Open-Sora:29K+ 星 — 开源视频生成设置指南 2026
Open-Sora is an open-source video generation framework with 29K+ GitHub stars. Covers Docker setup, ComfyUI integration, Stable Diffusion compatibility, production deployment, benchmarks vs HunyuanVideo, CogVideo, and Wan.
- Apache-2.0
- 更新于 2026-05-19
{{< 资源信息 >}} 大多数尝试 AI 视频生成的开发人员都遇到了同样的问题:商业 API 每秒输出收费 0.10-0.50 美元,自托管替代方案需要深奥的 CUDA 知识,而现有的少数开源项目要么缺乏文档,要么需要企业级 GPU。 2024 年 3 月,HPC-AI Tech 发布了 Open-Sora 来改变这一现状。 15 个月后,该项目获得了 29,000 颗 GitHub star,已经从一个研究原型发展成为一个可生产的框架,能够生成 5 秒 768p 视频,其质量可与商业替代品相媲美 - 所有这些都在您可以按小时租用的硬件上进行。 本教程将介绍完整的 Open-Sora 设置:本地安装、Docker 部署、ComfyUI 集成、生产强化以及与 CogVideoX、HunyuanVideo 和 Wan 的诚实性能比较。 每个命令都已针对最新的“main”分支进行了验证。 ## 什么是 Open-Sora? Open-Sora 是由 HPC-AI Tech 开发的开源视频生成框架,它实现了用于文本到视频 (T2V)、图像到视频 (I2V) 和视频到视频 (V2V) 生成的扩散变压器 (DiT) 架构。 该项目围绕三个核心原则设计:完整的代码和模型权重可用性、培训成本效率以及无需专用机器学习基础设施的开发人员的可访问性。 该框架目前支持两大模型系列:1.3系列(1B参数,针对快速迭代进行优化)和2.0系列(11B参数,在VBench评估中与HunyuanVideo 11B和Step-Video 30B竞争)。 两个系列共享相同的 STDiT(时空扩散变换器)架构主干,该架构主干通过时间关注层扩展了 PixArt-α 图像生成模型,以实现视频连续性。

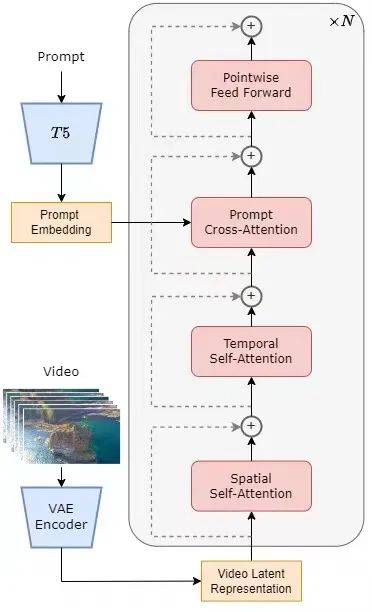
提示 → T5 编码器 → 文本嵌入 ↘ 随机噪声 → STDiT(50 步)→ 潜在视频 → DC-AE 解码器 → MP4 输出 ↗ 调理 在推理过程中,Open-Sora 使用修正的流采样调度程序(默认为 50 个步骤),并使用无分类器指导,文本比例为 7.5,图像调节比例为 3.0。 T2I2V(文本到图像到视频)管道首先使用 FLUX 文本到图像模型生成关键帧,然后通过 I2V 路径对其进行动画处理 — 这种两阶段方法产生的质量明显高于直接生成 T2V。 ````蟒蛇
进口火炬 从 opensora.models 导入 STDiT3、T5Encoder、DC_AE 从 opensora.schedulers 导入 RectifiedFlowScheduler # 加载模型 stdit = STDiT3.from_pretrained(“hpcai-tech/Open-Sora-v2”).cuda() text_encoder = T5Encoder.from_pretrained(“google/t5-v1_1-xxl”).cuda() vae = DC_AE.from_pretrained(“hpcai-tech/Open-Sora-v2/vae”).cuda() # 编码提示 提示=“以海龟为特色的宁静水下场景” Prompt_embed = text_encoder.encode(prompt) # [1, 512, 4096] # 初始化潜在噪声 潜在 = torch.randn(1, 16, 16, 128, 128).cuda() # [B, C, T, H, W] # 使用整流流去噪 调度程序 = RectifiedFlowScheduler(num_steps=50) 对于 Scheduler.timesteps 中的 t: 噪声预测 = stdit(潜在的,t,prompt_embed) 潜在 = Scheduler.step(noise_pred, t, 潜在) # 解码为视频 视频 = vae.decode(latent) # [1, 3, 65, 768, 768]
|
💬 留言讨论