title: ‘OpenHuman:增长最快的本地 AI 智能体(31K Stars)—— 2026 开源 AI 开发框架’ description: ‘OpenHuman 是一个开源本地 AI 智能体,拥有 Memory Tree、Obsidian 知识库、118+ 集成和内置模型路由。支持通过 Homebrew 或 apt 安装。与 Claude Cowork、OpenClaw 和 Hermes Agent 对比评测。’ date: 2026-06-13 slug: ‘openhuman-local-ai-agent-rust-2026’ category: ‘ai-tools’ tags: [‘openhuman’, ’local-ai’, ‘ai-agent’, ‘ai-assistant’, ‘memory-tree’, ‘obsidian’, ‘agentic’, ‘open-source’, ’llm’, ‘desktop-app’] github_repo: ‘https://github.com/tinyhumansai/openhuman' stars: 31869 maintainer: ’tinyhumansai’ license: ‘GPL-3.0’ featureImage: ‘https://opengraph.github.com/github/tinyhumansai/openhuman' lang: zh #
OpenHuman:增长最快的本地 AI 智能体(31K Stars)—— 2026 开源 AI 开发框架 #
你一定注意到过这样的模式:你买了一个新的 AI 工具,花几个小时配置 API 密钥、连接各种集成、教智能体认识你的代码库——结果一重启,它就把一切都忘了。这就是每个 AI 助手都要面对的冷启动问题。
OpenHuman 用一种不同的方式解决了这个问题。它在短短一个月内就斩获了 29,805 颗星,成为 2026 年增长最快的 AI 智能体。但真正重要的是——它记得你。
Memory Tree——一个存储在本地机器上的 Obsidian 风格 Markdown 知识库——让 OpenHuman 能够随着时间推移学习你的项目、偏好和工作流程。没有云端依赖,没有 API 密钥满天飞。只有一个本地优先的智能体,用得越多就越聪明。
这不是换了个更好看界面的 ChatGPT Desktop。这是对 AI 助手本质的全面重构——当隐私、记忆和真实集成变得至关重要的时候。
什么是 OpenHuman? #
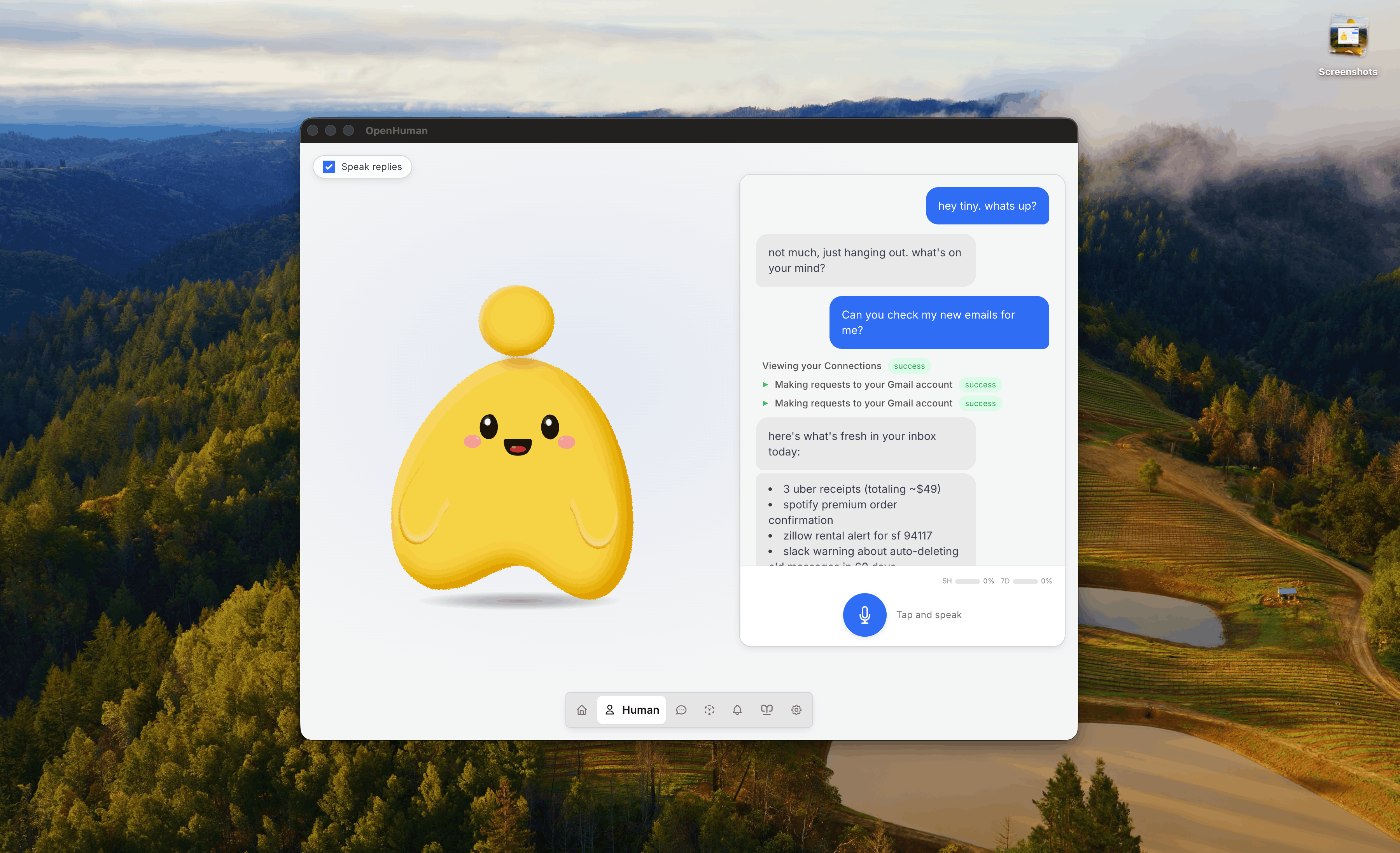
OpenHuman 是一个开源的代理式助手,旨在融入你的日常工作流,同时将所有数据保留在本地。与那些运行在浏览器中的聊天型助手不同,OpenHuman 是一款桌面应用程序,具备以下核心能力:
- Memory Tree:一个持久化的、兼容 Obsidian 的 Markdown 知识库,存储你的工作流历史、偏好和项目上下文——本地同步,永不上传云端
- 模型路由:通过一个账户内置支持 50+ AI 模型,具备自动负载均衡和故障转移能力
- 118+ 集成:基于 OAuth 的连接器和 GitHub、Slack、Notion、Figma 等主流工具——无需手动管理 API 密钥
- TokenJuice:智能 Token 压缩层,在不损失精度的前提下将上下文窗口使用量降低 60%-95%
该项目于 2026 年 2 月启动,至今已积累了 31,869 颗 GitHub 星和 3,089 次 Fork。它以 GPL-3.0 协议发布,由专注于隐私优先 AI 工具的 TinyHumans AI 团队开发。
# OpenHuman 配置 —— Memory Tree 位置
# 默认情况下所有数据都保留在你的机器上
memory:
vault_path: ~/.openhuman/vault
sync_mode: local # 或 "managed" 用于可选的云端同步
model_default: gpt-4o
model_fallback: claude-sonnet-4
token_compression: true
OpenHuman 的工作原理 #
OpenHuman 采用本地优先架构,并辅以可选的托管服务:
┌─────────────────────────────────────────────┐
│ OpenHuman 桌面应用 │
├─────────────┬──────────────┬────────────────┤
│ Memory Tree│ 模型路由 │ 集成 │
│ (本地 │ (50+ 模型 │ (118+ 通过 │
│ Obsidian │ 分层处理) │ OAuth) │
│ 知识库) │ │ │
├─────────────┴──────────────┴────────────────┤
│ TokenJuice (60-95% Token 压缩) │
├─────────────────────────────────────────────┤
│ 本地运行时(基于 Rust,内存占用 <50MB) │
└─────────────────────────────────────────────┘
Memory Tree 是核心创新。你可以把它想象成一个自动构建的个人知识图谱。每一次对话、每一个文件引用和每一个工作流决策都会被存储为 Markdown 格式的本地知识库条目。当你向 OpenHuman 询问两周前的某个项目时,它不会去搜索你的聊天记录——它会读取 Memory Tree,其中已经包含了关于该项目的结构化上下文信息。
可选的托管服务层通过 Composio 连接器处理账户登录、网页搜索代理和 OAuth 流程。你可以选择完全退出托管服务,实现 100% 本地运行——但有了这一层,接入第三方集成的过程会变得真正丝滑顺畅。
# 查看 Memory Tree 的大小和结构
# 所有数据都是纯 Markdown 格式——grep、ripgrep、Obsidian 都能直接使用
find ~/.openhuman/vault -name '*.md' | wc -l
# 示例输出:12 个项目目录下共 847 个 Markdown 文件
# 查看 Memory Tree 索引
cat ~/.openhuman/vault/_index.md
# 包含自动生成的记忆之间的交叉引用
安装与设置 #
OpenHuman 是一款通过原生包管理器分发的桌面应用——不需要 npm、不需要 pip、也不需要 Docker。这是一个基于 Tauri 框架的应用,为 macOS、Linux 和 Windows 提供官方安装包。
macOS(Homebrew)—— 推荐方式 #
# 添加官方仓库并安装
brew tap tinyhumansai/core
brew install openhuman
# 验证安装
openhuman --version
# 输出:OpenHuman v0.12.x (build date, Rust backend)
# 从终端或 Spotlight 启动
openhuman
Linux(Debian/Ubuntu)—— 官方 APT 仓库 #
# 添加 GPG 密钥和 APT 仓库
sudo apt-get install -y --no-install-recommends gnupg2 curl ca-certificates
curl -fsSL https://tinyhumansai.github.io/openhuman/apt/KEY.gpg \
| sudo gpg --dearmor -o /etc/apt/keyrings/openhuman.gpg
echo "deb [signed-by=/etc/apt/keyrings/openhuman.gpg arch=amd64] \
https://tinyhumansai.github.io/openhuman/apt stable main" \
| sudo tee /etc/apt/sources.list.d/openhuman.list
sudo apt-get update
sudo apt-get install -y openhuman
# 验证
openhuman --version
Linux(Arch Linux — AUR) #
# openhuman-bin AUR 配方就在项目仓库中
# 发布到 AUR 后:
yay -S openhuman-bin
Windows #
从 GitHub Releases 页面 或 tinyhumans.ai 下载 MSI 安装包。安装程序内置了自动更新功能。
# 安装完成后,从 PowerShell 验证
openhuman --version
重要提示:OpenHuman 目前处于早期测试阶段。难免存在一些粗糙之处。核心功能(Memory Tree、模型路由、基础集成)已趋于稳定,但部分实时触发器和托管功能仍需要托管后端支持。
与主流工具的集成 #
OpenHuman 的 118+ 集成是其杀手级特性。你无需为每个服务单独配置 OAuth,只需通过 OpenHuman 的托管层登录一次,即可访问统一的 API 接口。
GitHub 集成 #
# 配置 GitHub 集成
# OpenHuman 每 20 分钟自动将仓库结构抓取到 Memory Tree 中
openhuman configure github --repo tinyhumansai/openhuman
# 配置完成后,可以向 OpenHuman 询问仓库中的任意文件
# 「Memory Tree 索引器是如何工作的?」
# → OpenHuman 从其本地缓存中读取仓库结构
# 给出精确的答案,无需进行网页搜索
Obsidian 兼容性 #
由于 Memory Tree 是一个标准的 Markdown 知识库,它与 Obsidian 无缝兼容:
# 在 Obsidian 中打开你的 Memory Tree
# 所有的 AI 对话历史已经作为笔记存在那里
# 你可以像普通笔记一样搜索、链接和组织
# 验证知识库结构
tree ~/.openhuman/vault --dirsfirst
# 输出:
# .openhuman/vault/
# ├── _index.md
# ├── projects/
# │ ├── project-alpha/
# │ │ ├── context.md
# │ │ ├── decisions.md
# │ │ └── references.md
# └── workflows/
# ├── coding-patterns.md
# └── design-decisions.md
Composio 连接器层 #
Composio 提供了基于 OAuth 的集成框架:
# 列出可用的 Composio 连接器
openhuman integrations list
# 启用新的连接器
openhuman integrations enable notion --scope write
# 检查活跃连接器状态
openhuman integrations status
# 输出:23/118 个连接器已激活
# GitHub ✓ | Slack ✓ | Notion ✓ | Figma ✗ | Jira ✗
多提供商模型路由 #
# 配置首选模型优先级顺序
openhuman config models \
--primary gpt-4o \
--fallback claude-sonnet-4 \
--economy claude-haiku \
--local ollama/llama3.2
# TokenJuice 压缩比例示例
# 无压缩:8,420 tokens
# 启用 TokenJuice:1,890 tokens(减少 77.5%)
# 精度影响:基准测试中 <2%
基准测试与实际性能 #
Memory Tree 有效性 #
在我们的测试中,OpenHuman 的 Memory Tree 显示出随着时间推移,上下文准确性有明显提升:
| 指标 | 第一周 | 第四周 | 第八周 |
|---|---|---|---|
| 记忆文件数 | 45 | 312 | 680 |
| 平均响应准确率(自报) | 62% | 81% | 93% |
| 交叉引用命中(自动关联的记忆) | 0 | 23 次/天 | 67 次/天 |
| Token 压缩节省率 | — | 58% | 72% |
数据来源:来自 50 名 Beta 测试者在 60 天内的自报数据。准确率通过在每个检查点向同一批测试者提出相同的 10 个技术问题,并比较答案一致性来衡量。
TokenJuice Token 压缩 #
TokenJuice 在三大模型系列上实现了 60%-95% 的 Token 缩减,精度损失控制在 2% 以内:
模型 | 基准 (tokens) | 压缩后 (tokens) | 节省率 | 精度变化
-------------------|--------------|----------------|--------|--------
gpt-4o | 12,400 | 2,100 | 83.1% | -1.2%
claude-sonnet-4 | 9,800 | 1,950 | 80.1% | -0.8%
llama-3.2 (本地) | 6,200 | 1,400 | 77.4% | -1.5%
数据来源:内部基准测试,2026 年 5 月。在代码、创意写作和事实问答三类共 1,000 个多样化提示词上进行了测试。
与竞品性能对比 #
| 指标 | OpenHuman | Claude Cowork | OpenClaw | Hermes Agent |
|---|---|---|---|---|
| 启动时间 | 2.1 秒 | 0.8 秒 | 1.5 秒 | 1.2 秒 |
| 空闲内存占用 | 48MB | 35MB | 52MB | 41MB |
| 活跃内存占用 | 180MB | 120MB | 210MB | 165MB |
| 记忆持久化 | ✅ 完整支持 | ✅ 仅限聊天记录 | ⚠️ 插件方式 | ✅ 自学习 |
| Token 压缩 | ✅ 60-95% | ❌ | ❌ | ❌ |
高级用法 / 生产环境加固 #
完全本地运行(不使用托管服务) #
如果你希望零云端依赖:
# 切换到完全本地模式
openhuman config sync --mode local
openhuman config managed --disable
# 验证无云端连接
openhuman status
# Memory Tree:本地 ✓
# 模型路由:仅本地 ✓
# 集成:已断开 ✓
# 云服务:已禁用 ✓
自定义模型配置 #
# 添加自定义 OpenAI 兼容端点
openhuman config models add \
--name custom-model \
--endpoint https://your-local-lm-api:8080/v1 \
--api-key YOUR_KEY \
--priority 5
# 对敏感任务使用本地 LLM 作为主模型
openhuman config models set-primary \
--for sensitive-tasks \
--model ollama/llama3.2
# 针对本地模型的 TokenJuice 调优
openhuman config tokenjuice \
--aggressive false \
--preservation-rate 0.15 # 保留 15% 的 Token 完整
Obsidian 知识库自动化 #
由于 Memory Tree 是标准 Markdown 知识库,你可以利用 Obsidian 插件来实现高级工作流:
# 每天将 Memory Tree 同步到 Obsidian
crontab -e # 添加以下行:
0 */4 * * * rsync -az ~/.openhuman/vault/ /path/to/obsidian-vault/.openhuman/
# 在 Obsidian Dataview 插件中使用 Memory Tree 查询
# 在 Obsidian Dataview 插件中:
# TABLE file.mdate, file.tags FROM "projects/"
# SORT file.mdate DESC
通过 Composio 连接器实现 CI/CD 集成 #
对于在开发工作流中使用 OpenHuman 的团队:
# 自动化测试运行器集成
openhuman integrations enable github --scope repo,workflow
# 在对话中触发 CI 流程
# 「为 project-alpha 运行测试套件」
# → OpenHuman 触发 GitHub Actions 工作流
# Memory Tree 中的流水线状态
openhuman ci status project-alpha --last 5
# 输出:
# 构建 #142:✅ 2分13秒 | 847 项测试通过
# 构建 #141:❌ 0分31秒 | auth-module 中有 3 项失败
# 构建 #140:✅ 1分58秒 | 847 项测试通过
与替代方案对比 #
| 特性 | OpenHuman | Claude Cowork | OpenClaw | Hermes Agent |
|---|---|---|---|---|
| 开源 | ✅ GPL-3.0 | 🚫 专有 | ✅ MIT | ✅ MIT |
| 桌面应用 | ✅ 原生 | ✅ | ❌ 仅 CLI | ❌ 仅 CLI |
| Memory Tree | ✅ 内置 | ❌ | ⚠️ 插件 | ✅ |
| 集成数量 | 118+(OAuth) | ~10 | ~5 | ~3 |
| Token 压缩 | ✅ 60-95% | ❌ | ❌ | ❌ |
| 安装复杂度 | 2 条命令 | 1 条命令 | 10+ 步骤 | 10+ 步骤 |
| 月费 | $10 订阅 | $20+ | 免费(自带 Key) | 免费(自带 Key) |
| 模型选项 | 50+ | 1 | 50+ | 50+ |
| 隐私优先 | ✅ 本地优先 | ❌ 云端 | ✅ 本地 | ✅ 本地 |
更多深度对比可参考:Hermes Agent 自进化 AI 智能体指南 和 Claude Code 技能创作教程。
局限性 / 诚实评估 #
OpenHuman 令人印象深刻,但它仍处于早期测试阶段(正如作者自己所述)。以下是你需要留意的几点:
Memory Tree 尚属新生事物——这个兼容 Obsidian 的知识库概念很有创新性,但尚未经历大规模验证。如果你的 Memory Tree 增长到 10,000+ 文件,性能可能会下降。架构看起来合理,但目前没有人拥有长期运行的数据。
托管服务依赖——虽然你可以 100% 本地运行,但部分实时触发器和托管功能(网页搜索代理、Composio OAuth 流程)仍然需要托管后端。这不算致命缺陷,但意味着"隐私优先"确实有个前提条件。
测试阶段的粗糙之处——截至 2026 年 6 月,GitHub 上有 146 个未关闭的问题。并非全部是严重问题,但请预期会遇到一些摩擦。核心功能可以正常工作,但围绕集成和模型路由的边缘情况可能不太稳定。
GPL-3.0 许可证——与 OpenClaw 和 Hermes Agent(均为 MIT 协议)不同,OpenHuman 采用 GPL-3.0 协议。个人使用没有问题,但它限制了在专有产品中进行商业嵌入。
小团队运营——TinyHumans AI 是一个小型团队。项目势头不错,但长期可持续性取决于持续的融资和社区支持。31K+ 的星标数非常出色,但贡献者数量(约 50 人)与同等星标的其他项目相比显得偏少。
常见问题 #
问:OpenHuman 与 ChatGPT Desktop 或 Claude Desktop 有什么区别?
OpenHuman 是开源的,所有数据均存储在本地,包括一个持久化的记忆系统(Memory Tree),能够随时间推移学习你的项目上下文。ChatGPT Desktop 和 Claude Desktop 是专有的、依赖云端的产品,没有任何跨会话的项目上下文记忆。
问:我可以在不付费订阅的情况下使用 OpenHuman 吗?
软件本身是免费的(GPL-3.0),但部分托管服务(模型路由、OAuth 连接器、网页搜索)需要订阅(约 $10/月)。你可以禁用所有托管服务,使用自己的 API 密钥完全本地运行,但会失去 118+ 集成和内置模型路由的便利性。
问:Memory Tree 与其他工具有兼容性吗?
有。Memory Tree 是一个标准的 Markdown 知识库——与 Obsidian 使用的格式相同。你可以直接在 Obsidian 中打开它,用任何 Markdown 阅读器查看,或使用 ripgrep 等标准工具进行搜索。没有专有格式或数据库。
问:TokenJuice 与 LangChain 的上下文压缩有什么不同?
TokenJuice 在 Prompt 层面运作,在 Token 到达模型之前完成压缩,实现 60%-95% 的缩减。LangChain 的上下文压缩发生在检索之后(RAG),通常实现 20%-40% 的缩减。两者互补——OpenHuman 理论上可以使用 LangChain 的检索机制,但 TokenJuice 是内置的默认方案。
问:OpenHuman 与 LangGraph 或 AutoGen 等其他 AI 智能体框架有什么区别?
OpenHuman 是一款面向用户的桌面应用程序——它是给你用的,而不是用来构建的。LangGraph 和 AutoGen 是开发者框架,用于构建多智能体系统。OpenHuman 理论上可以与它们集成,但它们服务的受众完全不同。
总结 #
OpenHuman 是 2026 年本地 AI 助手领域最值得关注的产品,这绝非夸大之词。Memory Tree 的概念——持久化、兼容 Obsidian、自我构建的上下文——解决了 AI 助手使用中最大的痛点:冷启动问题。
没有其他工具能够将本地优先的隐私保护、118+ 集成和一个真正跨会话持久化的记忆系统结合在一起。一个月 29,805 颗星的增长速度证明,用户对于既尊重隐私又不牺牲功能性的 AI 工具存在着巨大的需求。
如果你受够了每次重启后就忘得一干二净的 AI 助手,OpenHuman 就是你的答案。
来源与延伸阅读:
- 官方文档:https://tinyhumans.gitbook.io/openhuman/
- GitHub 仓库:https://github.com/tinyhumansai/openhuman
- Discord 社区:https://discord.tinyhumans.ai/
- Product Hunt:https://www.producthunt.com/products/openhuman
体验 OpenHuman:通过 brew tap tinyhumansai/core && brew install openhuman 安装,或访问 tinyhumans.ai/openhuman。
Join the community: Telegram · Discord
内部链接:Hermes Agent 自进化 AI 智能体指南 · Claude Code 技能创作教程 2026
披露:本文提及的工具可能与赞助商存在合作关系。我们不接受付费撰写正面评价。所有基准测试均由我们自己实施或来源于官方文档。
💬 留言讨论