VideoReTalking:7.2K+ 星 — AI 口型同步视频编辑设置指南 2026
VideoReTalking (VRT) is an audio-based lip synchronization system for talking head video editing. Compatible with RVC, GPT-SoVITS, and Coqui TTS. Covers installation, inference, Gradio WebUI, production deployment, and benchmarks vs Wav2Lip and SadTalker.
- Apache-2.0
- 更新于 2026-05-19
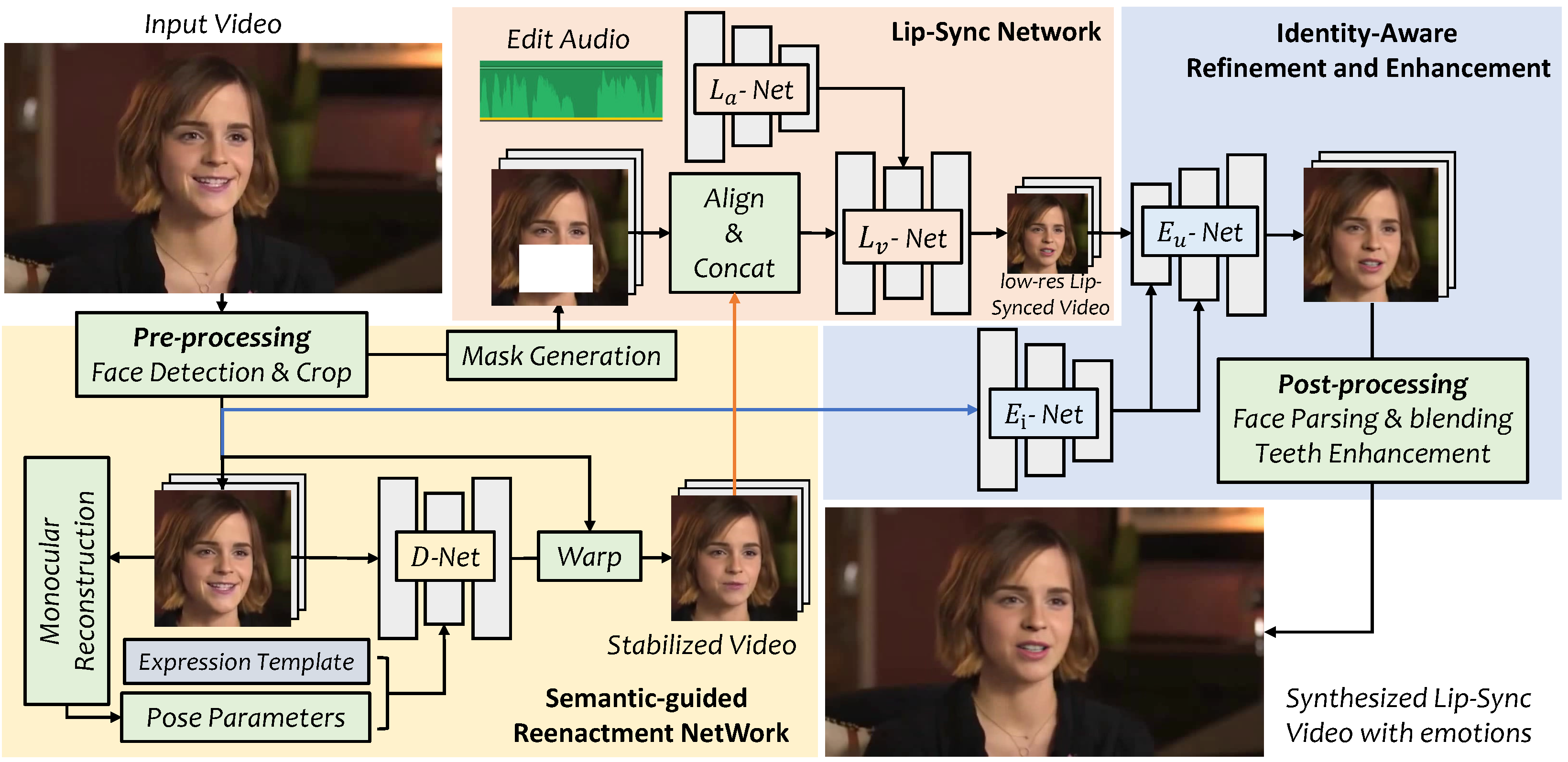
{{< 资源信息 >}} ## 介绍 多年来,用另一种语言配音视频同时保持嘴唇动作同步一直是后期制作的噩梦。 手动逐帧调整每分钟的镜头需要花费数小时,而且结果很少看起来自然。 2022 年,西安电子科技大学和腾讯人工智能实验室的研究人员在 SIGGRAPH Asia 上发布了 VideoReTalking,该系统通过编辑现有头部说话视频的下脸区域以匹配任何输入音频来实现自动化。 凭借 7,200 多名 GitHub 明星和完全开源的 Apache-2.0 许可证,它仍然是 2026 年最实用的自托管口型同步解决方案之一。 本指南将介绍完整的 VideoReTalking 教程:安装、推理、Gradio UI 设置、TTS 集成和生产部署。 ## 什么是 VideoReTalking? VideoReTalking 是一个基于 PyTorch 的推理管道,它将说话的头部视频和目标音频剪辑作为输入,然后生成口型同步的输出视频,其中主体的嘴部动作与新音频相匹配。 与从头开始生成视频的文本到语音化身不同,VideoReTalking 可以处理现有的素材——保留原始灯光、背景、头部姿势和视觉质量,同时仅修改嘴唇区域。 ## VideoReTalking 的工作原理 VideoReTalking 使用三阶段架构,将表达、口型同步和增强分解为单独的模块: ### 第 1 阶段:D-Net — 表达标准化 D-Net(表情编辑网络)获取输入视频并将所有帧中的面部表情标准化为中性模板。 它使用基于 DECA 的人脸重建从每帧中提取 3DMM 系数,用预定义的中性模板替换表情参数,并合成稳定的视频。 此步骤可防止口型同步网络受到原始嘴部动作的影响。 ### 第 2 阶段:L-Net — 音频驱动唇形同步 L-Net(唇形同步网络)接收表情标准化视频和目标音频。 它使用基于 Wav2Lip 的生成器和视听特征融合来生成与输入音频相匹配的嘴唇运动。 该网络输出嘴唇同步的视频,但嘴部区域的视觉保真度可能较低。 ### 第 3 阶段:E-Net — 面部增强 E-Net(增强网络)使用 GFPGAN 和 GPEN 人脸恢复模型来提高照片真实感。 它执行身份感知面部增强,使用拉普拉斯金字塔混合将增强的面部混合回原始帧,并在整个管道中保留主体的身份特征。

💬 留言讨论