exo:在您自己的设备上运行 Frontier AI(45K 星)
exo 把你的 Mac、PC 乃至手机组成一个集群,在本地运行前沿 AI 大模型。45,088 个 GitHub star,Apache-2.0 协议。涵盖安装、控制台、兼容 OpenAI/Claude/Ollama 的 API、true实命令以及一份诚实的横向对比。
- Apache-2.0
- 更新于 2026-06-02
引言 #
前沿大模型体积庞大。一个 671B 参数的模型根本塞不进一台笔记本,而要自己租足够的云端 GPU 来跑,开销又很快变得高昂。exo 走的是另一条路:它把你手上已有的设备——Mac、Linux 主机,甚至手机——拼成一个集群,再把模型切分到这些设备上,让它们协同完成推理。凭借 GitHub 上超过 45,000 个 star,它已经成为「在自己掌控的硬件上跑大模型」这条赛道上最受关注的项目之一。本指南会带你走一遍:安装 exo、打开控制台,并通过它那套兼容 OpenAI、Claude 和 Ollama 的 API 与之交互。
exo 是什么? #
exo 是一个Open Source工具,通过把若干设备组成一个分布式集群,在本地运行前沿 AI 大模型。它不会强迫单台机器装下整个模型,而是把模型的各层切分到它在网络中发现的每个节点上,于是一个对任何单台设备都太大的模型,依然跑得起来。
该项目由 exo-explore(exo labs)团队维护,以 Apache-2.0 协议发布,你可以自由使用、查看和修改源码。
exo 的工作原理 #
下面是 exo 在底层做的事:
- 本地执行:模型跑在你自己的设备上,提示词和数据不会离开你的网络,也省去了按 token 计费的云端成本。
- 自动组建集群:exo 会自行发现同一网络中其他正在运行 exo 的设备——既没有一份列出所有节点的配置文件,也不需要手写「主节点/工作节点」之类的设置。
- 拓扑感知的切分:exo 会实时测量每个节点的资源和延迟,据此决定如何把模型的各层切分到它们身上,让一个对任何单台机器都太大的模型也能在集群上运行。
结果就是:往网络里再加一台 Mac 或 PC,等于给集群多了一份可用的内存和算力,而你完全不必重写任何配置。
安装与配置 #
如果你希望 exo 全天候可达(比如做一个共享的内部端点),就需要一台常开的机器——可以在 DigitalOcean 上开一台(新账号有免费试用额度),或者用 HTStack 的低延迟香港 VPS(它和托管 dibi8.com 的是同一个 IDC)。关于 GPU 加速推理需要注意:exo 目前在 Apple Silicon 上才有 GPU 加速;Linux 暂时只能用 CPU 跑,GPU 支持还在开发中。
macOS 应用(最简单) #
在 Mac 上最省事的方式是用预编译好的应用。用 Homebrew 安装:
a
s
h
brew install --cask exo
或者直接从 https://assets.exolabs.net/EXO-latest.dmg 下载最新的 DMG。该应用需要较新版本的 macOS。
从源码编译(macOS 或 Linux) #
想跑最新代码,就克隆仓库并用 uv 启动。你需要先装好 uv、Node 18+ 以及 nightly 版的 Rust 工具链(macOS 上还需要 Xcode、Homebrew 和 macmon):
a
s
h
git clone https://github.com/exo-explore/exo
cd exo/dashboard && npm install && npm run build && cd ..
uv run exo
如果你用 Nix,可以完全跳过这些前置依赖:
a
s
h
nix run .#exo
常见错误与修复 #
首次运行时常见的一个坑是控制台打不开,原因是前端从没被编译过。Web 界面是从 dashboard/ 目录编译出来的,所以如果你克隆了仓库后直接 uv run exo 却没构建前端,先重新构建控制台再启动:
a
s
h
cd dashboard && npm install && npm run build && cd ..
uv run exo
如果安装过程中遇到其他问题,请查阅仓库里的官方 README。
- Image:
- Source: exo-explore/exo GitHub
核心用法 #
装好 exo 之后,整套流程短得令人愉快:在每台设备上把它启动起来,打开控制台,然后向它的 API 发请求。
启动一个节点 #
在你想加入集群的每台设备上启动 exo:
a
s
h
uv run exo
每个节点会自动找到同一网络里的其他节点——无需手动注册。有几个常用参数:
--no-worker:以「仅协调」模式运行该节点,它本身不参与推理。--legacy-daemon:让 exo 作为后台守护进程运行。
监控集群 #
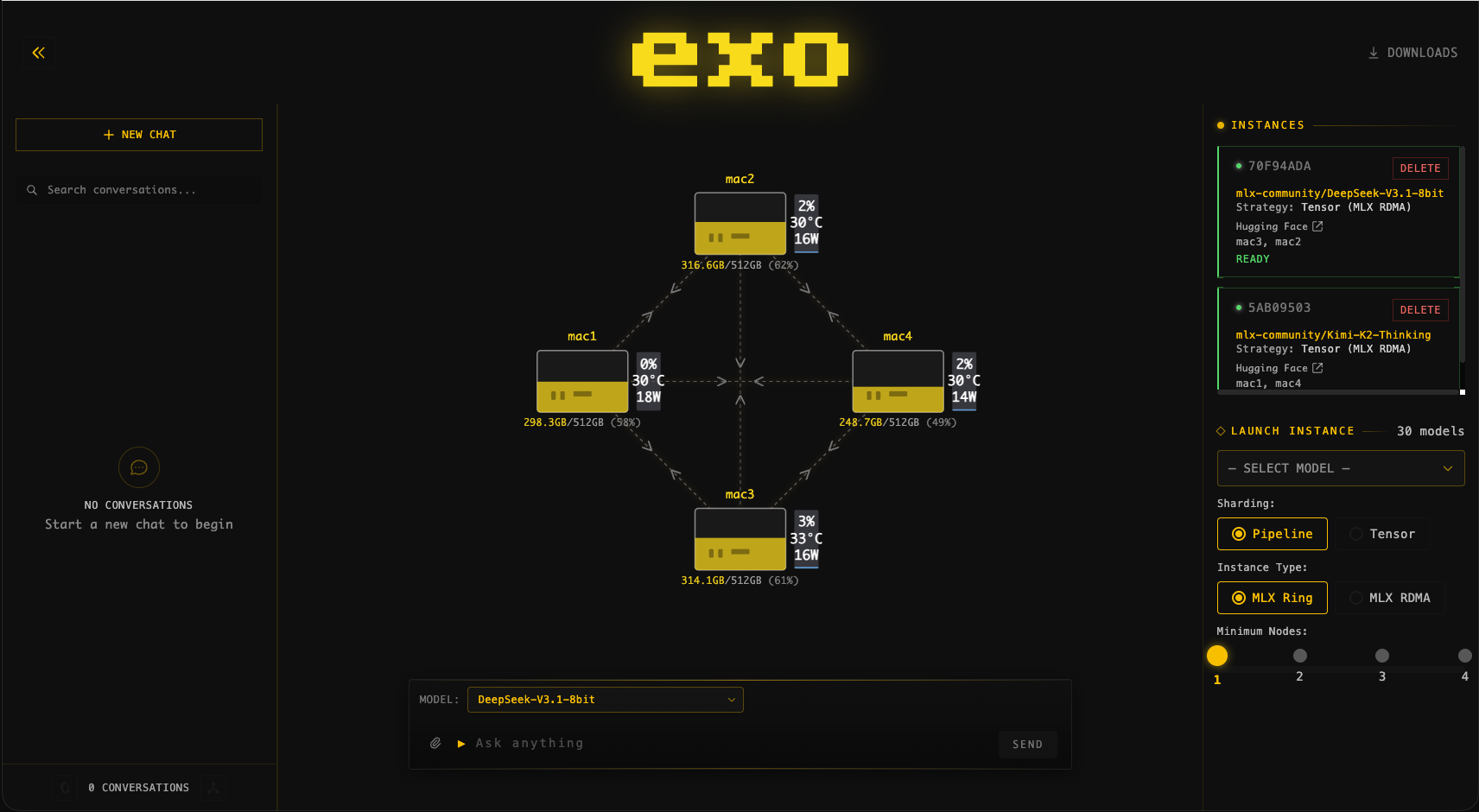
exo 在 52415 端口上提供一个控制台。在浏览器里打开:
h
http://localhost: 52415
你会看到 exo 发现的每一台设备、当前模型是如何切分到它们身上的,以及实时的吞吐量和内存占用。
调用模型 #
exo 暴露的 HTTP API 兼容 OpenAI、Claude(Anthropic Messages)和 Ollama 三种格式,因此现有的客户端代码大多无需改动就能用。一个流式聊天请求长这样:
a
s
h
curl -X POST http://localhost: 52415/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{"model": "model-id", "messages": [{"role": "user", "content": "prompt"}], "stream": true}'
同一个端点也能理解位于 /v1/messages 的 Claude Messages API,以及位于 /ollama/api/chat 的 Ollama API。
小结 #
整个循环就是这样:在每台设备上启动一个节点,在控制台里看着集群组建起来,然后让任何 OpenAI/Claude/Ollama 客户端指向它。由于这套 API 用的就是工具们早已会说的格式,把一个托管端点换成你自己的 exo 集群,往往只需改一行。
集成 #
由于 exo 会说 OpenAI、Claude 和 Ollama 的 API,它在大多数现有工作流里只需改一个 base URL 就能接入——不需要专门的 SDK。
复用你现有的 OpenAI 客户端 #
把任何兼容 OpenAI 的客户端指向本地的 exo 端点,就能直接用:
h
o
n
# 用标准 OpenAI 客户端访问本地 exo 集群
from openai import OpenAI
client = OpenAI(
base_url="http://localhost: 52415/v1",
api_key="not-needed", # 本地使用 exo 不需要密钥
)
response = client.chat.completions.create(
model="model-id",
messages=[{"role": "user", "content": "Summarize the exo project in one sentence."}],
)
print(response.choices[0].message.content)
在 Jupyter notebook 里使用 #
同一个客户端在 notebook 里也能用,很方便针对集群做快速实验:
h
o
n
# 在 Jupyter notebook 里做个快速测试
from openai import OpenAI
client = OpenAI(base_url="http://localhost: 52415/v1", api_key="not-needed")
response = client.chat.completions.create(
model="model-id",
messages=[{"role": "user", "content": "List three uses for a local AI cluster."}],
)
print(response.choices[0].message.content)
由于一切都走标准 HTTP API,任何能发 POST 请求的语言或框架都能与 exo 集成。
基准与true实使用 #
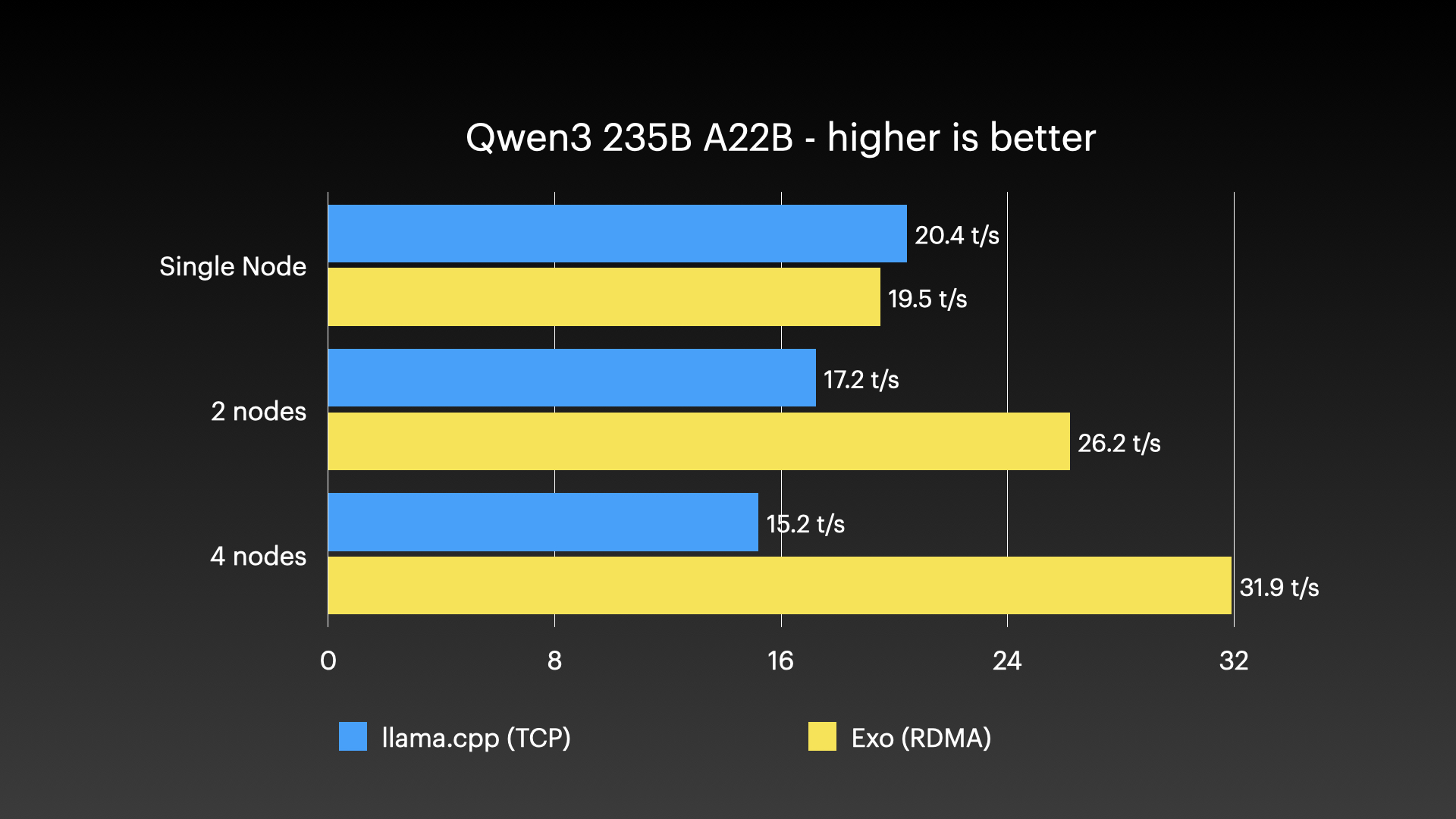
性能基准 #
exo 已经被演示用于在一批 Apple Silicon Mac 组成的集群上运行超大模型——这类负载是任何单台消费级机器都扛不下来的。下面的图片展示了true实的集群运行:
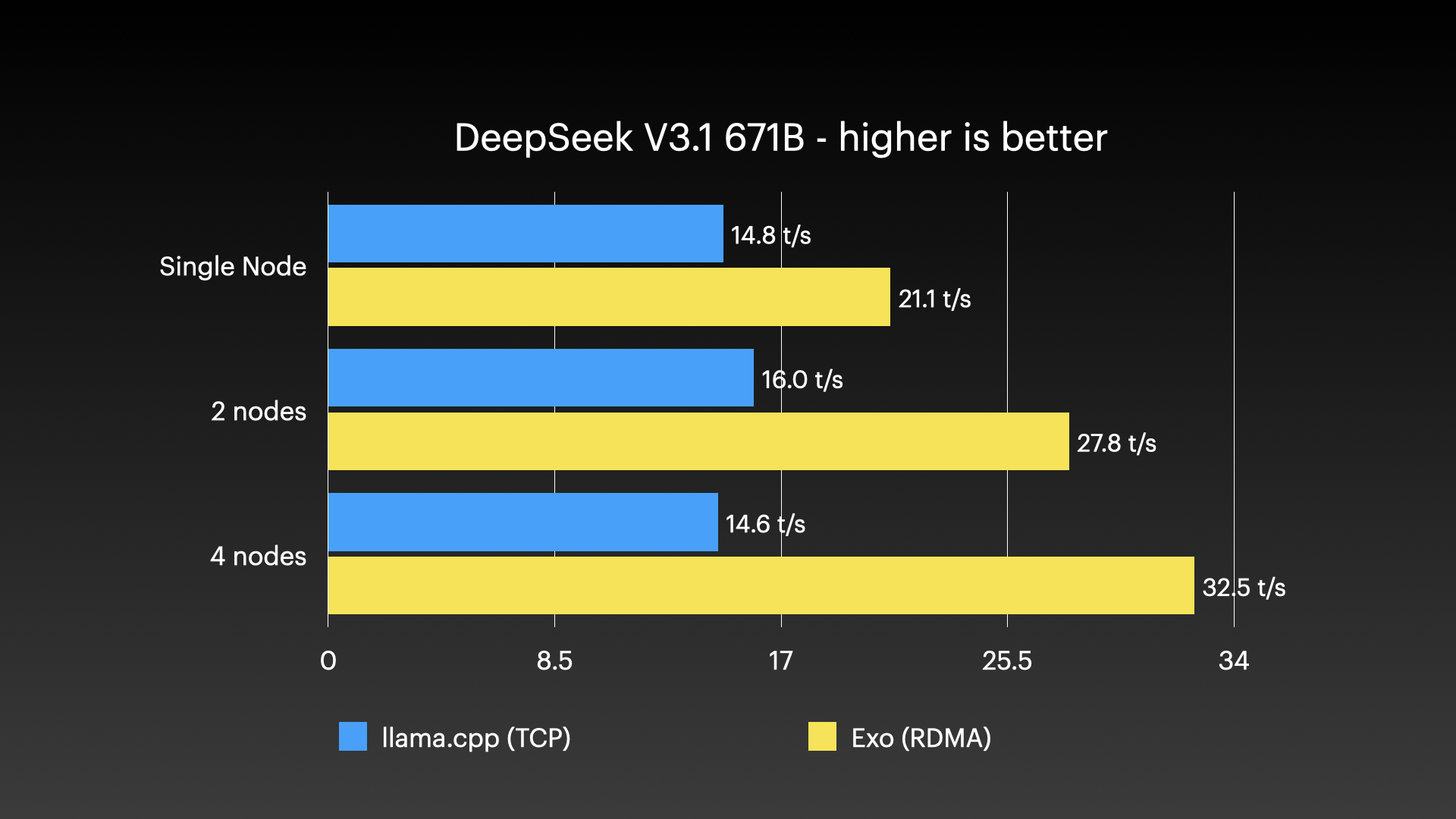
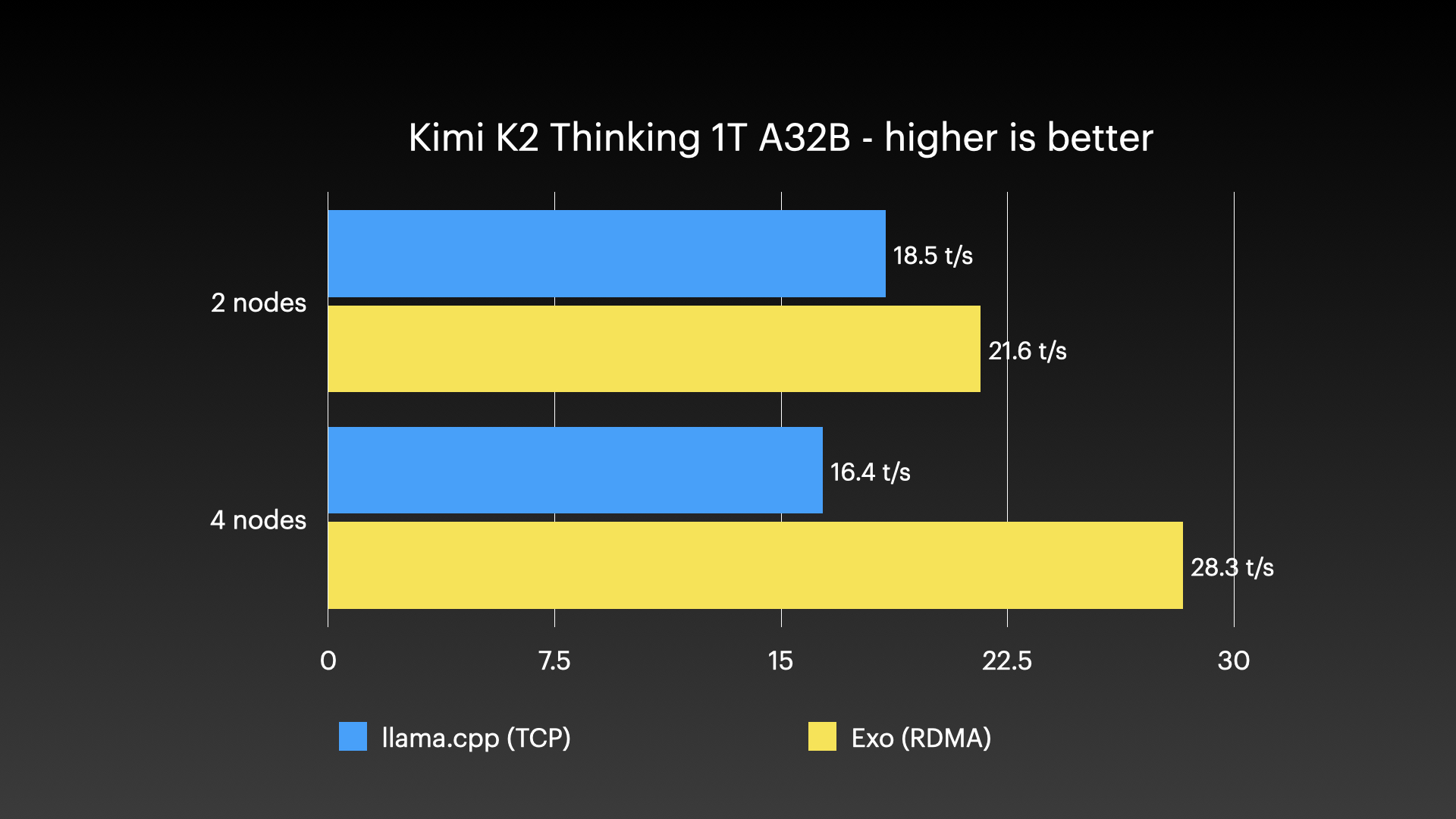
true实使用场景 #
私有的本地推理:在自己的硬件上运行前沿模型,让提示词和数据留在你的网络内。
运行单机装不下的模型:把多台设备的内存汇集起来,托管数千亿参数级别的模型。
集群监控:控制台用一个界面统一呈现每个节点、模型的切分方式以及实时吞吐量。
可直接替换的 API:因为 exo 镜像了 OpenAI、Claude 和 Ollama 的 API,只要改一个 base URL,它就能顶替一个托管端点。
Apple Silicon 实验室:手上有几台 Mac 的团队可以用 Thunderbolt 把它们串起来,用已有硬件搭出一个能打的推理集群。
与替代方案的对比 #
也可以看看我们对 相关Open Source工具 的报道。
exo 不是本地跑模型的唯一选择,而且它解决的是一个很具体的问题——把一个大模型摊到多台设备上——这是单机工具做不到的。下表大致勾勒出它与两种常见替代方案的差异:ollama/ollama(单机本地服务)和 ggml-org/llama.cpp(许多本地工具底层依赖的推理引擎)。
| 特性 | exo-explore/exo | ollama/ollama | ggml-org/llama.cpp | |———————-
|———————————-
|——————————–
|——————————–
| | 协议 | Apache-2.0 | MIT | MIT | | 主要语言 | Python / Rust | Go | C/C++ | | 多设备集群 | 支持(自动发现) | 不支持(单机) | 不支持(单机) | | GPU 加速 | Apple Silicon(Linux 暂为 CPU) | NVIDIA / Apple / 其他 | NVIDIA / Apple / CPU | | 安装方式 | 源码编译或 macOS 应用 | 一行安装 | 源码编译 | | API 兼容性 | OpenAI + Claude + Ollama | OpenAI + 原生 Ollama | 兼容 OpenAI 的服务端 | | 最适合 | 单台设备装不下的模型 | 轻松的单机本地服务 | 底层引擎 / 嵌入 | | 控制台 | Web 控制台(52415 端口) | CLI + REST API | CLI / 极简服务端 |
诚实的结论是:如果你的模型能舒舒服服地装进一台机器,那么像 Ollama 这样的单机工具更简单,而且在更多 GPU 上都有良好支持。exo true正的用武之地,是当模型对任何单台设备都太大、而你又想把多台机器——尤其是一组 Apple Silicon Mac——拼成一个集群的时候。
局限与诚实评估 #
exo 确实好用,但它是一个年轻且快速演进的项目。几点诚实的提醒:
Apple Silicon 是强势路线。 当前的 GPU 加速面向 Apple Silicon。Linux 暂时只能用 CPU 跑(GPU 支持还在路上),所以一台 Linux 的 GPU 机器未必有你预期的那么快。
它是为「大模型集群」而生。 如果你的模型本来就能装进一台机器,exo 那套分布式机制就显得多余了——单机工具会更简单。
源码编译有实打实的前置依赖。 从源码运行需要
uv、Node、nightly 版 Rust 工具链,macOS 上还要 Xcode 和额外工具。macOS 应用能省掉这些,但走源码路线的用户得做好比「一行安装」更重的配置准备。代码库变动快。 作为一个活跃开发中的项目,API 和行为可能在版本之间发生变化。如果你需要稳定性,请固定到一个已知可用的 commit。
依赖网络。 跨集群的性能取决于设备之间的链路;节点之间网络太慢会成为推理瓶颈——这正是为什么最快的方案要靠 Thunderbolt 连接。
这些取舍标出了 exo 可能不合适的地方,但也恰好衬托出它true正的强项:在你已有的硬件上,跑那些在别处根本跑不起来的模型。
结语 #
exo-explore 出品的 exo 是一个很有吸引力的工具,让你在自己的硬件上运行前沿 AI:超过 45,000 个 GitHub star、Apache-2.0 协议、自动组建集群,还有一套本就会说 OpenAI、Claude 和 Ollama 的 API。它的最佳应用场景,是通过汇集多台设备——尤其是 Apple Silicon Mac——来运行单机装不下的模型。顺理成章的下一步,就是装上应用或克隆仓库,在每台设备上启动一个节点,看着集群在控制台里组建起来。
- 加入 dibi8 英文 Telegram 群,第一时间获取Open Source AI 工具推送。
- 继续阅读:dibi8 上的相关指南。
Sources & Further Reading:
- GitHub repository: https://github.com/exo-explore/exo
- Official docs / README: https://github.com/exo-explore/exo#readme
以上部分链接为联盟(affiliate)链接。如果你通过它们注册,dibi8.com 可能获得一笔佣金,而你无需为此多付任何费用。这有助于维持本站运转、让内容保持免费。
💬 留言讨论