Marker:快速将PDF、DOCX和EPUB转换为Markdown/JSON
Marker(datalab-to/marker)能快速、准确地把 PDF、DOCX、EPUB 等文档转成 Markdown、JSON、HTML 和 chunks。35,694 个 GitHub star,代码采用 GPL-3.0 许可。涵盖安装、CLI 与 Python API、true实代码示例、LLM 模式,以及与同类工具的客观对比。
- GPL-3.0
- 更新于 2026-06-02
引言 #
把文档转成干净、结构化的文本,这件事听起来简单,可一旦true拿一份满是表格、公式和多栏排版的 PDF 来试,就知道没那么容易了。datalab-to/marker 正是为此而生:它通过一条深度学习流水线,把 PDF 以及许多其他类型的文档转成 Markdown、JSON、HTML 或适合 RAG 的 chunks,并可选地用一遍 LLM 来处理棘手内容。本指南会带你走一遍安装、命令行工具、Python API,以及与同类方案的客观对比,帮你判断它是否适合你的项目。
我们开始吧!
![]()
marker overview (source: datalab-to/marker repo, via dibi8 analysis)
marker 是什么? #
Marker 是 Datalab 出品的一款 Python 文档转换工具,能把 PDF(以及图片、PPTX、DOCX、XLSX、HTML 和 EPUB)转成 Markdown、JSON、HTML 和分块(chunks)输出。它在开发者中颇受欢迎,GitHub star 已超过 35,694。它不是单一的 OCR 步骤,而是一条流水线:先抽取文本,再检测页面版面与阅读顺序,清洗并格式化各个区块,还可以选择性地用 LLM 来提升表格、表单和行内公式的准确度。
marker 的工作原理 #
marker 的设计目标是快速、准确地把文档转成 Markdown、JSON、HTML 和 chunks。下面拆解一下这条流水线是怎么运转的:
- 文本抽取:能直接从文档取文字的就直接取,遇到扫描件或图片型页面则回退到 OCR。
- 版面与阅读顺序:深度学习模型会检测页面版面和正确的阅读顺序——多栏 PDF 之所以能输出得可读,靠的就是这一步。
- 区块清洗与格式化:每个区块(标题、段落、表格、公式、代码)都会被清洗并格式化,表格渲染为 Markdown/HTML,公式渲染为 LaTeX。
- 可选的 LLM 精修:加上
--use_llm后,会用一个模型(Gemini、Claude、OpenAI 或本地的 Ollama 模型)来提升表格、表单和公式的准确度。 - 渲染与后处理:各区块被合并、后处理,最终输出为你选定的格式。
驱动这一切最简单的方式就是 CLI,下面就来讲。
marker architecture (source: datalab-to/marker repo, via dibi8 analysis)
安装与配置 #
如果要把 marker 当作定时运行的生产任务,你需要一台常开的机器——可以在 DigitalOcean 上开一台(新账号有免费试用额度),或者用 HTStack 提供的低延迟香港 VPS(与托管 dibi8.com 的是同一家 IDC)。
要上手 datalab-to/marker,从 PyPI 安装即可。
使用 pip #
先确认系统里装好了 Python,然后安装 marker-pdf 包:
a
s
h
pip install marker-pdf
如果需要转换非 PDF 格式(DOCX、PPTX、XLSX、EPUB、HTML、图片),请安装完整额外依赖:
a
s
h
pip install marker-pdf[full]
克隆仓库 #
或者也可以直接从 GitHub 克隆仓库做本地开发:
a
s
h
git clone https://github.com/datalab-to/marker.git
cd marker
pip install -e .
常见错误与修复 #
一个常见问题是把系统环境和虚拟环境的安装混在一起,结果导致找不到 marker_single 命令,或出现依赖冲突。安装和运行前,请确保虚拟环境已激活:
a
s
h
# Activate the virtual environment (assuming you're using venv)
source .venv/bin/activate
# Install, then run
pip install marker-pdf
marker_single /path/to/file.pdf
如果首次运行时遇到 GPU 或模型下载方面的问题,请查看仓库的 README.md 获取指引,或在 GitHub 上提 issue。
核心用法 #
装好 marker-pdf 后,你会得到两个 CLI 入口:marker_single 处理单个文件,marker 处理整个文件夹。
示例 1:转换单个文件 #
把一份文档转成 Markdown(默认输出格式):
a
s
h
marker_single /path/to/report.pdf
转换结果会写入一个输出目录;你可以用 --output_format 来控制格式。
示例 2:选择输出格式 #
Marker 支持 markdown、json、html 和 chunks(一种为 RAG 流水线设计的扁平化 JSON 布局):
a
s
h
marker_single /path/to/report.pdf --output_format json
示例 3:转换整个文件夹 #
批量转换某个文件夹里的所有文档:
a
s
h
marker /path/to/input/folder --output_format markdown
示例 4:转换指定页码,或使用 LLM #
你可以把转换限定在某个页码范围,并开启 LLM 辅助以提升准确度:
a
s
h
marker_single /path/to/report.pdf --page_range "0,5-10,20" --use_llm
--page_range 接受用逗号分隔的页码和范围,--use_llm 则会把棘手的表格、表单和行内公式交给模型(Gemini、Claude、OpenAI 或 Ollama)处理以提高准确度。对于大型多 GPU 任务,还有 marker_chunk_convert:
a
s
h
NUM_DEVICES=4 NUM_WORKERS=15 marker_chunk_convert ../pdf_in ../md_out
这些示例足够你上手了。完整的参数列表请查看 GitHub 上的官方 README。
集成 #
marker 既是命令行工具,也是一个 Python 库,所以能干净地接入脚本、notebook 和各种流水线。
使用 Python API #
只需几行代码就能转换文件,并拿到渲染后的文本和抽取出的image:
h
o
n
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = PdfConverter(artifact_dict=create_model_dict())
rendered = converter("FILEPATH")
text, _, images = text_from_rendered(rendered)
要更改输出格式或启用 LLM 服务,可通过 ConfigParser 来驱动:
h
o
n
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.config.parser import ConfigParser
config_parser = ConfigParser({"output_format": "json"})
converter = PdfConverter(
config=config_parser.generate_config_dict(),
artifact_dict=create_model_dict(),
processor_list=config_parser.get_processors(),
renderer=config_parser.get_renderer(),
llm_service=config_parser.get_llm_service(),
)
rendered = converter("FILEPATH")
Marker 还自带几个专用转换器——TableConverter 只处理表格,OCRConverter 只输出 OCR 结果,还有一个测试版(beta)的 ExtractionConverter,可以按 Pydantic JSON schema 抽取结构化数据。
接入 CI/CD 流水线 #
由于它就是个普通的 CLI,你可以把 marker 作为任意 CI/CD 任务里的一步来运行。下面是一个最小的 GitHub Actions 示例,每次 push 时都把一份 PDF 转成 Markdown:
a
m
l
name: Convert PDF to Markdown
on:
push:
branches: [ master ]
jobs:
convert-pdf:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install marker
run: pip install marker-pdf
- name: Convert PDF to Markdown
run: marker_single docs/report.pdf --output_format markdown
这样一来,无论是 notebook 还是自动化构建流水线,都能轻松集成 marker。
基准与true实使用 #
吞吐量 #
根据项目自己的 README,marker 在 H100 GPU 上批量运行时可达到约每秒 25 页。true实吞吐量很大程度上取决于你的硬件、文档复杂度,以及是否开启了 --use_llm(LLM 这一遍是用速度换准确度)。任何单一数字都只能当作上限,而非保证;请用你自己的文档来实测。
true实使用场景 #
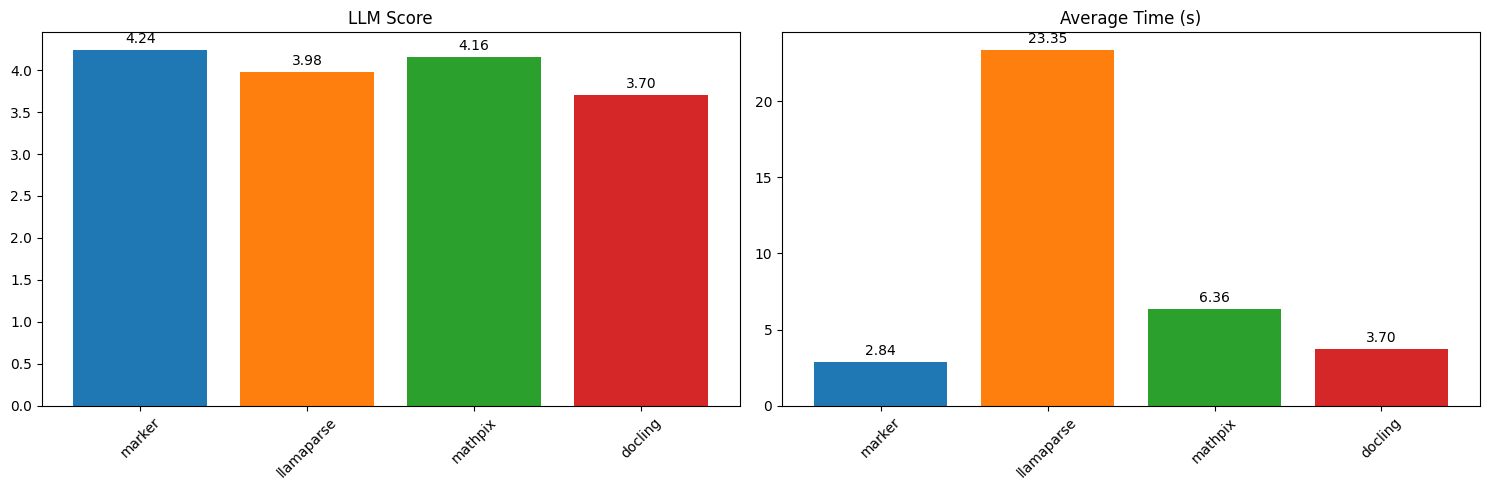
Marker 常被用于这类任务:构建文档检索与 RAG 语料、从报告中抽取表格和表单,以及把学术论文、手册和书籍转成干净的 Markdown 以便后续处理。其中 chunks 输出格式专门面向检索增强生成(RAG)流水线——每个区块都以自包含的 HTML 形式给出。

marker benchmark results (source: datalab-to/marker repo, via dibi8 analysis)
与同类工具对比 #
也可以看看我们对相关Open Source工具的整理。
挑选 PDF 转 Markdown 的工具时,要权衡准确度、格式覆盖面、速度和许可。下面是 marker 与两个常见Open Source替代品的概览对比:pdfplumber(文本/表格抽取)和 pymupdf4llm(基于 PyMuPDF 的 Markdown 导出器)。
| 特性 | datalab-to/marker | pdfplumber | pymupdf4llm | |——————
|——————————————-
|—————————-
|—————————-
|
| 语言 | Python | Python | Python |
| 思路 | 深度学习版面 + OCR + 可选 LLM | 基于规则的文本抽取 | 基于 PyMuPDF 的抽取 |
| 输入格式 | PDF、图片、PPTX、DOCX、XLSX、HTML、EPUB | 仅 PDF | PDF 及少数几种 |
| 输出格式 | Markdown、JSON、HTML、chunks | 文本、表格(dict) | Markdown |
| OCR / 扫描件 | 内置 OCR | 无原生 OCR | 有限 |
| LLM 模式 | 可选(--use_llm) | 无 | 无 |
| 最适合 | 复杂版面、表格、RAG、扫描件 | 精确的表格/坐标处理 | 快速、简单的 Markdown 导出 |
当文档很复杂时——多栏版面、公式、扫描页或表格——marker 的优势最明显,因为它的版面模型加上可选的 LLM 这一遍,能处理规则型工具搞不定的结构。而 pdfplumber、pymupdf4llm 这类更轻量的工具速度更快、依赖更少,当你的 PDF 本就简单、是原生数字版且纯文本时,它们更合适。根据你true实文档的"脏乱程度"来选就对了。
局限与客观评估 #
虽然 marker 在复杂文档上很强,但有一些实实在在的取舍值得事先了解:
- 依赖更重、对硬件要求更高:marker 依赖深度学习模型,所以有没有 GPU 差别很大。纯 CPU 机器上能跑,但慢得多,而且安装体积比规则型库更大。
- 复杂表格并不完美:跨页的表格,或含有深度嵌套/合并单元格的表格,仍可能出现错位,需要人工清理。
- LLM 模式带来成本和延迟:
--use_llm能提升准确度,但会引入一次外部模型调用(以及 API 费用,除非你跑本地 Ollama 模型),因此更慢、也不免费。 - 速度差异很大:头条里的吞吐数字默认是高端 GPU 加批量处理;在一般硬件上、或开了 LLM 模式时,实际会慢很多。
- 许可上的细节:代码是 GPL-3.0,但模型权重采用的是经过修改的 AI Pubs Open Rail-M 许可——对研究、个人使用以及规模较小的公司免费,较大的机构则需要商业许可。大规模部署前请先核对条款。
在判断 marker 是否适合你的具体场景时,这些取舍很重要。
结语 #
凭借超过 35,694 个 star,以及一条专为应付true实世界中"脏乱"文档而设计的流水线,当你需要从 PDF、Office 文件和 EPUB 中得到准确的 Markdown、JSON、HTML 或分块输出时——尤其是文档里有表格、公式或扫描页时——marker 是个有力的选择。下一步就是装上它,拿你自己的一份文档跑一跑:
a
s
h
pip install marker-pdf
marker_single /path/to/your/file.pdf
- 加入 dibi8 英文 Telegram 群,获取Open Source AI 工具速递。
- 继续阅读:dibi8 上的相关指南。
来源与延伸阅读:
- GitHub 仓库:https://github.com/datalab-to/marker
- 官方文档 / README:https://github.com/datalab-to/marker#readme
以上部分链接为推广链接。如果你通过它们注册,dibi8.com 可能会获得一笔佣金,而你不会因此多付任何费用。这有助于维持网站运营,让内容保持免费。
💬 留言讨论