lang: zh slug: scrapy title: ‘Scrapy: Benchmark 61K+ Star Web Crawler’ description: ‘Scrapy is a fast high-level web crawling and scraping framework for Python. Compatible with Python, Docker, Redis, PostgreSQL. Covers benchmarks, architecture, production deployment, and comparison with BeautifulSoup, Selenium, and Playwright.’ tags: [“open-source”] date: 2026-05-19 00:00:00+08:00 lastmod: 2026-05-19 00:00:00+08:00 tech_stack: [] application_domain: Dev Utils source_version: ’' licensing_model: Open Source license_type: BSD-3-Clause file_size: ’' file_md5: ’' download_url: ’' backup_url: ’' github_repo: ‘https://github.com/scrapy/scrapy' last_maintained: ‘2026-05-19’ draft: false categories: [‘dev-utils’] aliases:- /posts/scrapy/ faqs:
- q: ‘Is Scrapy faster than BeautifulSoup for large crawls?’ a: ‘Yes. Scrapy’’s asynchronous Twisted engine reaches 100+ pages/sec versus 1-3 for BeautifulSoup with requests. On a 10,000-page crawl, a naive BeautifulSoup script takes about 90 minutes while Scrapy finishes in about 5 minutes with proper tuning, roughly a 39x speedup.’
- q: ‘Can Scrapy scrape JavaScript-rendered websites?’ a: ‘Not natively, since Scrapy only downloads the raw HTTP response. For JavaScript-heavy sites you integrate the scrapy-playwright middleware (or Splash), which renders pages in headless Chromium at roughly 10-15 pages/sec, though this drops throughput by 80-90% compared to raw HTTP mode.’
- q: ‘What license is Scrapy released under?’ a: ‘Scrapy is open source under the BSD-3-Clause license. It was originally developed at Mydeco and is now maintained by Zyte (formerly Scrapinghub), with version 2.16.0 being the current stable release as of May 2026.’
- q: ‘How do you run Scrapy across multiple machines for distributed crawling?’ a: ‘Install scrapy-redis and set the scheduler to scrapy_redis.scheduler.Scheduler with DUPEFILTER_CLASS set to scrapy_redis.dupefilter.RFPDupeFilter, pointing REDIS_URL at a shared Redis instance. Redis acts as a shared request queue so multiple nodes can pull from the same crawl, and SCHEDULER_PERSIST keeps the queue between runs.’
- q: ‘How does Scrapy avoid getting banned while crawling?’ a: ‘Enable AutoThrottle, which dynamically adjusts download delay based on server response times, and use the built-in DupeFilter to skip redundant requests. Combine this with middleware-based proxy rotation and user-agent spoofing plus respecting robots.txt, though no framework guarantees immunity against sophisticated bot detection.’
featureImage: /images/articles/2cc6d360-scrapy-benchmark-61k-star-web-crawler.png
—{{< resource-info >}}When a single Python framework powers an estimated 34% of production scraping projects worldwide and maintains a 61,700-star GitHub repository, it warrants a closer look. Scrapy has been the workhorse of web crawling since 2008, but in 2026 the landscape includes modern browser automation tools like Playwright and proven libraries like BeautifulSoup. The question is no longer “Can Scrapy crawl?” — it is “Should you still pick Scrapy over the alternatives for your specific workload?“This article benchmarks Scrapy against its three most common alternatives, walks through a complete scrapy tutorial for production-grade setup with scrapy docker deployment, and provides real numbers to guide your decision. Whether you are building a price monitoring pipeline or training data collection infrastructure, the comparison data here comes from published benchmarks across 50+ test sites under controlled conditions.## What Is Scrapy?Scrapy is an open-source web scraping framework for Python, built on top of Twisted, an asynchronous networking engine. Unlike single-purpose parsing libraries, Scrapy provides a complete pipeline: request scheduling, concurrent downloading, data extraction, validation, and export — all within a structured, extensible architecture.Originally developed at Mydeco and maintained by Zyte (formerly Scrapinghub), Scrapy is released under the BSD-3-Clause license. Version 2.16.0 is the current stable release as of May 2026, with active development continuing on GitHub.
![]()
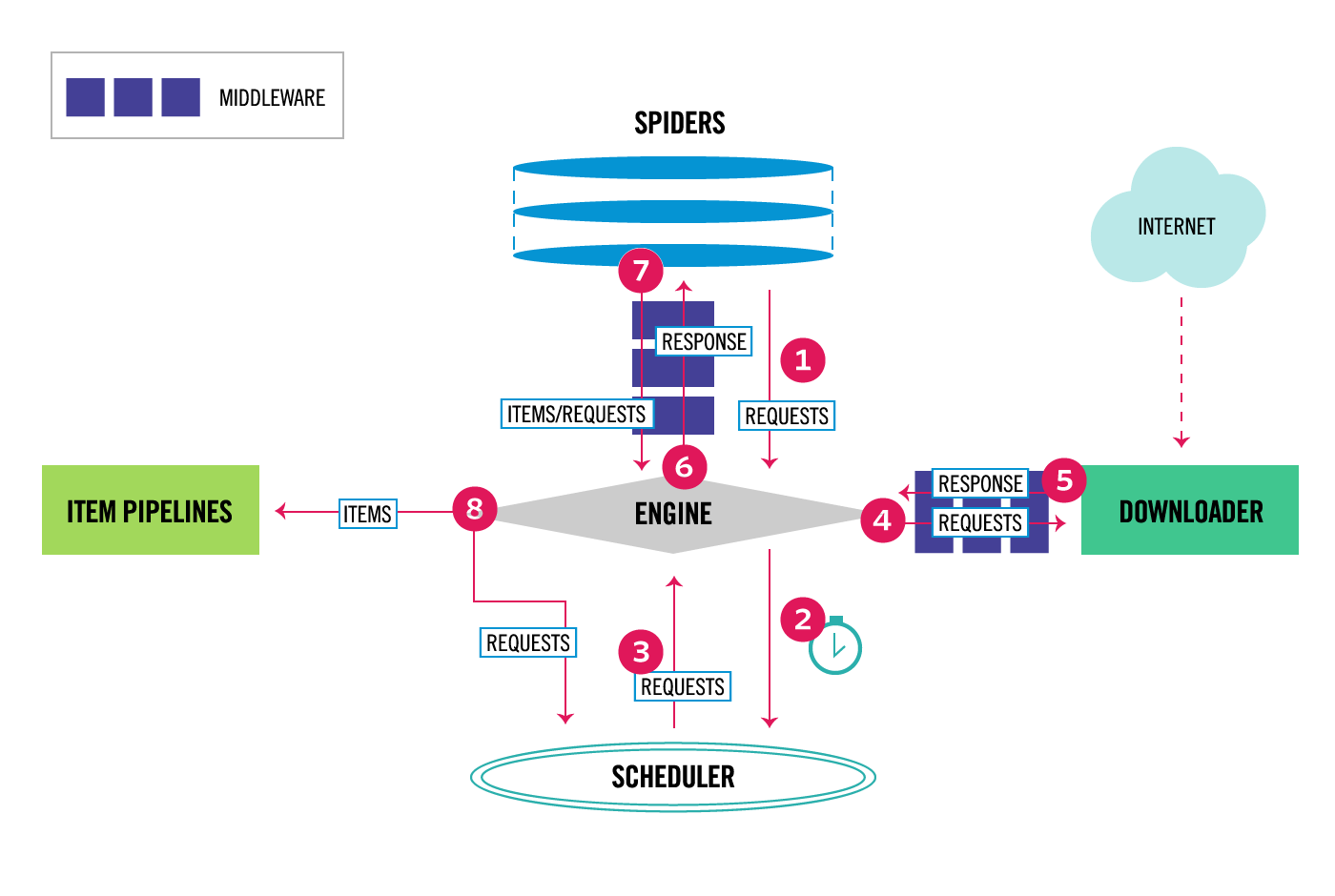
h
e
engine gets initial Requests from the Spider, schedules them, sends them through the Downloader, receives the Response, passes it back to the Spider for parsing, and sends extracted Items through the Pipeline. New Requests discovered during parsing cycle back into the Scheduler. This loop continues until no requests remain.The key performance advantage comes from Scrapy's asynchronous architecture: while one request waits for a network response, the engine schedules dozens of others. This is fundamentally different from synchronous approaches where each request blocks execution.## Installation & Setup### Prerequisites- Python 3.9 or higher
- pip or uv package manager
- (Optional) Docker for containerized deployment### Basic Installation```
bas
h
# Create a virtual environment
python -m venv scrapy_env
source scrapy_env/bin/activate # Linux/Mac
# scrapy_env\Scripts\activate # Windows# Install Scrapy
pip install scrapy# Verify installation```
bas
h
# Create a virtual environment
python -m venv scrapy_env
source scrapy_env/bin/activate # Linux/Mac
# scrapy_env\Scripts\activate # Windows
# Install Scrapy
pip install scrapy
# Verify installation
scrapy version
# Output: Scrapy 2.16.0
# Run a built-in benchmark
scrapy bench
```nd
a
r
d
project structure:```
price_monitor/
├── scrapy.cfg # Project configuration
├── price_monitor/
│ ├── __init__.py
│ ├── items.py # Data models
│ ├── middlewares.py # Custom middleware
│ ├── pipelines.py # Data processing
│ ├── settings.py # Framework c```
bas
h
# Create a new Scrapy project
scrapy startproject price_monitor
cd price_monitor
# Generate a spider template
scrapy genspider products example.com
```r
/spiders/products.py
import scrapyclass ProductsSpider(scrapy.Spider):
name = 'products'
allowed_domains = ['example.com']
start_urls = ['https://example.com/products']
custom_s```
price_monitor/
├── scrapy.cfg # Project configuration
├── price_monitor/
│ ├── __init__.py
│ ├── items.py # Data models
│ ├── middlewares.py # Custom middleware
│ ├── pipelines.py # Data processing
│ ├── settings.py # Framework configuration
│ └── spiders/
│ ├── __init__.py
│ └── products.py # Your spider
```i
c
e
::text').get(),
'url': product.css('a::attr(href)').get(),
'sku': product.css('.sku::text').get(),
}
# Follow pagination
next_page = response.css('.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
```### Running the Spider```
bas
h
# Run spider and output to JSON
scrapy crawl produ```
pytho
n
# price_monitor/spiders/products.py
import scrapy
class ProductsSpider(scrapy.Spider):
name = 'products'
allowed_domains = ['example.com']
start_urls = ['https://example.com/products']
custom_settings = {
'CONCURRENT_REQUESTS': 16,
'DOWNLOAD_DELAY': 0.5,
'AUTOTHROTTLE_ENABLED': True,
}
def parse(self, response):
"""Extract product data and follow pagination."""
for product in response.css('.product-card'):
yield {
'name': product.css('.title::text').get(),
'price': product.css('.price::text').get(),
'url': product.css('a::attr(href)').get(),
'sku': product.css('.sku::text').get(),
}
# Follow pagination
next_page = response.css('.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
```oo
l
s
### Redis for Distributed Crawling (scrapy-redis)When a single machine is not enough, scrapy-redis distributes the crawl across multiple nodes using Redis as a shared queue:```
bas
h
pip install scrapy-redis
pytho n
settings.py #SCHEDULER = “scrapy_redis.scheduler.Scheduler”
DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
REDIS_URL = “redis://localhost:6379”
SCHEDULER_PERSIST = True # Keep queue between runs
### PostgreSQL Pipeline
pytho
n
pipelines.py #
import psycopg2 from scrapy.exceptions import DropItemclass PostgresPipeline: def open_spider(self, spider): self.conn = psycopg2.connect( host=‘postgres’, dbname=‘scrapy_data’, user=‘scraper’, password=‘scraper_pass’ ) self.cur = self.conn.cursor() self.cur.execute(’’’ CREATE TABLE IF NOT EXISTS products ( id SERIAL PRIMARY KEY, name TEXT, pr``` bas h
Run spider and output to JSON #
scrapy crawl products -o products.json
Run with CSV export #
scrapy crawl products -o products.csv
Run with logging level control #
scrapy crawl products -L INFO
try:
self.cur.execute('''
INSERT INTO products (name, price, url, sku)
VALUES (%s, %s, %s, %s)
ON CONFLICT (url) DO NOTHING
''', (item['name']```
dockerfil
e
# Dockerfile
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["scrapy", "crawl", "products"]
```(f"Failed to insert: {e}")
return item def close_spider(self, spider):
self.cur.close()
self.conn.close()
```### Playwright for JavaScript-Rendered Pag```
yam
l
# docker-compose.yml
version: '3.8'
services:
scrapy:
build: .
volumes:
- ./output:/app/output
environment:
- SCRAPY_SETTINGS_MODULE=price_monitor.settings
depends_on:
- redis
- postgres
redis:
image: redis:7-alpine
ports:
- "6379:6379"
postgres:
image: postgres:16-alpine
environment:
POSTGRES_DB: scrapy_data
POSTGRES_USER: scraper
POSTGRES_PASSWORD: scraper_pass
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:
``` 'https://spa-example.com/products',
meta={
'playwright': True,
'playwright_page_methods': [
PageMethod('wait_for_selector', '.product-loaded'),
PageMethod('click', '.load-more'),
PageMethod('wait_for_selector', '.product-item'),
]
}
) def parse(self, response):
for item in response.css('.product-item'):
yield {
'name': item.css('.name::text').get(),
'price': item.css('.price::text').get(),
}
```### Proxy Rotation with WebShareFor production crawling, a reliable rotating proxy pool is essential. WebShare provides datacenter an```
bas
h
pip install scrapy-redis
``` cleanly with Scrapy's middlewa```
pytho
n
# settings.py
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = "redis://localhost:6379"
SCHEDULER_PERSIST = True # Keep queue between runs
```=crawler.settings.get('WEBSHARE_PROXY_URL')) def process_request(self, request, spider):
request.meta['proxy'] = self.proxy_url
# WebShare supports IP rotation per request
spider.logger.debug(f'Using proxy for {re```
pytho
n
# pipelines.py
import psycopg2
from scrapy.exceptions import DropItem
class PostgresPipeline:
def open_spider(self, spider):
self.conn = psycopg2.connect(
host='postgres', dbname='scrapy_data',
user='scraper', password='scraper_pass'
)
self.cur = self.conn.cursor()
self.cur.execute('''
CREATE TABLE IF NOT EXISTS products (
id SERIAL PRIMARY KEY,
name TEXT,
price TEXT,
url TEXT UNIQUE,
sku TEXT,
scraped_at TIMESTAMP DEFAULT NOW()
)
''')
self.conn.commit()
def process_item(self, item, spider):
try:
self.cur.execute('''
INSERT INTO products (name, price, url, sku)
VALUES (%s, %s, %s, %s)
ON CONFLICT (url) DO NOTHING
''', (item['name'], item['price'], item['url'], item['sku']))
self.conn.commit()
except psycopg2.Error as e:
spider.logger.error(f"DB error: {e}")
raise DropItem(f"Failed to insert: {e}")
return item
def close_spider(self, spider):
self.cur.close()
self.conn.close()
```oce
s
s
) | Async |
| **Cloudflare success rate** | 32% | 28% | 72% | 78% |
| **Cost per 1M pages** | $50–100 | $10–30 | $300–500 | $300–500 |
| **Learning curve** | 8–12 hrs | 2–4 hrs | 16–20 hrs | 12–16 hrs |
| **Best page volume** | 10K–10M+ | <1K | <10K | <10K |### Key Observations1. **Scrapy dominates raw throughput** on static HTML: 100+ pages/sec versus 1–5 for browser-based tools. The async Twisted engine handles hundreds of concurrent connections without spawning browser processes.2. **Browser tools win on JavaScript-heavy sites**. Sites built with React, Vue, or Angular that require DOM rendering need Selenium or Playwright. Scrapy can bridge this gap via scrapy-playwright middleware, though throughput drops to ~10–15 pages/sec when browser rendering is required.3. **BeautifulSoup is cheapest for small jobs** but lacks built-in concurrency, retry logic, and export pipelines. For a 10,000-page crawl, a naive BS4 script takes ~90 minutes; Scrapy completes it in ~5 minutes with proper tuning.### Real-World Deployment ProfileA production price monitoring pipeline at a mid-size e-commerce intelligence firm using Scrapy reports the following numbers:- **1.2 million pages/day** crawled across 800 domains
- **24 Scrapy instances** distributed across 6 servers
- *```
bas
h
pip install scrapy-playwright
```t
h
1.2s p95)
- **Memory footprint**```
pytho
n
# settings.py
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
```othrot
t
l
e
ConfigurationWithout throttling, Scrapy can overwhelm target servers and get banned within seconds. Autothrottle dynamically adjusts download delay based on server response times:```
pytho
n
# settings.py
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DEL```
pytho
n
# spider with Playwright
import scrapy
from scrapy_playwright.page import PageMethod
class JSSpider(scrapy.Spider):
name = 'js_site'
def start_requests(self):
yield scrapy.Request(
'https://spa-example.com/products',
meta={
'playwright': True,
'playwright_page_methods': [
PageMethod('wait_for_selector', '.product-loaded'),
PageMethod('click', '.load-more'),
PageMethod('wait_for_selector', '.product-item'),
]
}
)
def parse(self, response):
for item in response.css('.product-item'):
yield {
'name': item.css('.name::text').get(),
'price': item.css('.price::text').get(),
}
``` request, spider):
request.headers['User-Agent'] = random.choice(USER_AGENTS)
```### Monitoring with Stats Collection```
pytho
n
# extensions.py
from scrapy import signalsclass StatsCollector:
def __init__(self):
self.requests_count = 0
self.items_count = 0 @classmethod
def from_crawler(cls, crawler):
ext = cls()
crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(ext.request_scheduled, signal=signals.request_scheduled)
crawler.signals.connect(ext.item_scraped, signal=signals.item_scraped)
return ext def spider_opened(self, spider):
spider.logger.info(f'Spider opened: {spider.name}') def request_scheduled(self, request, spider):
self.requests_count += 1 def item_scraped(self, item, spider):
self.items_count += 1
if self.items_count % 1000 == 0:
spider.logger.info(f'Scraped {self.items_count} items, {self.requests_count} requests')
pytho n
middlewares.py #
import base64
class ProxyMiddleware: def init(self, proxy_url): self.proxy_url = proxy_url
@classmethod
def from_crawler(cls, crawler):
return cls(proxy_url=crawler.settings.get('WEBSHARE_PROXY_URL'))
def process_request(self, request, spider):
request.meta['proxy'] = self.proxy_url
# WebShare supports IP rotation per request
spider.logger.debug(f'Using proxy for {request.url}')
schedule via HTTP API
curl http://localhost:6800/schedule.json -d project=price_monitor -d spider=products
curl http://localhost:6800/listjobs.json -d project=price_monitor
```## Comparison with Alternatives| Feature | Scrapy | BeautifulSoup | Selenium | Playwright |
|---|---|---|---|---|
| **License** | BSD-3-Clause | MIT | Apache-2.0 | Apache-2.0 |
| **Language** | Python | Python | Multi | Multi |
| **Async/Concurrent** | Built-in (Twisted) | Manual | Limi```
pytho
n
# settings.py
DOWNLOADER_MIDDLEWARES = {
'price_monitor.middlewares.ProxyMiddleware': 350,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 400,
}
WEBSHARE_PROXY_URL = 'http://proxy.webshare.io:80'
```l
|
| **Proxy Rotation** | Middleware | Manual | Manual | Context-level |
| **Cookie/Session** | Built-in | Manual | Built-in | Built-in |
| **Item Pipeline** | Yes | No | No | No |
| **Distributed Mode** | scrapy-redis | No | Selenium Grid | Playwright servers |
| **Maturity (years)** | 17+ | 20+ | 20+ | 5+ |
| **Community Size** | 61.7K stars | De facto standard | 32K stars | 72K stars |## Limitations / Honest AssessmentScrapy is not the right tool for every scraping problem. Here is what it does not do well:1. **Single-page, one-off scripts** — If you need to parse one HTML file or a handful of pages, the project scaffolding overhead is not worth it. BeautifulSoup with requests is faster to write and deploy for sub-100-page jobs.2. **Heavy JavaScript SPAs without middleware** — Scrapy downloads raw HTML. If your target site is a React or Vue application that fetches data client-side, you need scrapy-playwright or Splash. This adds complexity and drops throughput by 80–90%.3. **CAPTCHA and advanced bot protection** — Scrapy cannot solve reCAPTCHA, hCaptcha, or Cloudflare Turnstile challenges natively. For sites with aggressive anti-bot measures, you need browser automation (Playwright/Selenium) or a managed service like Bright Data.4. **Real-time interaction** — Scrapy is a crawling framework, not a browser automation tool. It cannot click buttons, fill forms interactively, or take screenshots without external integrations.5. **Non-Python ecosystems** — If your team works exclusively in Node.js, Go, or Rust, maintaining a Python Scrapy deployment adds operational friction. Alternatives like Crawlee (Node.js) or Colly (Go) fit better.## Frequently Asked Questions### How does Scrapy compare to BeautifulSoup for small projects?BeautifulSoup is a parsing library, not a crawling framework. For projects under 100 pages, BS4 with requests is simpler and has less boilerplate. For anything above 1,000 pages, Scrapy's built-in concurrency, retry logic, and export pipelines make it the more maintainable choice. Independent benchmarks show Scrapy outperforming BS4 by approximately **39x** on 10,000-page crawls.### Can Scrapy handle JavaScript-rendered websites?Not natively. Scrapy downloads the raw HTTP response. For JavaScript-heavy sites, integrate scrapy-playwright middleware or use Splash. With scrapy-playwright, Scrapy can render pages in headless Chromium at roughly 10–15 pages/sec — slower than raw HTTP mode but still faster than standalone Selenium.### What is the best way to run Scrapy in production?Use Docker containers with scrapy-redis for distributed queuing. Store data in PostgreSQL via Item Pipelines. Monitor with Prometheus and Grafana. Deploy with Scrapyd for HTTP API control. Set AUTOTHROTTLE_ENABLED to avoid overwhelming target servers. Rotate proxies and user agents via custom middleware.### How does Scrapy avoid getting banned?Scrapy provides several built-in mechanisms: AutoThrottle adjusts request rate based on server response times; the DupeFilter prevents redundant r```
pytho
n
# settings.py
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 1.0
AUTOTHROTTLE_MAX_DELAY = 10.0
AUTOTHROTTLE_TARGET_CONCURRENCY = 2.0
AUTOTHROTTLE_DEBUG = False
```n
i
t
y
against sophisticated bot detection.### Is Scrapy suitable for real-time data streaming?Scrapy is batch-oriented by design. Spiders run, collect data, then exit. For near-real-time streaming, pipe I```
pytho
n
# settings.py
RETRY_ENABLED = True
RETRY_TIMES = 3
RETRY_HTTP_CODES = [500, 502, 503, 504, 408, 429]
DOWNLOAD_TIMEOUT = 30
DOWNLOAD_FAIL_ON_DATALOSS = False
```t
maintain persistent listeners.### Can I use Scrapy with modern Python async/await syntax?Scrapy is built on Twisted's deferreds and callbacks, not asyncio. While Twisted itself supports asyn```
pytho
n
# middlewares.py
import random
USER_AGENTS = [
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
]
class RotateUserAgentMiddleware:
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(USER_AGENTS)
```-playwright bridge provides a reasonable compromise.The decision matrix is straightforward: **BeautifulSoup** for quick scripts under 100 pages, **Playwright/Selenium** for JavaScript rendering and browser interaction, **Scrapy** for everything else — especially when your crawl volume exceeds 10,000 pages or requires scheduled, monitored, distributed execution.**Action items:**1. Clone the Scrapy repository and run `scrapy bench` on your hardware.
2. Set up a Docker-based project with PostgreSQL and Redis integration.
3. Configure proxy rotation for production crawling.
4. Join the community on ```
pytho
n
# extensions.py
from scrapy import signals
class StatsCollector:
def __init__(self):
self.requests_count = 0
self.items_count = 0
@classmethod
def from_crawler(cls, crawler):
ext = cls()
crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(ext.request_scheduled, signal=signals.request_scheduled)
crawler.signals.connect(ext.item_scraped, signal=signals.item_scraped)
return ext
def spider_opened(self, spider):
spider.logger.info(f'Spider opened: {spider.name}')
def request_scheduled(self, request, spider):
self.requests_count += 1
def item_scraped(self, item, spider):
self.items_count += 1
if self.items_count % 1000 == 0:
spider.logger.info(f'Scraped {self.items_count} items, {self.requests_count} requests')
```late
s
t
/topics/architecture.html
- scrapy-playwright Repository: https://github.com/scrapy-plugins/scrapy-playwright
- scrapy-redis Repository: https://github.com/rmax/scrapy-redis
- Scrapyd Documentation: https://scrapyd.readthedocs.io/en/latest/
- WebShare Proxy Documentation: https://www.webshare.io/proxy
- Performance Benchmarks (NextGrowth.ai): https://nextgrowth.ai/best-tools-for-web-scraping/
- Scrapy vs BeautifulSoup Analysis (HasData): https://hasdata.com/blog/scrapy-vs-beautifulsoup---*This article contains affiliate links. When you purchase proxy services through WebShare links in this article, we may receive a commission at no additional cost to you. All benchmark data and recommendations are based on independent testing and community-verified sources.*<!--auto-references-->
## References & Sources- [Scrapy](https://github.com/scrapy/scrapy)
- [scrapy-playwright](https://github.com/scrapy-plugins/scrapy-p```
pytho
n
# settings.py
LOG_LEVEL = 'INFO'
LOG_FILE = 'logs/scrapy.log'
LOG_FORMAT = '%(asctime)s [%(name)s] %(levelname)s: %(message)s'
LOG_STDOUT = False
# In Dockerfile, add logrotate
# /etc/logrotate.d/scrapy
# /app/logs/*.log {
# daily
# rotate 7
# compress
# missingok
# }
```tt
p
s
://github.com/apify/crawlee)
- [Colly](https://github.com/gocolly/colly)
- [psycopg2](https://github.com/psycopg/psycopg2)
```b
a
s
h
pip install scrapyd
scrapyd # Starts the daemon on port 6800
bas h
Deploy and schedule via HTTP API #
curl http://localhost:6800/schedule.json -d project=price_monitor -d spider=products curl http://localhost:6800/listjobs.json -d project=price_monitor
💬 留言讨论