TradingAgents:82,000星LLM多代理交易框架 — 2026年实用指南
TradingAgents 是Open Source的 LLM 多智能体框架(82,254 GitHub stars,Apache-2.0),模拟一家交易公司:分析师、研究员、交易员、风控智能体辩论出 BUY/SELL/HOLD 决策。基于 LangGraph。涵盖安装、智能体流水线、CLI + Python API,以及与 Qlib、单智能体 bot 的诚实对比。
- Apache-2.0
- 更新于 2026-06-02
引言 #
大多数"AI 交易 bot"项目就是一个 LLM 套一句"判断要不要买"的提示词。可一旦true要做决策——查基本面、扫新闻、多空对辩、风控签字——这种单脑结构立刻崩。true实的交易台从不靠一个大脑,而是靠一个会吵架的团队。
TradingAgents 把这件事照字面做了出来。它是个Open Source框架,拥有 82,254 个 GitHub star、Apache-2.0 许可,由 TauricResearch 维护,把一家交易公司建模成一队各司其职的 LLM 智能体——它们把研究沿流水线层层传递,辩论之后才给出 BUY/SELL/HOLD 决策。本文讲清楚智能体流水线怎么串、怎么安装运行(CLI 和 Python),以及与 Qlib、单智能体 bot 的诚实对比。
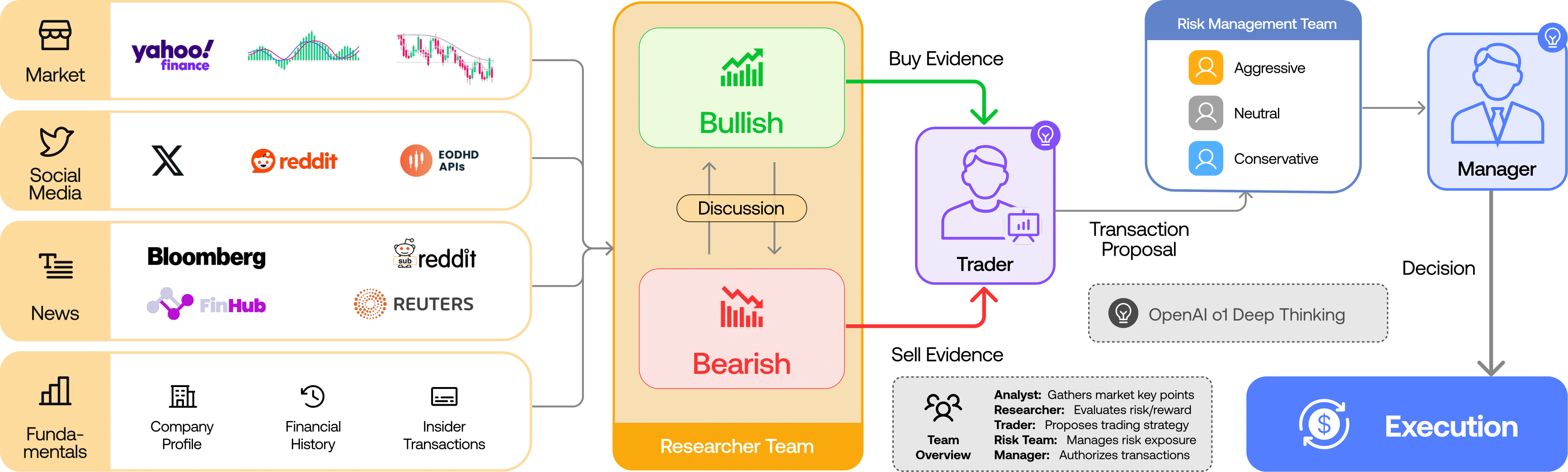
TradingAgents 模拟一家交易公司:分析师 → 研究员(多空)→ 交易员 → 风控团队 → 组合经理(来源:TauricResearch/TradingAgents,via dibi8 分析)
什么是 TradingAgents? #
TradingAgents 是一个多智能体 LLM 框架,模拟true实交易公司的工作流,为给定的股票和日期产出一个经过研究的交易决策。不是让一个模型瞎猜,而是各个专职智能体各做一件事、把发现往下传、在敲定前把这个决策吵明白。
它是一个研究框架,由 Tauric Research 社区构建,用来研究 LLM 智能体如何协作做金融推理——不是开箱即用的印钞机,也明确不构成投资建议。它用 Python 编写,构建在 LangGraph 之上,由 LangGraph 编排智能体图和状态传递。
TradingAgents 如何工作 #
这个框架是一条有向的智能体团队流水线。每一阶段把原始数据收窄成一个站得住脚的决策。
- 分析师团队 —— 四个专家收集证据:基本面分析师(财报、比率)、情绪分析师(社交/Reddit 信号)、新闻分析师(宏观 + 公司新闻)、技术面分析师(MACD、RSI 等价格指标)。
- 研究团队 —— 一个看多研究员和一个看空研究员就分析师的发现辩论数轮,把双方最强的论据都摆出来。
- 交易员 —— 把辩论综合成一个具体的交易方案(方向 + 理由)。
- 风控团队 —— 激进、中性、保守三种风险偏好的智能体从不同角度压力测试这个方案。
- 组合经理 —— 批准或否决,产出最终的 BUY / SELL / HOLD 决策。

分析师团队收集基本面、情绪、新闻和技术面(来源:TauricResearch/TradingAgents,via dibi8 分析)
每个智能体都是一次带角色专属提示词的 LLM 调用,并能访问数据工具。LangGraph 管理共享状态,让后面的智能体看得到前面智能体的输出。
安装与设置 #
TradingAgents 需要 Python 3.10+。你克隆仓库、安装依赖;它需要两个 API key——一个 LLM 供应商(默认 OpenAI)和用于金融数据的 FinnHub。
要把 TradingAgents 跑成定时的生产任务,你需要一台常开的机器——可以在 DigitalOcean 上开一台(新账户有免费试用额度),或者用 HTStack 的低延迟香港 VPS(和 dibi8.com 同一个 IDC)。
a
s
h
# 1. 克隆
git clone https://github.com/TauricResearch/TradingAgents.git
cd TradingAgents
# 2. 隔离环境(conda 或 venv)
conda create -n tradingagents python=3.10 -y && conda activate tradingagents
# 3. 安装依赖
pip install -r requirements.txt
更喜欢用纯 virtualenv 而非 conda?都行:
a
s
h
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
把两个必需的 API key 设为环境变量:
a
s
h
export OPENAI_API_KEY=sk-your-key-here
export FINNHUB_API_KEY=your-finnhub-key # 免费档即可测试
或者放进本地 .env,省得每个 shell 都重新 export:
a
s
h
# .env (绝不要提交这个文件)
OPENAI_API_KEY=sk-your-key-here
FINNHUB_API_KEY=your-finnhub-key
如果报 KeyError: 'FINNHUB_API_KEY',是当前 shell 没 export 这个变量。如果 LLM 调用返回 429,是 OpenAI 那边限速了——放慢,或在配置里换模型(见下)。
核心用法 #
最快的路径是交互式 CLI,它会提示你输入股票代码和日期,并流式打印每个智能体的推理:
a
s
h
python -m cli.main
要做自动化,用 TradingAgentsGraph API 从 Python 驱动它。你传入股票代码和日期,拿回智能体状态加最终决策:
h
o
n
from tradingagents.graph.trading_graph import TradingAgentsGraph
from tradingagents.default_config import DEFAULT_CONFIG
ta = TradingAgentsGraph(debug=True, config=DEFAULT_CONFIG.copy())
# 按特定日期分析 NVDA(point-in-time,无前视)
_, decision = ta.propagate("NVDA", "2024-05-10")
print(decision) # -> BUY / SELL / HOLD + 理由
你通过配置控制成本和深度。TradingAgents 把工作拆给一个"深度思考"模型(重推理)和一个"快速思考"模型(便宜、高频调用):
h
o
n
config = DEFAULT_CONFIG.copy()
config["llm_provider"] = "openai"
config["deep_think_llm"] = "gpt-4o" # 用于辩论 / 硬推理
config["quick_think_llm"] = "gpt-4o-mini" # 用于常规智能体步骤
config["max_debate_rounds"] = 2 # 轮数越多越深但越贵
config["online_tools"] = True # 拉实时数据 vs 缓存
ta = TradingAgentsGraph(debug=True, config=config)
学习阶段把 max_debate_rounds 设低——每多一轮都会让整个智能体团队的 LLM 调用翻倍。
你也可以选择运行哪些分析师,在只关心比如基本面和新闻时省成本:
h
o
n
config["selected_analysts"] = ["fundamentals", "news"] # 跳过情绪 + 技术面
ta = TradingAgentsGraph(debug=True, config=config)
要筛一个自选股清单,对同一日期循环调用多个股票代码:
h
o
n
watchlist = ["NVDA", "AAPL", "TSLA"]
for ticker in watchlist:
_, decision = ta.propagate(ticker, "2024-05-10")
print(f"{ticker}: {decision.splitlines()[0]}") # 第一行 = 决策
返回的状态里存着完整辩论,让你能查为什么,而不只是是什么:
h
o
n
final_state, decision = ta.propagate("NVDA", "2024-05-10")
print(final_state["investment_debate_state"]["bull_history"]) # 看多论据
print(final_state["investment_debate_state"]["bear_history"]) # 看空论据
print(final_state["final_trade_decision"]) # 最终理由
集成 #
因为决策这一步就是一个返回 BUY/SELL/HOLD 加理由的 Python 调用,TradingAgents 嵌进流水线的研究那一半。它不自己下单——你把它的输出接到自己的执行或日志层:
h
o
n
_, decision = ta.propagate("AAPL", "2024-06-01")
if "BUY" in decision:
log_signal("AAPL", "BUY", source="tradingagents")
# 在这里转发给你的券商 / 模拟盘层
数据层也是可插拔的:FinnHub 提供基本面和新闻,价格/指标工具提供技术面,社交源提供情绪。
要每个交易日早上重新生成决策,用 cron 包一个脚本:
a
s
h
# 每个工作日 08: 00 跑自选股筛选
0 8 * * 1-5 cd /opt/TradingAgents && /opt/.venv/bin/python screen_watchlist.py >> /var/log/ta.log 2>&1
你不被 OpenAI 绑死——通过同样的配置把深度/快速模型指向别的供应商:
h
o
n
config["llm_provider"] = "anthropic"
config["deep_think_llm"] = "claude-sonnet-4-6"
config["quick_think_llm"] = "claude-haiku-4-5"
基准 & true实用例 #
TradingAgents 被当作研究测试台用:你回放一个历史日期,让智能体只基于当时可得的数据推理(point-in-time),然后研究决策和辩论记录。它true正的价值是可解释性——不像黑盒模型,每个决策都附带分析师的证据和多空论点,这也是为什么这个项目更多是用来研究 LLM 在金融里的推理,而不是即插即用的赚钱工具。
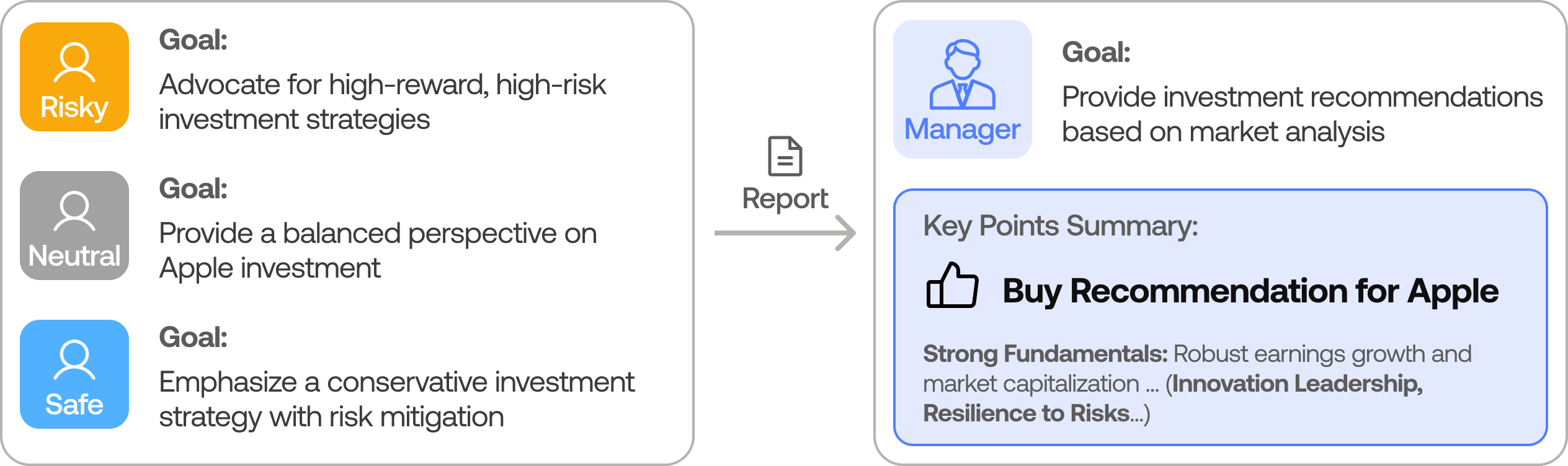
风控团队在组合经理签字前压力测试每一个交易方案(来源:TauricResearch/TradingAgents,via dibi8 分析)
一次完整运行返回一个决策加推理链,大致如下:
e
x
t
FINAL TRANSACTION PROPOSAL: BUY
Rationale: 基本面分析师指出数据中心营收加速;
多方论点(利润率扩张)经 2 轮辩论压过空方论点(估值);
风控团队:中性立场,仓位谨慎。组合经理:批准。
因为辩论记录被保存下来,你可以对比换模型或加辩论轮数时决策如何变化:
h
o
n
for rounds in (1, 3):
config["max_debate_rounds"] = rounds
ta = TradingAgentsGraph(config=config)
_, d = ta.propagate("NVDA", "2024-05-10")
print(rounds, "rounds ->", d.splitlines()[0])
与同类工具的对比 #
也可以看我们的 相关Open Source工具 报道。
TradingAgents、Qlib 和单智能体 bot 解决的是不同问题。这里讲清楚它们到底差在哪。
| 特性 | TradingAgents | Qlib | 单智能体 LLM bot | |—
|—
|—
|—
| | 方法 | LLM 多智能体辩论 | ML 因子模型 | 一个 LLM + 提示词 | | 核心单元 | 分析师/研究员/交易员/风控 智能体 | LightGBM/LSTM 信号 | 单次决策调用 | | 可解释性 | 高(完整辩论记录) | 中(特征重要性) | 低 | | 数据 | FinnHub + 新闻 + 情绪 + 技术面 | point-in-time 价格/因子库 | 你提示什么算什么 | | GitHub stars | 82,254 | 43,948 | 不一 | | 构建于 | LangGraph | 自研 Python | 不一 | | 最适合 | 研究 LLM 对一笔交易的推理 | ML 截面策略 | 快速 demo |
诚实总结:如果你要的是股票池上的统计信号,Qlib 是为此而生。如果你想研究一队 LLM 如何推理出一个带完整审计链的决策,TradingAgents 更有意思。它们互补,不是竞品。
局限 / 诚实评估 #
TradingAgents 覆盖面很广,但它不适合所有人,false装适合只会浪费你的时间。
- 不是投资建议,也不是实盘交易器。 它输出一个经过研究的观点;不下单、不做任何保证。仓库里写得很清楚。
- LLM 成本会累积。 一次带辩论轮的完整多智能体运行,对每支股票每个日期都是很多次 LLM 调用。盯着你的 OpenAI 账单。
- 决策质量取决于模型。 廉价的快速思考模型会降低分析质量;好结果的前提是有能力的深度思考模型。
- 数据覆盖有限。 FinnHub 免费档和情绪源都不完整;这些缺口会悄悄削弱分析。
- 回测要小心。 它按日期避免前视,但把智能体决策变成一个考虑手续费、可交易的策略是你的活,不是框架的。
如果你做的是 AI 驱动的加密策略,Minara(AI + 加密)走的是另一条赛道,而交易所原生的执行在 Binance。
结语 #
TradingAgents 是 2026 年研究"一队 LLM 智能体如何推理出一个交易决策"最有意思的Open Source项目——不是因为它印钞,而是因为它每一步都把过程摆出来给你看。审计链就是产品本身:你能精确看到哪个分析师提了哪个警示、多空双方怎么辩的、风控团队为什么那样定仓位。克隆它、用 CLI 跑一支股票、在你信任它产出的任何信号之前先读完整的辩论记录。
- 加入 dibi8 中文 Telegram 群,获取Open Source AI 工具更新和量化讨论。
- 延伸阅读:dibi8 上的相关指南。
- 在 DigitalOcean 上开一台研究机,今晚就跑你的第一次分析。
资料来源与延伸阅读:
- GitHub 仓库:https://github.com/TauricResearch/TradingAgents
- 官方文档 / README:https://github.com/TauricResearch/TradingAgents#readme
- LangGraph(编排):https://github.com/langchain-ai/langgraph
上方部分链接含联盟推广。如通过链接注册,dibi8.com 可能获得佣金,不影响你的成本。这帮助 dibi8 持续免费运营。
💬 留言讨论