lang: zh slug: mastra title: ‘Mastra:超过 24K 颗星——减少 Token 的 TypeScript AI 框架’ description: ‘Mastra 是一个 TypeScript 原生人工智能框架,用于构建来自 Gatsby 团队的人工智能应用程序和代理。 涵盖 Mastra 与 LangChain、安装、工作流程、RAG、内存、可观察性、基准测试和生产强化。’ tags: [“cost-reduction”, “llm”, “open-source”, “token-optimization”] date: 2026-05-19 00:00:00+08:00 lastmod: 2026-05-19 00:00:00+08:00 tech_stack: [] application_domain: Llm Frameworks source_version: ’' licensing_model: Open Source license_type: Apache-2.0 file_size: ’' file_md5: ’' download_url: ’' backup_url: ’' github_repo: ‘https://github.com/mastra-ai/mastra' last_maintained: ‘2026-05-19’ draft: false categories: [’llm-frameworks’] aliases:- /帖子/马斯特拉/ 常见问题解答:
- 问:“Mastra 是什么以及谁建造了它?” a:“Mastra 是一个开源的 TypeScript 原生框架,用于构建人工智能驱动的应用程序和代理,由 Gatsby 团队创建。 它提供了一个统一的工具包,涵盖代理、工作流程、RAG 管道、内存、评估和可观察性,并且构建在 Vercel AI SDK 之上。
- 问:“Mastra 的观察记忆如何将代币成本降低 4-10 倍?” a:“观察记忆将上下文分割成一个稳定的压缩观察块和原始的最近消息。 由于观察块在各个回合中保持一致,因此它仍然完全可缓存,从而避免了传统 RAG 检索导致的提示缓存失效,其中每次缓存未命中都会对缓存令牌带来大约 10 倍的成本损失。
- 问:“安装 Mastra 的系统要求是什么?” a: ‘Mastra 需要 Node.js 22.13.0 或更高版本。 最快的启动方法是通过“npm create mastra@latest”使用 CLI 向导,它构建了一个完整的项目,或者您也可以使用 Zod 和您首选的 AI SDK 提供程序包手动安装“@mastra/core”。
- q:“我可以在 Vercel 之外的其他地方部署 Mastra,例如 AWS 或 DigitalOcean?” ‘是的。 Mastra 是完全开源的,可以在任何 Node.js 运行时上运行。 您可以使用“mastra build”进行构建,并在 DigitalOcean App Platform、AWS ECS、Google Cloud Run 或任何 Docker 主机上运行输出。 Vercel 和 Cloudflare Workers 的专用部署程序是存在的,但是可选的。
- 问:“Mastra 可以免费用于商业用途吗?”
‘是的。 Mastra 根据 Apache 2.0 获得许可,可免费用于商业用途和免费自托管。 Mastra Cloud 提供付费托管层,但核心框架仍然完全开源。
特征图片:/images/articles/llm-frameworks-mastra-24k-e329f2.jpg—
featureImage: /images/articles/mastra-24k-token-typescript-ai.png
——{{< 资源信息 >}}大多数人工智能框架都是为 Python 构建的。 如果您的堆栈在 TypeScript 和 Node.js 上运行,您要么桥接语言,要么接受低于标准的开发人员体验。 当 Gatsby 团队推出 Mastra 时,情况发生了变化。Mastra 是一个用于构建 AI 代理的 TypeScript 原生框架,到 2026 年 5 月达到 24,050 个 GitHub 星,现在已在 Replit、PayPal 和 Sanity 的生产中使用。 本文涵盖了安装 Mastra、构建第一个代理所需的所有内容,并了解其观察内存如何将令牌成本比传统 RAG 方法降低 4-10 倍。## 什么是马斯特拉?Mastra 是一个开源 TypeScript 框架,用于构建人工智能驱动的应用程序和代理。 它提供了一个统一的工具包,涵盖代理、工作流、RAG 管道、内存系统、评估框架和可观察性 - 所有这些都具有一流的 TypeScript 类型。 与移植到 JavaScript 的 Python 优先框架不同,Mastra 是为 TypeScript 生态系统从头开始构建的。 它位于 Vercel AI SDK 之上,用于低级模型交互,并添加了生产 AI 应用程序所需的高级抽象。

常量马斯特拉 = 新马斯特拉({
代理商:{
支持代理,
研究代理,
},
工作流程:{
票务管道,
},
存储: new PgStorage({ connectionString: process.env.DATABASE_URL }),
矢量存储:新的 PgVector(connectionString),
遥测:酒店,
});
## 安装和设置 — 不到 5 分钟Mastra 需要 Node.js 22.13.0 或更高版本。 推荐的路径是 CLI 向导,它使用正确的包结构、配置文件和示例代码构建一个完整的项目。### 第 1 步:创建一个新项目
bas
h
npm 创建 Mastra@latest# 向导提示:
- 项目名称 #
- 组件(代理、工作流程、RAG、内存) #
- LLM 提供商(OpenAI、Anthropic、Google 等) #
- 是否包含示例代码 #
### 步骤 2:手动安装(替代)如果您希望将 Mastra 添加到现有项目中:
bas
h
使用 Zod 为 s``` #
bas h 安装核心包
使用交互式 CLI 搭建一个新的 Mastra 项目 #
npm 创建 Mastra@latest
向导提示: #
- 项目名称 #
- 组件(代理、工作流程、RAG、内存) #
- LLM 提供商(OpenAI、Anthropic、Google 等) #
- 是否包含示例代码 #
:环境设置
bas
h
.env — Mastra 在运行时自动加载这些 #
OPENAI_API_KEY=sk-xxxx
DATABASE_URL=postgresql://用户:pass@localhost:5432/mastra
### 步骤 4:项目结构
我的马斯特拉项目/
├── src/
│ └── 马斯特拉/
│ ├── 代理商/
│ │ └── 支持.ts
│ ├── 工具/
│ │ └── 搜索.ts
│ ├── 工作流程/
│ ````
bas
h
使用 Zod 安装核心包以进行模式验证 #
npm install @mastra/core@latest zod@^4
从 AI SDK 安装您首选的 LLM 提供商 #
npm 安装@ai-sdk/openai
可选:向量存储、内存和部署程序包 #
npm install @mastra/pg @mastra/memory @mastra/deployer-vercel
``根据提示评分
````
typescrip t // src/mastra/agents/support.ts import { Age
bas
h
.env — Mastra loads these automatically at runtime #
OPENAI_API_KEY=sk-xxxx DATABASE_URL=postgresql://user:pass@localhost:5432/mastra
o
o
l
= createTool({
id: 'search-docs',
description: 'Search internal documentation',
inputSchema: z.object({
query: z.string().describe('The search query'),
my-mastra-project/ ├── src/ │ └── mastra/ │ ├── agents/ │ │ └── support.ts │ ├── tools/ │ │ └── search.ts │ ├── workflows/ │ │ └── ticket.ts │ └── index.ts ├── .env ├── package.json └── tsconfig.json
a technical support agent. Answer questions
using the search tool. Be concise and cite sources.`,
model: openai('gpt-4o'),
tools: { searchTool },
});
```### 具有结构化输出的代理``打字稿
// 获取类型对象而不是纯文本
const 结果 = 等待 supportAg```
bas
h
# 在 localhost:4111 启动本地开发 UI
npx 马斯特拉开发
# Studio 可让您与代理聊天、检查工具调用、
# 查看内存状态、可视化工作流程并迭代提示
```'、'中'、'高'、'严重']),
摘要:z.string(),
动作项:z.array(z.string()),
}),
}
);// result.object 是完全类型化的 — TypeScript 知道形状
console.log(结果.对象.优先级); // '高' | '低' | '中等' | “批评”
````### 流式响应```
typescrip
t
// Stream tokens in real-time for chat UIs
const stream = await supportAgent.stream(
'How do I configure environment variables?'
);用于等待``打字稿
// src/mastra/agents/support.ts
从'@mastra/core'导入{代理};
从'@ai-sdk/openai'导入{openai};
从'@mastra/core'导入{createTool};
从 'zod' 导入 { z };
const searchTool = createTool({
id: '搜索文档',
描述: '搜索内部文档',
输入模式: z.object({
query: z.string().describe('搜索查询'),
}),
执行: async ({ context }) => {
// 你的搜索实现
const 结果 = 等待 searchInternalDocs(context.query);
返回{结果};
},
});
导出 const supportAgent = 新代理({
name: '支持代理',
说明:`您是技术支持代理。 回答问题
使用搜索工具。 保持简洁并引用来源。`,
型号:openai('gpt-4o'),
工具:{ 搜索工具 },
});
```架构:z.object({ 升级: z.boolean() }),
执行:异步({输入})=> {
// 升级为高级工程师
wait sendSlackAlert(`高优先级:${input.ticketText}`);
返回{升级:true};
},
});const autoRespondStep = 新步骤({
id: '自动回复',
输出模式: z.object({ 发送: z.boolean() }),
执行:异步({输入})=> {
// 发送自动回复
等待 sendAutoReply(input.ticketText);
返回{发送:true};
},
});导出 const TicketPipeline = 新工作流程({
name: '票务管道',
触发模式:z.object({ticketText:z.string()}),
})
.step(分类步骤)
.then(escalateStep, {
当:{ 'classify.priority': '高' },
})
.then(autoRespondStep, {
当:{ 'classify.priority': ['低', '中'] },
});
````### 并行工作流程执行````打字稿
// 获取类型对象而不是纯文本
const 结果 = 等待 supportAgent.generate(
'对此支持票证进行分类:“无法部署到 Vercel”',
{
输出:z.object({
类别: z.enum(['部署', '计费', 'bug', '功能']),
优先级: z.enum(['低', '中', '高', '关键']),
摘要:z.string(),
动作项:z.array(z.string()),
}),
}
);
// result.object 是完全类型化的 — TypeScript 知道形状
console.log(结果.对象.优先级); // '高' | '低' | '中等' | “批评”
``` stepD 仅在 A、B 和 C 全部完成后运行
````## Integration with Next.js, Node.js, and Vercel AI SDK### Next.js 集成``打字稿
// app/api/agent/route.ts — 在 Next.js 中将代理公开为 API 路由
从'@/mastra'导入{mastra};
从'next/server'导入{NextResponse};导出异步函数 POST(req: Request) {
const { 消息 } = 等待 req.json();
const agent = mastra.getAgent('supportAgent');const 流 = 等待代理.流(消息);返回新的响应(stream.textStream,{
headers: { 'Content-Type': 'text/event-strea``打字稿
// 为聊天 UI 实时传输令牌
const 流 = 等待 supportAgent.stream(
“如何配置环境变量?”
);
for等待(stream.textStream的const块){
process.stdout.write(块); // 当令牌到达时写入它们
}
``宁在 http://localhost:4111
````### Vercel AI SDK 集成Mastra 基于 Vercel AI SDK 构建。 您可以下拉至 SDK 进行底层控制:``打字稿
// Mastra 在底层使用 AI SDK 提供商
从'@ai-sdk/openai'导入{openai};
从'@ai-sdk/anth``打字稿导入{anthropic}
// src/mastra/workflows/ticket.ts
从“@mastra/core”导入{工作流程,步骤};
从 'zod' 导入 { z };
const 分类步骤 = 新步骤({
id: '分类',
inputSchema: z.object({ TicketText: z.string() }),
outputSchema: z.object({ 类别: z.string(), 优先级: z.string() }),
执行: async ({ 输入,mastra }) => {
const agent = mastra.getAgent('supportAgent');
const 结果 = 等待代理.生成(
`分类:${input.ticketText}`,
{ 输出:z.object({ 类别:z.string(),优先级:z.string() }) }
);
返回结果.对象;
},
});
const escalateStep = 新步骤({
id: '升级',
输出模式: z.object({ 升级: z.boolean() }),
执行:异步({输入})=> {
// 升级为高级工程师
wait sendSlackAlert(`高优先级:${input.ticketText}`);
返回{升级:true};
},
});
const autoRespondStep = 新步骤({
id: '自动回复',
输出模式: z.object({ 发送: z.boolean() }),
执行:异步({输入})=> {
// 发送自动回复
等待 sendAutoReply(input.ticketText);
返回{发送:true};
},
});
导出 const TicketPipeline = 新工作流程({
name: '票务管道',
触发模式:z.object({ticketText:z.string()}),
})
.step(分类步骤)
.then(escalateStep, {
当:{ 'classify.priority': '高' },
})
.then(autoRespondStep, {
当:{ 'classify.priority': ['低', '中'] },
});
``` 前缀,使提示缓存无效。 由于 Anthropic 和 OpenAI 都对缓存的提示令牌提供 90% 的折扣,因此每次缓存未命中都意味着缓存部分的成本损失为 10 倍。**解决方案:** 观察记忆将上下文分为两个块 - 压缩观察(仅附加到反射运行)和原始的最近消息。 观察块在各个回合中保持一致,使其完全可缓存。### 按工作负载划分的压缩率| Workload Type | Compression Ratio | Example Scenario |
|---|---|---|
| Text-only conversations | 3-6x | Customer support chat |
| Tool-call-heavy agents | 5-40x | Browser automation, coding agents |
| Agents with large screenshots/files | 10-40x | Playwright DOM snapshots |### LongMemEval 基准测试结果| Memory System | GPT-4o Score | GPT-5-mini Score |
|---|---|---|
| Mastra Observational Memory | 84.23% | 94.87% |
| Mastra RAG (baseline) | 80.05% | — |
| Traditional conversation history | ~72% | — |捕获 Playwright 屏幕截图的浏览器自动化代理可以将 200,000 个会话历史记录压缩为 5,000-15,000 个观察标记,减少了 15-30 倍。### 开发者体验基准| 框架| DX 分数 (1-10) | 设置时间 | 首次代理时间 |
|---|---|---|---|
| 马斯特拉 | 9/10 | < 5 分钟 | 分钟 |
| 浪链(Python)| 5/10 | 15-30 分钟 | 营业时间 |
| 船员人工智能 | 6/10 | 10-15 分钟 | 30 分钟 |
| Vercel AI SDK | 7/10 | < 5 分钟 | 小时(手动接线```打字稿
// 与 .after() 并行运行步骤
从“@mastra/core”导入{工作流程,步骤};
const stepA = new Step({ id: 'fetch-user', /* ... */ });
const stepB = new Step({ id: 'fetch-orders', /* ... */ });
const stepC = new Step({ id: 'fetch-preferences', /* ... */ });
const stepD = new Step({ id: '组合', /* ... */ });
常量并行工作流 = 新工作流({
name: '并行获取',
触发模式: z.object({ userId: z.string() }),
})
.step(步骤A)
.step(步骤B)
.step(步骤C)
.after(步骤A、步骤B、步骤C)
.step(步骤D); // 步骤D仅在A、B和C全部完成后运行
or t { PgStorage } 来自 ‘@mastra/pg’;常量马斯特拉 = 新马斯特拉({ 代理:{ supportAgent }, 内存:新的观察内存({ 存储: new PgStorage({ connectionString: process.env.DATABASE_URL }), observerModel: openai(‘gpt-4o-mini’), // 运行观察者代理 ReflectorModel: openai(‘gpt-4o-mini’), // 运行 Reflector 代理 CompressionInterval: 5, // 每5条消息压缩一次 }), }); ````### RAG 管道设置``打字稿 从 ‘@mastra/rag’ 导入 { MastraRAG }; 从’@ai-sdk/openai’导入{openai}; 从’@mastra/pg’导入{PgVector};const rag = new MastraRAG({ 嵌入器:openai.embedding(’text-embedding-3-small’), vectorStore:新的 PgV```打字稿 // app/api/agent/route.ts — 在 Next.js 中将代理公开为 API 路由 从’@/mastra’导入{mastra}; 从’next/server’导入{NextResponse};
导出异步函数 POST(req: Request) { const { 消息 } = 等待 req.json(); const agent = mastra.getAgent(‘supportAgent’);
const 流 = 等待代理.流(消息);
返回新的响应(stream.textStream,{ headers: { ‘Content-Type’: ’text/event-stream’ }, }); }
odeSDK
({
跟踪导出器:新的 OTLPTraceExporter({
url: 'https://api.honeycomb.io/v1/traces',
}),
});常量马斯特拉 = 新马斯特拉({
代理:{ supportAgent },
工作流程:{ticketPipeline},
遥测:酒店,
});// 痕迹自动出现在您的可观察平台中
// 每个代理调用、工具执行和工作流程步骤都会被检测
````### 护栏和安全``打字稿
从'@mastra/core'导入{代理};
从 '@m```
bas
h
导入 { createGuardrail }
# Mastra 在构建时捆绑了一个 Hono HTTP 服务器
npx Mastra 构建
# 输出到.mastra/output/
# Hono 服务器将代理、工作流程和内存公开为 REST 端点
npx 马斯特拉开始
# 服务器运行在 http://localhost:4111
``好冷吗? '检测到注入':未定义 };
},
});常量 piiGuard = createGuardrail({
id: '无-pii',
检查:异步({输出})=> {
const hasPii = /\b\d{3}-\d{2}-\d{4}\b/.test(输出); // SSN 模式
返回 { 传递:!hasPii,消息:hasPii ? '检测到 PII 泄漏':未定义 };
},
});const agent = new Agent({
name: 'SafeAgent',
model: ope```
typescrip
t
// Mastra uses AI SDK providers under the hood
import { openai } from '@ai-sdk/openai';
import { anthropic } from '@ai-sdk/anthropic';
import { google } from '@ai-sdk/google';
// Switch providers with one-line changes
const agent = new Agent({
name: 'MultiProviderAgent',
instructions: 'You are a helpful assistant.',
model: openai('gpt-4o'), // or anthropic('claude-sonnet-4') or google('gemini-2.0-pro')
tools: { searchTool, calcTool },
});
```appro
v
e
d
};
},
});// Workflow resumes when human approves via Studio or API call
const refundWorkflow = new Workflow({
name: 'refund-pipeline',
triggerSchema: z.object({ amount: z.number(), orderId: z.string() }),
})
.step(validateStep)
.then(humanApprovalStep)
.then(processRefundStep, { when: { 'await-approval.approved': true } });
```### Docker 部署```
dockerfil
e
# 用于生产部署的 Dockerfile
来自节点:22-slim工作目录/应用程序
复制包*.json ./
RUN npm ci --only=产品```打字稿
// 连接到任何 MCP 服务器 — 10,000 多个可用
从“@mastra/core”导入{MCPClient};
const mcpClient = 新 MCPClient({
服务器:{
松弛:{
命令:'npx',
args: ['-y', '@modelcontextprotocol/server-slack'],
env: { SLACK_BOT_TOKEN: process.env.SLACK_TOKEN },
},
github: {
命令:'npx',
args: ['-y', '@modelcontextprotocol/server-github'],
env: { GITHUB_PERSONAL_ACCESS_TOKEN: process.env.GITHUB_TOKEN },
},
},
});
// MCP 工具自动可供您的代理使用
const 工具 = 等待 mcpClient.tools();
常量代理 = 新代理({
name: 'MCPAgent',
型号:openai('gpt-4o'),
tools, // 所有 MCP 工具现在都可用
});
``** | 打字稿 (99.2%) | Python(还有 JS)| 蟒蛇 | 打字稿 |
| **GitHub 之星** | 24,050 | 24,050 117,000 | 39,200 | 39,200 N/A(Vercel 的一部分)|
| **设置时间** | < 5 分钟 | 15-30 分钟 | 10-15 分钟 | < 5 分钟(手动接线)|
| **代理抽象** | 原生代理类| 连锁/代理类| 基于角色的团队 | 手工构图|
| **工作流引擎** | X国基,耐用| LangGraph(图)| 顺序/分层| 无 |
| **内存系统** | 观察记忆(成本降低 4-10 倍)| 对话缓冲区内存 | 仅限短期| 手册|
| **类型安全** | Zod 贯穿始终,完整 TS | 部分JS版本 | Python 类型提示 | 支持佐德 |
| **可观察性** | 内置+OTEL | 朗史密斯 (SaaS) | 内置基本| Vercel平台|
| **MCP 支持** | 本地 | 通过适配器 | 有限公司| 通过整合 |
| **多代理** | 主管模式| LangGraph 多智能体 | 核心特点| 手册|
| **最适合** | TS 团队、Next.js、Node.js | Python 团队,复杂的图表 | Python 多智能体原型设计 | React/Next.js UI 密集型应用程序 | React/Next.js UI 密集型应用程序
| **法学硕士提供者** | 40+ | 100+ | 20+ | 10+ |
| **生产用户** | Replit、PayPal、Sanity | 优步、领英 | 初创公司、机构| Vercel 托管应用程序 |
| **部署** | 任何 Node.js 服务器、Vercel、CF Workers | LangSmith Cloud,自托管 | 自托管,CrewAI 云 | Vercel(最佳)|## 局限性——诚实评估Mastra 并不是适合所有情况的工具。 以下是该框架不擅长的地方:**Python 生态系统锁定:** 如果您的整个数据科学堆栈都是 Python(pandas、NumPy、PyTorch、Jupyter),Mastra 会迫使您连接两种语言。 该框架仅支持 TypeScript。 对于深度投入 Python 的团队来说,LangChain 或 CrewAI 仍然是更自然的选择。**较小的集成生态系统:** LangChain 拥有 100 多个 LLM 集成和 50 多个向量商店。 Mastra 支持 40 多个提供商并涵盖主要矢量数据库,但如果您需要一个晦涩的模型或利基矢量存储,您可能需要编写自定义集成代码。**项目更年轻,流失率更高:** Mastra 于 2026 年 1 月发布 v1.0。API 已经稳定,但与 LangChain 成熟的生态系统相比,重大变化仍然发生得更频繁。 预算版本升级的时间。**没有本机可视化工作流程生成器:** 与 n8n 或 Langflow 不同,Mastra 没有拖放工作流程设计器。 一切都是代码。 对于需要修改工作流程的非技术团队成员来说,这是一个障碍。**社区规模:** Mastra 的社区拥有 24K 颗星,活跃但明显小于 LangChain 的社区。 您会发现 Stack Overflow 答案越来越少,第三方教程越来越少,涵盖边缘案例的博客文章也越来越少。**有限的 UI 组件:** 虽然 Mastra Studio 提供了开发平台,但它不提供聊天小部件等生产 UI 组件。 您仍然需要自己构建前端或将 Mastra 与 Vercel AI SDK 的 UI 库配对。## 常见问题**问:Mastra 是否需要 TypeScript 知识```
typescrip
t
从'@mastra/core'导入{Mastra};
从'@mastra/memory'导入{ObservationalMemory};
从'@mastra/pg'导入{PgStorage};
常量马斯特拉 = 新马斯特拉({
代理:{ supportAgent },
内存:新的观察内存({
存储: new PgStorage({ connectionString: process.env.DATABASE_URL }),
observerModel: openai('gpt-4o-mini'), // 运行观察者代理
ReflectorModel: openai('gpt-4o-mini'), // 运行 Reflector 代理
CompressionInterval: 5, // 每5条消息压缩一次
}),
});
e s 提示缓存。 Mastra 的观察内存将上下文压缩为可缓存的观察结果,实现了 4-10 倍的成本降低,同时在 LongMemEval 基准测试中得分更高(84.23% vs RAG 的 80.05%)。问:我可以在 DigitalOcean 或 AWS 上部署 Mastra 而不是 Vercel 吗? 是的。 Mastra 是完全开源的,可以部署到任何 Node.js 运行时。 使用“mastra build”进行构建,然后在 DigitalOcean 应用平台、AWS ECS、Google Cloud Run 或任何 Docker 主机上运行输出。 Vercel 和 Cloudflare Workers 都有部署程序,但它们是可选的``typescript 从 ‘@mastra/rag’ 导入 { MastraRAG }; 从’@ai-sdk/openai’导入{openai}; 从’@mastra/pg’导入{PgVector};
const rag = new MastraRAG({ 嵌入器:openai.embedding(’text-embedding-3-small’), 矢量存储:新的 PgVector({ 连接字符串:process.env.DATABASE_URL, 尺寸:1536, }), 块大小:512, 块重叠:50, });
// 索引文档 等待 rag.index(documentBatch);
// 相似度搜索查询 const results = wait rag.query(‘如何配置 SSO?’, { topK: 5 }); ``直接识别和调试生产中的故障。问:Mastra 可以免费用于商业用途吗? 是的。 Mastra 根据 Apache 2.0 获得许可,可免费用于商业用途。 Mastra Cloud(托管托管)提供付费套餐,但核心框架是完全开源的,并且可以免费自行托管。问:如何向现有 Mastra 代理添加内存? 创建Mastra实例时传递一个内存实例。 代理自动跟踪每个用户的对话线程。 对于多轮对话,使用存储后端初始化内存(PostgreSQL、li``` typescrip t 从’@mastra/core’导入{Mastra}; 从 ‘@opentelemetry/sdk-node’ 导入 { NodeSDK };
const 酒店 = 新 NodeSDK({ 跟踪导出器:新的 OTLPTraceExporter({ url: ‘https://api.honeycomb.io/v1/traces', }), });
常量马斯特拉 = 新马斯特拉({ 代理:{ supportAgent }, 工作流程:{ticketPipeline}, 遥测:酒店, });
// 痕迹自动出现在您的可观察平台中 // 每个代理调用、工具执行和工作流程步骤都会被检测 TypeScript 团队从想法到部署代理的路径。如果您正在将 AI 功能构建到 Next.js 应用程序、Node.js 服务或任何 TypeScript 项目中,Mastra 值得认真评估。 从“npm create mastra@latest”开始,构建工作流程,并自行衡量代币成本差异。Action items:
- Clone the Mastra repo and run the quickstart:
npm create mastra@latest - Join the Mastra Discord community (5,500+ members)
- Explore the``` typescrip t import { Agent } from ‘@mastra/core’; import { createGuardrail } from ‘@mastra/core’;
const promptInjectionGuard = createGuardrail({ id: ’no-prompt-injection’, check: async ({ input }) => { const suspicious = /ignore previous|disregard instructions/i.test(input); return { passed: !suspicious, message: suspicious ? ‘Injection detected’ : undefined }; }, });
const piiGuard = createGuardrail({ id: ’no-pii’, check: async ({ output }) => { const hasPii = /\b\d{3}-\d{2}-\d{4}\b/.test(output); // SSN pattern return { passed: !hasPii, message: hasPii ? ‘PII leak detected’ : undefined }; }, });
const agent = new Agent({ name: ‘SafeAgent’, model: openai(‘gpt-4o’), tools: { searchTool }, guardrails: [promptInjectionGuard, piiGuard], });
- [Mastra GitHub Repository](https://github.com/mastra-ai/mastra)
- [Mastra Documentation](https://mastra.ai/docs)
- [Mastra Course - Learn to Build AI Agents](https://mastra.ai/course)
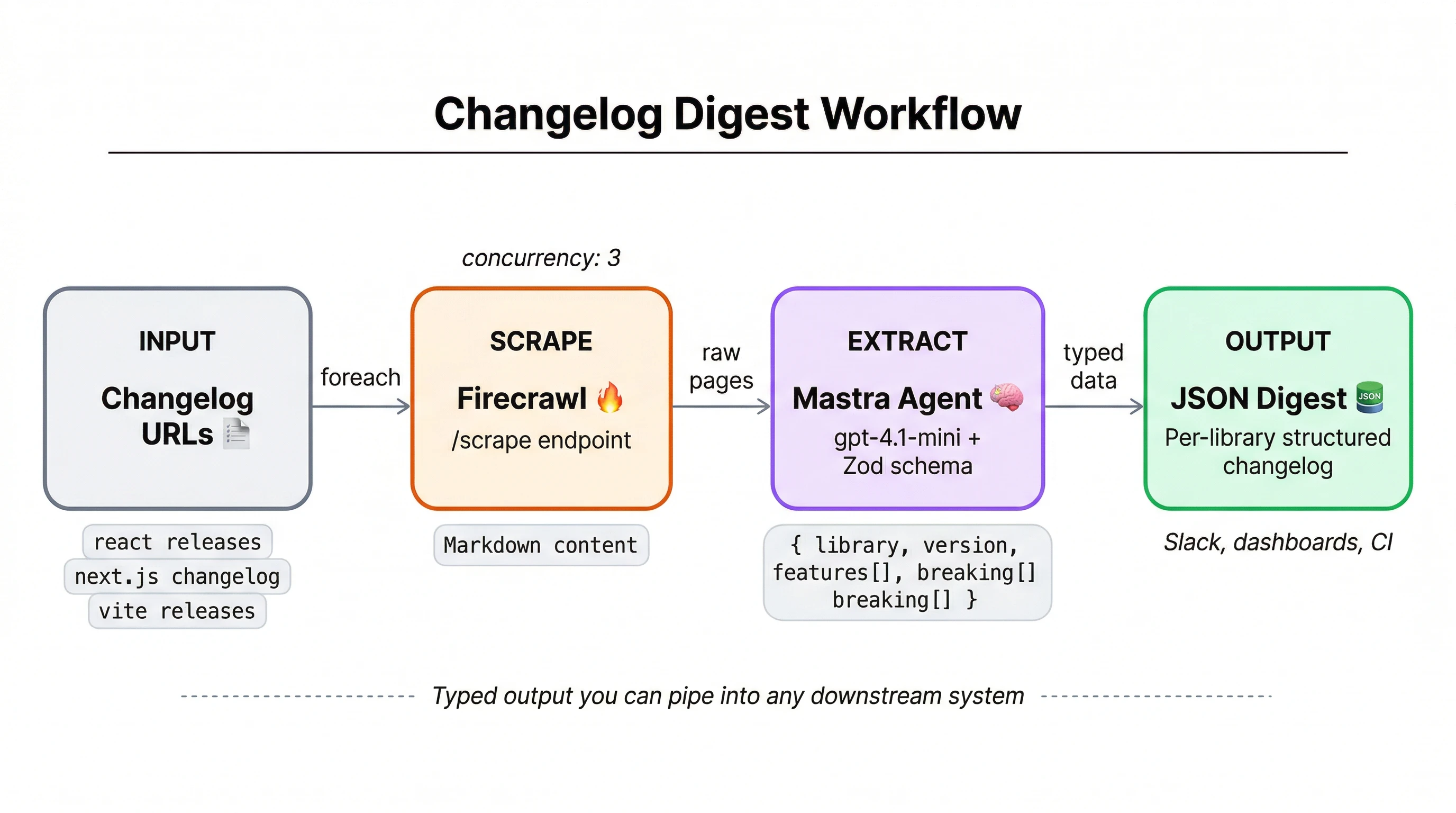
- [Mastra Tutorial: Changelog Tracker with Firecrawl](https://www.firecrawl.dev/blog/mastra-tutorial)
- [Mastra Observational Memory Deep Dive](https://agentmarketcap.ai/blog/2026/04/13/mastra-observational-memory-observer-reflector-pattern-agent-costs-longmemeval-2026)
- [ByteIota: Mastra TypeScript AI Framework Analysis](https://by```
typescrip
t
import { Workflow, Step } from '@mastra/core';
const humanApprovalStep = new Step({
id: 'await-approval',
outputSchema: z.object({ approved: z.boolean() }),
execute: async ({ suspend }) => {
// Suspend workflow and wait for human input
const { approved } = await suspend({ reason: 'Refund exceeds $500' });
return { approved };
},
});
// Workflow resumes when human approves via Studio or API call
const refundWorkflow = new Workflow({
name: 'refund-pipeline',
triggerSchema: z.object({ amount: z.number(), orderId: z.string() }),
})
.step(validateStep)
.then(humanApprovalStep)
.then(processRefundStep, { when: { 'await-approval.approved': true } });
```Cre
w
A
I
GitHub Repository](https://github.com/crewAIInc/crewAI)
- [Vercel AI SDK Documentation](https://sdk.vercel.ai/docs)<!--自动引用-->
## 参考文献和来源- [Mastra](https://github.com/mastra-ai/mastra)
- [Vercel AI SDK](https://sdk.vercel.ai/docs)
- [Zod](https://github.com/colinhacks/zod)
- [XState](https://github.com/statelyai/xstate)
- [模型上下文协议(MCP)](https://github.com/modelcontextprotocol)
- [Hono](https://github.com/honojs/hono)
- [OpenTelemetry](https://github.com/open-telemetry/opentelemetry-js)
- [pgvector](https://github.com/pgvector/pgvector)
- [LangChain](https://github.com/langchain-ai/langchain)
- [CrewAI](https://github.com/crewAIInc/crewAI)
dockerfil e
用于生产部署的 Dockerfile #
来自节点:22-slim
工作目录/应用程序 复制包*.json ./ 运行 npm ci –only=生产
复制。 。 运行 npx Mastra 构建
暴露4111 CMD [“节点”,“.mastra/output/index.mjs”]
yam
l
# docker-compose.yml
版本:'3.8'
服务:
马斯特拉:
构建: .
端口:
- “4111:4111”
环境:
- OPENAI_API_KEY=${OPENAI_API_KEY}
- DATABASE_URL=postgresql://postgres:postgres@db:5432/mastra
取决于:
- 数据库
数据库:
图片:pgvector/pgvector:pg17
环境:
POSTGRES_USER:postgres
POSTGRES_PASSWORD:postgres
POSTGRES_DB:马斯特拉
卷:
- pgdata:/var/lib/postgresql/data
卷:
PG数据:
````
💬 留言讨论