Promptfoo:测试、评估和红队您的 LLM 提示
Promptfoo 是一款Open Source的 CLI 与代码库,用于评估和红队 LLM 应用。用简单的声明式配置即可对比 GPT、Claude、Gemini、DeepSeek,并无缝接入命令行与 CI/CD。本 2026 指南讲解安装、promptfooconfig.yaml、断言与红队测试。
- MIT
- 更新于 2026-06-02
引言 #
如果你在用 GPT、Claude、Gemini 或 DeepSeek 这类模型做开发,你一定明白「在 playground 里看着不错」和「在生产环境里稳定可用」完全是两码事。Promptfoo 是一款Open Source的 CLI 与代码库,用于评估和红队 LLM 应用。它把反复试错的工作方式,换成可以本地运行、也能接入 CI/CD 的声明式测试配置。本文将带你安装它、编写 promptfooconfig.yaml、跑一次评估、对比不同模型,并发起一次红队扫描。
Promptfoo 是什么? #
Promptfoo 是一款用于评估和红队 LLM 应用的 CLI 与代码库。你只需描述自己的提示词、希望对哪些 provider(模型)运行,以及一组带断言的测试用例。Promptfoo 会让每条提示词跑遍每个测试用例、逐项检查断言,并给出各模型表现的并排对比视图。
它的核心能力包括:
- 评估 —— 让提示词在多个 provider 上运行,并用断言为输出打分(精确匹配、包含、语义相似度、LLM 评分量规等)。
- 模型对比 —— 在相同输入下对比 GPT、Claude、Gemini、DeepSeek 等模型。
- 红队测试 —— 生成对抗性测试用例,在上线前探测应用的安全漏洞。
- CI/CD 集成 —— 声明式配置能在任何有终端的地方运行,包括 GitHub Actions。
该项目用 TypeScript 编写,采用 MIT 许可证,由 promptfoo 团队维护。
Promptfoo 如何工作 #
它的工作流以配置为先:
声明式配置 —— 一份
promptfooconfig.yaml就定义了你的prompts、providers和tests,常见场景无需任何粘合代码。命令行界面(CLI) —— 用
promptfoo eval跑评估。它会把结果表格打印到终端,并把结果保存在本地。本地网页查看器 ——
promptfoo view会打开一个本地网页界面,可视化呈现评估结果,让你逐格对比各模型的输出。
下面是一份最小化的 promptfooconfig.yaml:
a
m
l
prompts:
- "What is the capital of {{country}}?"
- "Explain quantum mechanics in one sentence."
providers:
- openai: gpt-4o-mini
- anthropic: messages: claude-3-5-sonnet-20241022
tests:
- vars:
country: France
assert:
- type: contains
value: Paris
这份配置会让两条提示词分别对两个 provider 运行。对第一条提示词,它会替换 {{country}} 并断言输出中包含 “Paris”。API 密钥从环境变量读取(例如 OPENAI_API_KEY 和 ANTHROPIC_API_KEY),不会写在配置文件里。
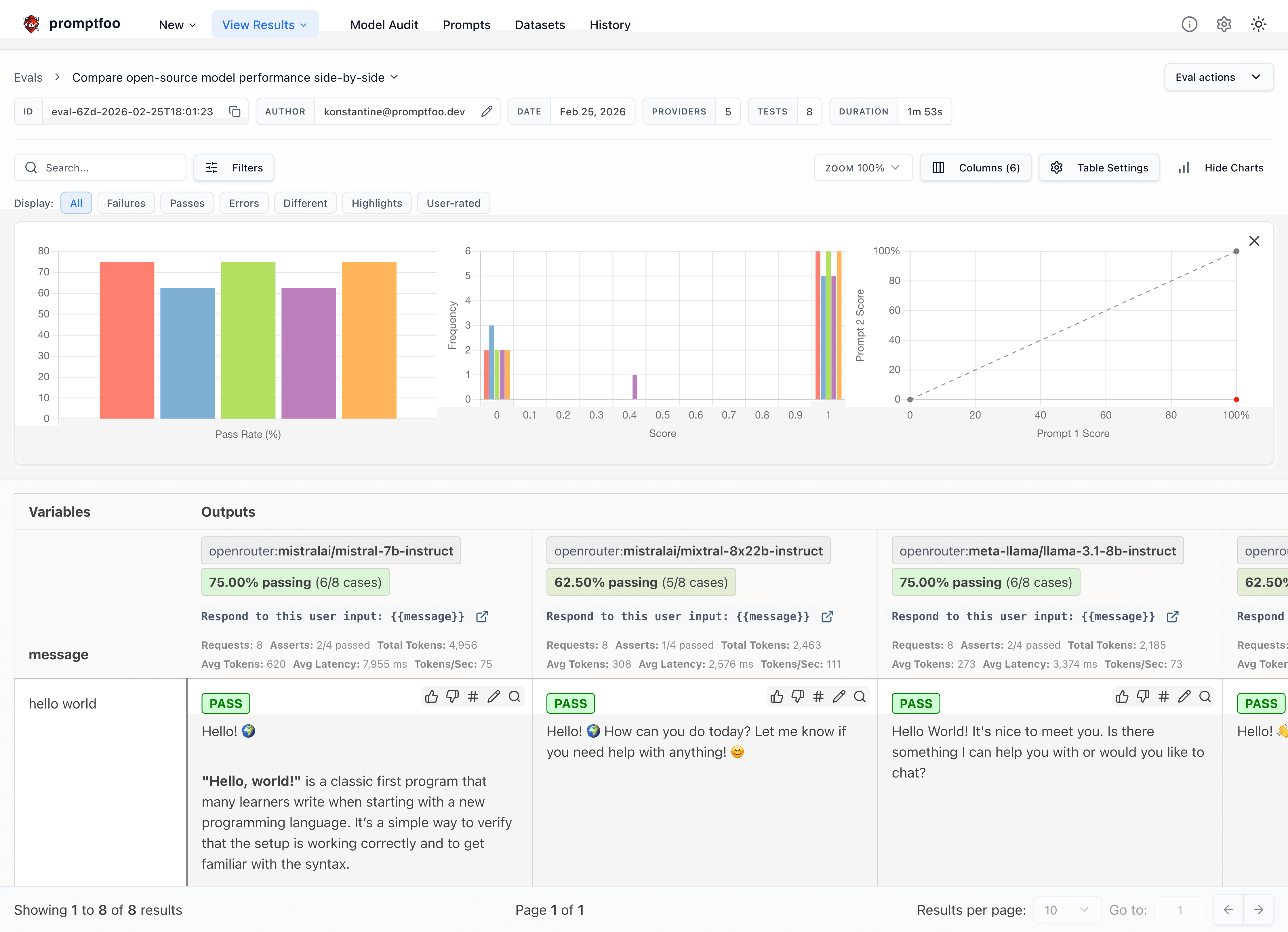
- Source Code: promptfoo GitHub

promptfoo 自评视图(来源:promptfoo/promptfoo 仓库,经 dibi8 分析整理)
安装与配置 #
如果你想把 promptfoo 当成定时生产任务来跑,就需要一台常开的机器 —— 可以在 DigitalOcean 上开一台(新账户有免费试用额度),或者用 HTStack 的低延迟香港 VPS(与托管 dibi8.com 的是同一家 IDC)。
Promptfoo 需要 Node.js ^20.20.0 或 >=22.22.0。先检查版本:
a
s
h
node -v
如果还没装 Node.js,可以从官网获取。
安装 #
体验 promptfoo 最快的方式是完全不安装:
a
s
h
npx promptfoo@latest init --example getting-started
如果想全局安装,按你的环境选一种即可:
a
s
h
# npm
npm install -g promptfoo
# Homebrew
brew install promptfoo
# pip
pip install promptfoo
设置 API 密钥 #
Promptfoo 从环境变量读取 provider 凭证。以 OpenAI 为例:
a
s
h
export OPENAI_API_KEY=sk-abc123
测试哪个 provider,就用它对应的变量(例如测试 Claude 用 ANTHROPIC_API_KEY)。如果忘了设密钥,跑评估时 provider 会返回认证错误 —— 设好变量重新运行即可。
跑你的第一次评估 #
执行 init 后,当前目录会有一份 promptfooconfig.yaml。运行评估并打开查看器:
a
s
h
promptfoo eval
promptfoo view
promptfoo eval 会把结果打印到终端;promptfoo view 则打开一个本地网页界面,方便做更丰富的并排对比。如果卡住了,可以查阅官方文档或在 GitHub 上提 issue。
核心用法 #
示例 1:一个简单断言 #
写一份检查预期子串的配置:
a
m
l
description: "Basic prompt test"
prompts:
- "What is the capital of {{country}}?"
providers:
- openai: gpt-4o-mini
tests:
- vars:
country: France
assert:
- type: contains
value: Paris
运行:
a
s
h
promptfoo eval
Promptfoo 会执行该测试用例,并报告断言是否通过。
示例 2:用多种断言类型对比模型 #
你可以列出多个 provider,并混用多种断言类型 —— 精确、语义和 LLM 评分:
a
m
l
description: "GPT vs Claude comparison"
prompts:
- "Answer concisely: {{question}}"
providers:
- openai: gpt-4o
- anthropic: messages: claude-3-5-sonnet-20241022
defaultTest:
assert:
- type: llm-rubric
value: does not describe itself as an AI, model, or chatbot
tests:
- vars:
question: "What is the meaning of life?"
assert:
- type: similar
value: "It depends on the person"
threshold: 0.6
运行同样的命令,再用 promptfoo view 逐格对比两个模型:
a
s
h
promptfoo eval
示例 3:在 CI/CD 流水线中运行 #
只要有终端,promptfoo 就能跑。下面这个 GitHub Actions 工作流会在断言失败时让构建失败:
a
m
l
# .github/workflows/eval.yml
name: Promptfoo Eval
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
eval:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: '22'
- name: Run promptfoo eval
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: npx promptfoo@latest eval
它会在每次 push 和 pull request 时运行你的评估套件,在合并前抓住回归问题。
红队测试 #
除了普通评估,promptfoo 还能生成对抗性测试用例,探测应用是否存在提示词注入、越狱、不安全输出等漏洞。红队流程有自己的子命令:
a
s
h
# 启动配置 UI,设置你的目标和攻击类型
npx promptfoo@latest redteam setup
# 或者不用图形界面进行配置
promptfoo redteam init --no-gui
# 生成对抗性用例并对目标运行
promptfoo redteam run
# 查看发现的问题报告
promptfoo redteam report
报告会按漏洞类别和严重程度归类,并给出建议的缓解措施。
基准测试与true实使用 #
Promptfoo 被广泛用于提示词和模型评估。但它的精髓不在于依赖某个单一排行榜,而在于让你用自己的提示词和测试用例来做基准 —— true正有意义的数字,来自你自己的应用,而非通用套件。
典型工作流是这样的:
a
s
h
npx promptfoo@latest eval && npx promptfoo@latest view
让完整测试集跑遍候选模型,再打开查看器,就能精确看到每个模型在哪些提示词、哪些用例上通过或失败。由于配置是声明式的,同一套件既能在开发时本地运行,也能在 CI 里每次提交时运行。
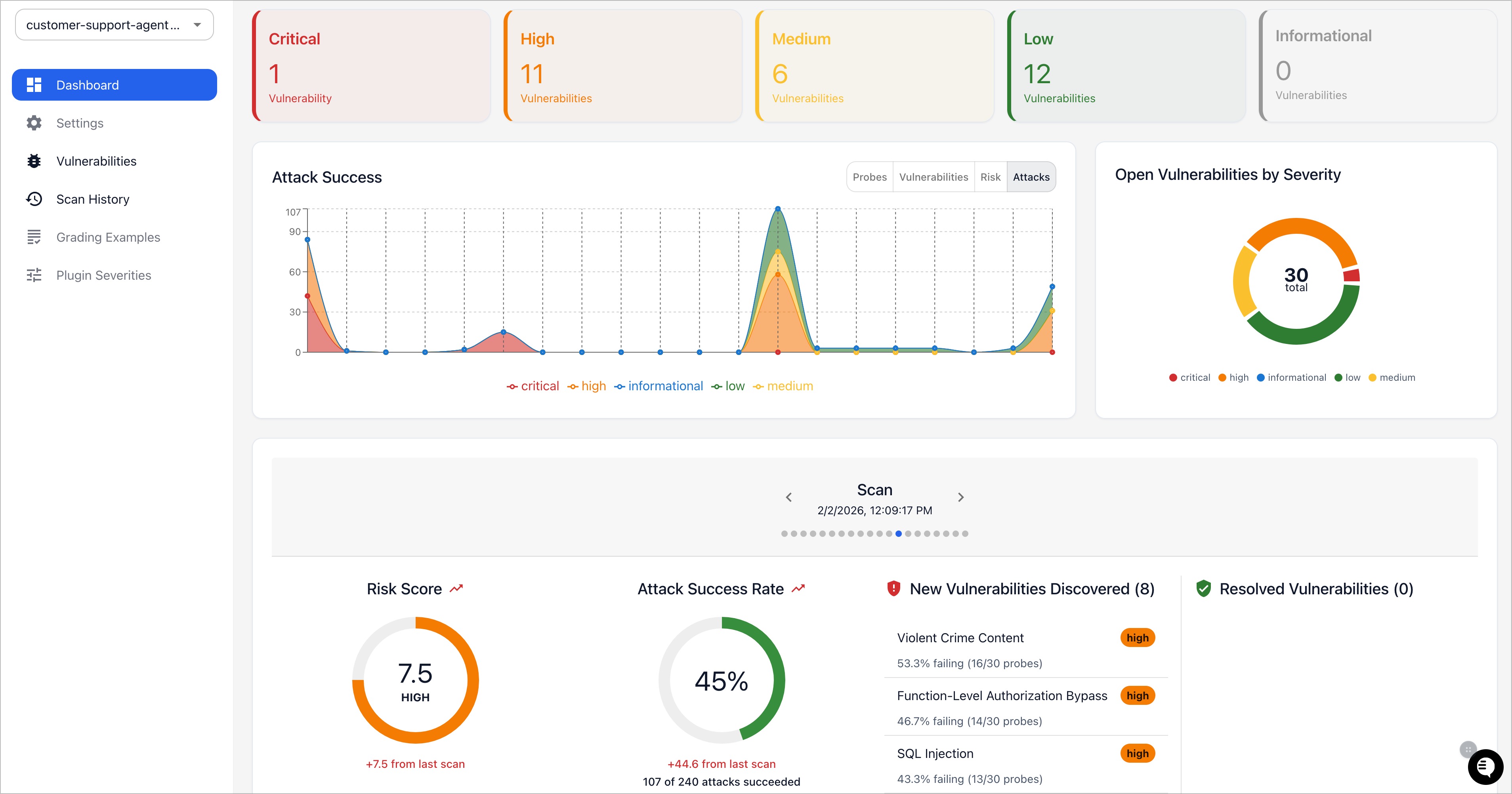
promptfoo 红队仪表盘(来源:promptfoo/promptfoo 仓库,经 dibi8 分析整理)
与同类工具对比 #
也可以看看我们对相关Open Source工具的整理。
在挑选 LLM 评估与红队工具时,promptfoo 的主要吸引力在于:声明式配置、本地优先的工作流,以及内置的红队能力三者结合。
| 特性 | promptfoo | |———————–
|—————————————————————————
|
| Star 数 | 21,825 |
| 许可证 | MIT |
| 维护方 | promptfoo |
| 语言 | TypeScript |
| 默认分支 | main |
| 配置方式 | 声明式 promptfooconfig.yaml(prompts / providers / tests / assert) |
| 使用界面 | CLI(promptfoo eval / view)以及作为代码库调用 |
| 模型覆盖 | GPT、Claude、Gemini、DeepSeek 等众多 provider |
| 红队 | 内置(promptfoo redteam 子命令) |
| CI/CD | 在任意终端运行;对 GitHub Actions 有一流支持 |
细节拆解 #
- Star 数 —— promptfoo 在 GitHub 上约有 21,825 个 star,是 LLM 开发者群体广泛采用的有力信号。
- 声明式配置 —— 把测试写进
promptfooconfig.yaml,能让你的评估套件与代码一起进版本管理,从而本地和 CI 跑的是同一套检查。
局限与客观评价 #
Promptfoo 很能干,但也有值得了解的取舍:
- 配置会随复杂度膨胀 —— 声明式格式应对常见场景很爽,但当套件涉及大量 provider、动态变量和自定义断言时,会变得啰嗦。你往往得把提示词和测试用例拆到单独的文件里。
- 模型访问要你自己出 —— promptfoo 负责编排评估,但依赖你自己的 provider API 密钥和配额。费用和速率限制要你自己扛。
- 评估要花 token 和时间 —— 跨多个 provider 的大套件会发出大量 API 调用。在大型测试集上,延迟和花费都会累加。
- 断言设计需要琢磨 —— LLM 评分量规(
llm-rubric)和语义检查很强大,但具有不确定性;要写出可靠、有意义的断言需要反复打磨。 - 仍在快速演进 —— promptfoo 发版频繁。这意味着改进很快,但偶尔会有破坏性变更;在 CI 里固定一个版本会更稳。
在把它定为团队标准前,这些都是要权衡的点。
结语 #
Promptfoo 把提示词和模型测试,从凭感觉的猜测变成了可复现、可进版本管理的流程。一份 promptfooconfig.yaml,就能评估提示词、在你自己的数据上对比 GPT、Claude、Gemini 和 DeepSeek,并为应用做红队漏洞探测 —— 这一切都在 CLI 和 CI/CD 中完成。最佳的下一步,是运行 npx promptfoo@latest init --example getting-started,把它指向你自己的提示词,再打开查看器看看你的模型究竟表现如何。
大规模抓取需要轮换代理 —— WebShare 是业界常用之选。
- 加入 dibi8 英文 Telegram 群,获取Open Source AI 工具速递。
- 延伸阅读:dibi8 上的相关指南。
来源与延伸阅读:
- GitHub 仓库:https://github.com/promptfoo/promptfoo
- 官方文档 / README:https://github.com/promptfoo/promptfoo#readme
以上部分链接为联盟链接。若你通过它注册,dibi8.com 可能获得一笔佣金,你无需为此多付任何费用。这有助于网站运转、内容免费。
💬 留言讨论