Skyvern:使用 AI 代理自动化浏览器工作流程(21K 星)
Skyvern 用大语言模型和计算机视觉自动化浏览器工作流(21,803 GitHub 星,AGPL-3.0)。涵盖安装、true实的 Python API、可运行的代码示例,以及与 Selenium、Playwright 的诚实对比。
- AGPL-3.0
- 更新于 2026-06-02
引言 #
你有没有用 Selenium 或 Playwright 写过浏览器脚本,结果网站一改 CSS 类名、一挪按钮,脚本立刻就崩了?在 GitHub 上拥有超过 21,803 颗星的 Skyvern-AI/skyvern 走的是另一条路:它不为每个网站硬编码选择器,而是用大语言模型加计算机视觉像人一样去理解页面,然后完成你用自然语言描述的任务。本指南将带你搭建 Skyvern 并使用它true实的 API。
![]()
skyvern 概览(来源:Skyvern-AI/skyvern 仓库,经 dibi8 分析)
什么是 Skyvern? #
Skyvern 是一款Open Source工具,用 AI 智能体自动化基于浏览器的工作流。它由 Skyvern-AI 开发,让你用自然语言描述目标——“登录并下载上个月的发票”、“填好这份申请表”、“提取每个商品的名称和价格”——智能体便会想办法在true实浏览器里把它完成。
其核心思路是:Skyvern 以视觉方式推理每个页面,而不依赖脆弱的 XPath 或 CSS 选择器。由于它用具备视觉能力的大语言模型来解析实时 DOM 加上渲染后的截图,同一套工作流可以在成千上万个不同网站上持续生效,并且往往能挺过那些会让传统脚本崩溃的布局改动。
凭借强大的社区支持——GitHub 上超过 21,803 颗星——Skyvern 在寻求高韧性自动化的开发者中赢得了true正的关注。
Skyvern 的工作原理 #
Skyvern 把几个部件组合起来,将一条自然语言指令转化为可靠的浏览器操作:
- LLM 驱动的规划:你给出描述目标的提示词,大语言模型把它拆解为达成目标所需的具体步骤。Skyvern 与模型无关,支持 OpenAI、Anthropic Claude、Google Gemini、AWS Bedrock,以及通过 Ollama 接入的本地模型等。
- 计算机视觉识别元素:Skyvern 不依赖固定选择器,而是把渲染后的页面(DOM 加截图)交给具备视觉能力的大语言模型,识别出该点击、输入或读取哪些元素。这正是它能抗住布局变化的原因。
- Playwright 控制浏览器:true正的点击、输入和导航由成熟的浏览器自动化框架 Playwright 执行,因此 Skyvern 天然继承了对现代 Web 应用的良好支持。
在底层,每个任务都存入本地数据库(默认 SQLite,也可用 Postgres),这让运行可复现,也便于你一步步查看智能体做了什么。
skyvern 运行实况(来源:Skyvern-AI/skyvern 仓库,经 dibi8 分析)
安装与配置 #
要把 Skyvern 作为定时生产任务运行,你需要一台常开的机器——可以在 DigitalOcean 上开一台(新账户有免费试用额度),或选 HTStack 的低延迟香港 VPS(与托管 dibi8.com 的是同一家 IDC)。
如果你熟悉 Python,安装 Skyvern 很简单。你需要 Python 3.11+ 以及至少一个 LLM API key。
使用 pip #
安装完整版本,其中包含本地 UI 和服务器:
a
s
h
pip install "skyvern[all]"
如果你只需要从自己的代码里调用 Skyvern 的 SDK,更轻量的安装就够了:
a
s
h
pip install skyvern
快速开始 #
安装完成后,搭好可用环境最快的方式是内置的 quickstart 命令。它会引导你配置 LLM 提供方,然后启动以 SQLite 为后端的本地服务器和 Web UI:
a
s
h
skyvern quickstart
如果你更倾向于用 Postgres 作后端,加上对应参数即可:
a
s
h
skyvern quickstart --postgres
你也可以分别单独启动各个部件:
a
s
h
skyvern run server # 仅 API 服务器
skyvern run ui # 仅 Web UI
配置 #
Skyvern 至少需要一个 LLM API key,它会从项目里的 .env 文件读取。以 OpenAI 为例,最简配置如下:
a
s
h
# .env
ENABLE_OPENAI=true
OPENAI_API_KEY=sk-your-key-here
quickstart 命令可以交互式地帮你生成这个文件。Skyvern 默认把数据存放在本地 SQLite 数据库 ~/.skyvern/ 中。
常见错误与解决 #
首次运行常见的一个问题是:服务器起来了,但每个任务都失败,因为没有启用任何 LLM 提供方。如果你看到关于模型缺失或被禁用的报错,请确认对应的 ENABLE_* 开关和 API key 在 .env 里都已存在,例如:
a
s
h
ENABLE_ANTHROPIC=true
ANTHROPIC_API_KEY=sk-ant-your-key-here
编辑 .env 后请重启服务器,让新的值生效。
核心用法 #
Skyvern 以「从自然语言提示词运行智能体任务」为核心。下面来看true实的 API。
示例 1:运行一个任务 #
最简单的流程是初始化一个本地 Skyvern 客户端,再用提示词调用 run_task。智能体会打开浏览器、完成目标并返回结果:
h
o
n
import asyncio
from skyvern import Skyvern
async def main():
skyvern = Skyvern.local()
task = await skyvern.run_task(
prompt="Go to news.ycombinator.com and find the title of the top post today",
)
print(task)
asyncio.run(main())
示例 2:结构化数据提取 #
如果你想要干净的结构化输出而非自由文本,可以传入 data_extraction_schema。Skyvern 会返回符合你 schema 的提取字段:
h
o
n
import asyncio
from skyvern import Skyvern
async def main():
skyvern = Skyvern.local()
task = await skyvern.run_task(
prompt="Extract the top 3 posts on Hacker News",
data_extraction_schema={
"type": "object",
"properties": {
"posts": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"points": {"type": "integer"},
},
},
}
},
},
)
print(task)
asyncio.run(main())
示例 3:页面级命令 #
如果需要更精细的控制,你可以直接驱动浏览器,逐条下达 AI 命令——act 用于执行动作,extract 用于读取数据,validate 用于检查条件:
h
o
n
import asyncio
from skyvern import Skyvern
async def main():
skyvern = Skyvern.local()
browser = await skyvern.launch_cloud_browser()
page = await browser.get_working_page()
await page.act("Click the login button")
data = await page.extract("Get the product name and price")
await page.validate("Confirm the user is logged in")
print(data)
asyncio.run(main())
这些示例覆盖了主要入口:用高层的 run_task 完成端到端目标、用基于 schema 的提取拿到干净数据,以及在需要逐步操控时使用页面级命令。
- Image:
- Stars: 21,803
- License: AGPL-3.0
- Maintainer: Skyvern-AI
- Homepage: https://www.skyvern.com
- Language: Python
集成 #
Skyvern 能不费多少周折地融入现有的 Python 代码库,因为它的 SDK 就是一个你可以在任何地方调用的异步客户端。
从 Web 服务调用 Skyvern #
由于 run_task 是异步的,它能很自然地嵌入异步 Web 框架。下面把它接进一个 FastAPI 端点,按需触发任务:
h
o
n
from fastapi import FastAPI
from skyvern import Skyvern
app = FastAPI()
skyvern = Skyvern.local()
@app.get("/automate")
async def automate():
task = await skyvern.run_task(
prompt="Go to example.com and click the Submit button",
)
return {"result": task}
通过环境变量配置 #
在生产环境里,把凭证和提供方选择放进环境变量、而不是写死在代码里更为清爽。Skyvern 会在启动时读取它们,所以 .env 文件是管理这些配置的天然之地:
a
s
h
# .env
ENABLE_OPENAI=true
OPENAI_API_KEY=your_api_key_here
h
o
n
from dotenv import load_dotenv
from skyvern import Skyvern
load_dotenv()
# Skyvern picks up the LLM provider settings from the environment
skyvern = Skyvern.local()
把配置放在环境里,你就能在本地、预发和生产之间迁移同一份代码而无需改动一行。
基准与实战应用 #
Skyvern 面向的是那些「跨众多不同网站的可靠性比纯速度更重要」的任务。以下是它已被证明有用的几个方向:
实战用例 #
- 大规模表单填写:在布局各不相同的网站上完成申请、入驻流程和数据录入表单——视觉化的方式意味着一条提示词就能应对许多变体。
- 抓取动态内容:从重度依赖 JavaScript 的页面提取结构化数据,而选择器在这类页面上往往很脆弱。
- 工作流自动化:把登录、导航、下载文档等多步任务串起来,Skyvern 可以将其链接成流程并按计划重复运行。
由于 Skyvern 在运行时对每个页面进行推理,它用一定的延迟和 LLM 成本换取了韧性:单步操作通常比手工调优的 Selenium 脚本更慢、更贵,但在网站发生变化时却远不容易崩。
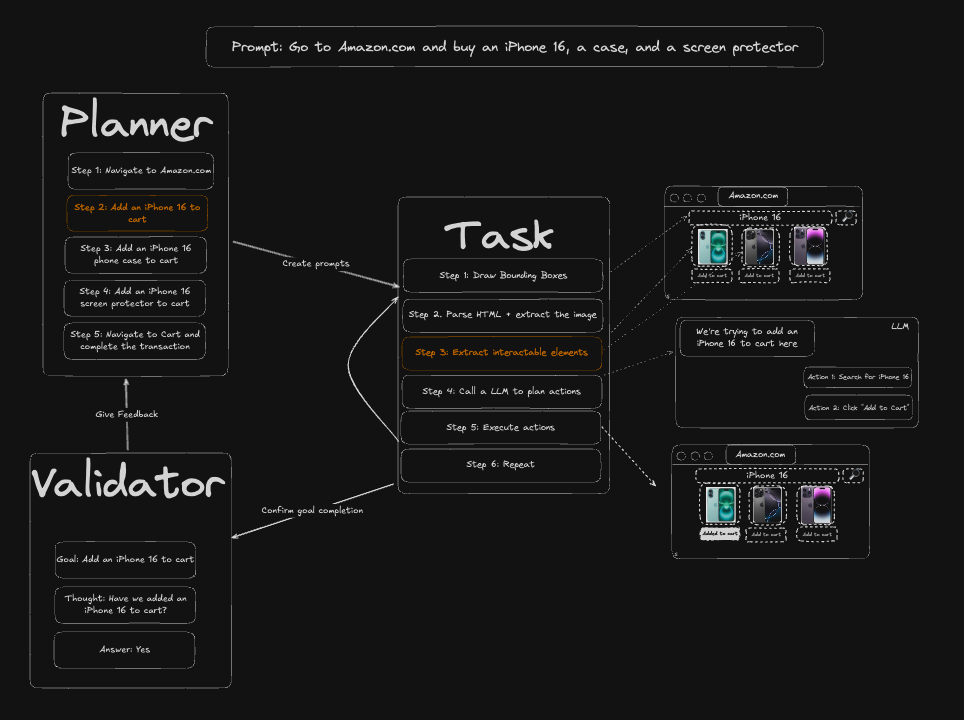
系统架构图 #
项目的系统架构图展示了一条提示词如何流经 LLM 规划与基于视觉的元素识别,最终化为 Playwright 的浏览器操作:
小结 #
对于看重韧性甚于极致速度的团队,Skyvern 为自动化浏览器工作流提供了一套能干的方案。它的自然语言接口和基于视觉的元素处理,使它非常适合那些必须在众多网站上都跑得通的自动化场景。
与替代方案的对比 #
另请参阅我们的相关Open Source工具专题。
挑选浏览器自动化工具时,从社区规模、技术路线、易用性和维护情况几方面比较会很有帮助。下面把 Skyvern 与两款广泛使用的替代方案——Selenium WebDriver 和 Playwright——做个对比。请注意,Skyvern 是构建在 Playwright 这类框架之上的更高层 AI 智能体——它们解决的问题有重叠,但并不完全相同。
| 特性 | Skyvern-AI/skyvern | Selenium WebDriver | Playwright | |———————–
|——————————–
|—————————
|—————————–
| | 星标数 | 21,803 | ~31,000 | ~75,000 | | 技术路线 | AI 智能体(LLM + 视觉) | 基于选择器的脚本 | 基于选择器的脚本 | | 编程语言 | Python | Java/Python/JS 等 | JavaScript/Python/.NET/Java | | 易用性 | 用自然语言描述目标 | 需要显式选择器 | 现代 API,需显式选择器 | | 抗 UI 变化能力 | 高(无固定选择器) | 低 | 低 | | 单步速度与成本 | 较慢,每次运行有 LLM 成本 | 快,无 LLM 成本 | 快,无 LLM 成本 | | 浏览器支持 | 经 Playwright 支持 Chromium | 多种浏览器 | Chromium/Firefox/WebKit | | 维护情况 | 活跃 | 活跃、成熟 | 活跃、版本更新频繁 |
详细对比 #
技术路线:这是核心差异。Selenium 和 Playwright 执行你手写的选择器,因此快速、确定,但页面一变就崩。Skyvern 把目标描述给 LLM、由视觉来挑选元素,用速度和成本换取韧性。
易用性:对于你不想维护选择器的任务,Skyvern 降低了门槛——你只需写一条提示词。Selenium 和 Playwright 给你精确控制,但要求你了解页面结构。
何时选哪个:当你掌控目标网站、需要快速可重复的运行时,选 Playwright 或 Selenium。当你需要在众多你无法掌控的网站间自动化、或布局变动频繁到维护选择器才是true正成本时,选 Skyvern。
局限与诚实评估 #
Skyvern 在高韧性浏览器自动化上是把好工具,但也有实实在在的取舍值得了解:
LLM 成本与延迟:每个动作至少涉及一次 LLM 调用,因此 Skyvern 单步比手写脚本更慢、更贵。对于在稳定网站上量大且定义明确的任务,传统的 Playwright 脚本在经济性上可能更划算。
AGPL-3.0 许可证:AGPL-3.0 要求:若你分发软件或将其作为网络服务提供,对软件的修改必须以同一许可证发布。对于偏好宽松或专有许可的组织,这可能是个实质性约束。(Skyvern 也为不想自托管的团队提供了托管云版本。)
非确定性:由于每一步都由 LLM 决定,同一条提示词偶尔会在不同次运行中表现不同。对要求严格、可重复行为的任务,可能需要额外的校验或护栏。
依赖模型质量:结果好坏取决于底层模型。更便宜或本地的模型在复杂页面上可能吃力,而顶级模型又会推高单任务成本。
提示词的学习曲线:尽管你用自然语言描述目标,但要在棘手页面上拿到可靠结果,仍需要一些练习,学会写清晰、具体的提示词和提取 schema。
这些局限意味着:Skyvern 在高韧性、跨网站的自动化上表现出色,但对于在单一稳定网站上量大的工作,它并不总是最合适的工具。
结语 #
Skyvern-AI/skyvern 是一款用 AI 自动化浏览器工作流的能干工具,星标已超 21,800 颗,且维护活跃。如果你的自动化必须挺过布局变化、或要在众多你无法掌控的网站上运行,它的「LLM 加视觉」路线相比基于选择器的脚本是一次实打实的升级。去 GitHub 仓库,跑一句 skyvern quickstart,用你自己的提示词试试看。
- 加入 dibi8 英文 Telegram 群,获取Open Source AI 工具的第一手分享。
- 继续阅读:dibi8 上的相关指南。
来源与延伸阅读:
- GitHub 仓库:https://github.com/Skyvern-AI/skyvern
- 官方文档 / README:https://github.com/Skyvern-AI/skyvern#readme
以上部分链接为联盟链接。若你通过它注册,dibi8.com 可能获得一笔佣金,而你不会有任何额外花费。这有助于网站持续运营、内容保持免费。
💬 留言讨论