [Image.fromarray(f) 对于帧中的 f] 帧[0].保存(“输出.mp4”,save_all=真,附加图像=帧[1:],持续时间=67,循环=0 ) ### 广播 API 服务器
bas
h
启动Gradio服务器 python gradio_server.py –flow-reverse #或者绑定所有接口进行远程访问 SERVER_NAME=0.0.0.0 SERVER_PORT=8081 \ python gradio_server.py –flow-reverse –use-cpu-offload Gradio UI 显示提示、分辨率、帧数、CFG 比例和种子的参数。 对于Smashing访问,请检查浏览器中的网络选项卡,找到“/run/predict”端点并复制JSON负载。 ### DigitalOcean GPU Droplet 对于没有本地 GPU 硬件的团队,DigitalOcean GPU Droplet 提供 NVIDIA H100 和 A100 实例。 使用以下cloud-init部署HunyuanVideo: #
yam l #云配置 包更新:true 套餐: - docker.io - nvidia-Container工具包 运行命令: - systemctl 重新启动 docker - docker pull hunyuanvideo/hunyuanvideo:cuda_12 - docker run -d –gpus all –name hunyuan \ -p 8081:8081 -v /mnt/models:/models \ 混源视频/混源视频:cuda_12 \ python gradio_server.py –flow-reverse –use-cpu-offload ```` ## 基准/实例 RTX 4090 和数据中心 GPU 测试的社区基准(2026 年 3 月): | 型号| 参数| 显存(720p) | 生成时间(5秒,RTX 4090)| 审美品质| |
💬 留言讨论