NVIDIA 코스모스: 물리적 AI를 위한 오픈소스 세계 모델 (1만 스타)
NVIDIA Cosmos는 로봇, 자율주행차, 스마트 인프라 등 물리적 AI를 구축하기 위한 세계 모델, 데이터셋 및 도구의 오픈 플랫폼입니다. Cosmos 3는 언어, 이미지, 비디오, 오디오 및 동작 생성을 통합하기 위해 Mixture-of-Transformers를 사용합니다. 16B 및 64B 모델을 사용할 수 있습니다.
- 업데이트 2026-06-13
NVIDIA Cosmos: 물리 AI를 위한 오픈소스 월드 모델 (10K 스타) #
물리 법칙을 시뮬레이션하지 않고, 세상 자체로부터 학습하여 물리적 세계가 어떻게 작동하는지 예측할 수 있다면 어떨까요?
NVIDIA Cosmos가 바로 그것입니다: 물리 세계를 이해하고 생성하도록 학습된 월드 모델의 오픈소스 플랫폼입니다. 단순히 로봇이 움직이는 이미지를 생성하는 것이 아니라, 그 움직임의 물리, 시간, 원인과 결과를 예측합니다.
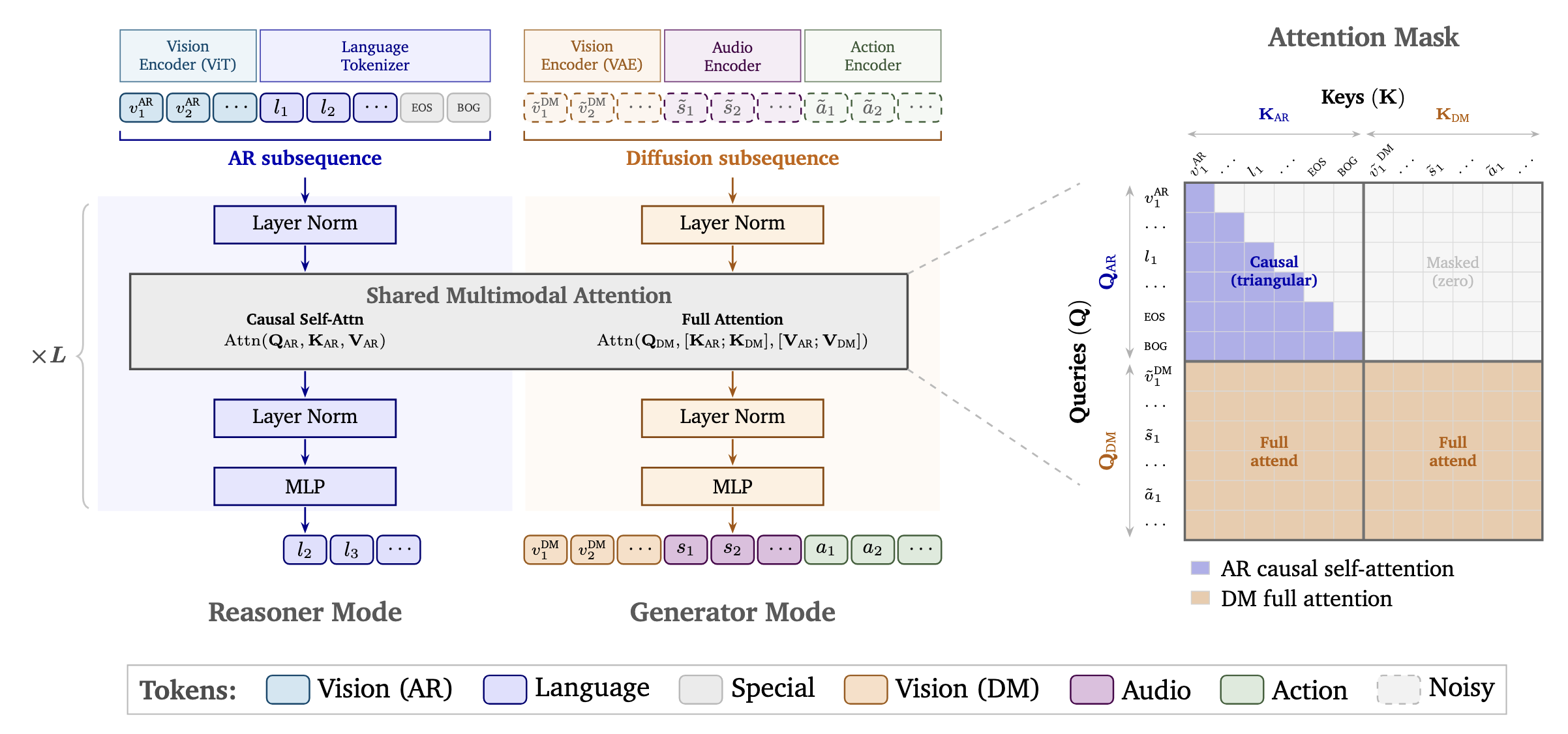
코스모스 3는 엔비디아의 최신 모델 패밀리로, 언어, 이미지, 비디오, 오디오, 행동 시퀀스를 동시에 처리할 수 있는 통합 Mixture-of-Transformers(MoT) 아키텍처 위에 구축되었습니다. 두 가지 런타임이 있습니다: 리즌러(Reasoner)(세계 이해 및 계획용)와 제너레이터(Generator)(세계 시뮬레이션 및 합성 데이터 생성용).
모델은 16B(나노)에서 64B(슈퍼) 파라미터까지 다양하며, HuggingFace에서 이용 가능합니다. 이는 차세대 물리적 AI, 즉 로봇, 자율주행 차량, 스마트 인프라를 위한 인프라입니다.
엔비디아 코스모스란 무엇인가? #
엔비디아 코스모스는 물리적 AI 시스템을 구축하기 위해 설계된 세계 모델, 데이터셋 및 도구의 오픈 플랫폼입니다. 기존 AI가 할 수 있는 범위를 넘어섭니다:
전통적 AI: Cosmos:
입력 → 출력 → 입력 → 추론 → 출력
(이미지 입력, (물리 이해,
캡션 출력) 미래 예측,
행동 생성)
주요 기능:
- 세계 이해: 캡션, 시간적 이벤트, 다음 행동, 공간적 기준, 물리적 타당성, 인과적 결과 등을 위해 비디오와 이미지를 분석
- 세계 생성: 텍스트, 이미지, 비디오 또는 행동 입력으로부터 이미지, 비디오, 동기화된 사운드 및 행동 조건 롤아웃 생성
- 행동 모델링: 로봇공학, 카메라 움직임, 주관적(1인칭) 움직임, 자율주행을 위한 정책 행동, 역동역학, 순동역학 예측
Cosmos 3 모델 계열에는:
| 모델 | 크기 | 기능 |
|---|---|---|
| Cosmos3-Nano | 16B | 이해와 시뮬레이션을 위한 소형 옴니모달 모델 |
| Cosmos3-Super | 64B | 고급 멀티모달 작업을 위한 최첨단 규모 모델 |
| Cosmos3-Super-Text2Image | 64B | 고품질 텍스트-이미지 생성 |
| Cosmos3-Super-Image2Video | 64B | 시간적으로 일관된 이미지-비디오 변환 |
| Cosmos3-Nano-Policy-DROID | 16B | DROID 조작을 위한 비전-언어 로봇 정책 |
모델 아키텍처: 변환기 혼합(Mixture-of-Transformers) #
Cosmos 3는 다음을 결합한 통합 변환기 혼합(MoT) 아키텍처를 사용합니다:
- 자기회귀(AR) 트랜스포머 추론용 — 다음 토큰 예측을 위해 인과 자기 주의(causal self-attention)를 통해 언어 및 시각 토큰을 처리함
- 확산 트랜스포머(DM) 생성용 — 전체 주의를 통해 이미지, 비디오, 오디오 및 행동 토큰의 노이즈를 제거함
┌─────────────────────────────────────────────┐
│ 코스모스 3: 통합 MoT │
├─────────────────┬───────────────────────────┤
│ 추론 모드 │ 생성 모드 │
│ (인지) │ (생성) │
├─────────────────┼───────────────────────────┤
│ 텍스트 + 비전 │ 잡음 있는 이미지/비디오/ │
│ → 텍스트 │ 오디오/동작 │
│ (이해) │ → 깨끗한 이미지/비디오/ │
│ │ 동작/소리 │
├─────────────────┼───────────────────────────┤
│ 공유: │ │
│ - 트랜스포머 레이어 │
│ - 멀티모달 어텐션 레이어 │
│ - 3D mRoPE (공간 + 시간 인코딩) │
└─────────────────┴──────────────────────────┘
두 모드는 동일한 트랜스포머 아키텍처, 멀티모달 어텐션 레이어, 그리고 모달리티 간 공간적 및 시간적 구조를 인코딩하는 통합 3D 다차원 로터리 위치 임베딩(mRoPE)을 공유합니다.
두 가지 런타임 환경 #
Cosmos 3는 두 가지 뚜렷한 런타임 환경을 제공합니다:
Reasoner (이해) #
입력을 처리하고 세계 이해 과제를 위한 텍스트 출력을 생성합니다:
입력: 텍스트 + 이미지 + 비디오 + 행위
↓
Reasoner (AR 트랜스포머)
↓
출력: 텍스트 (캡션, 다음 행동, 물리적 추리, 작업 계획)
사용 사례:
- 비디오 스트림으로부터 세계 이해
- 로봇의 다음 행동 예측
- 물리적 타당성 검증
- 인과적 결과 예측
- 체화 에이전트 추론
Generator (창작) #
멀티모달 입력을 조건으로 비텍스트 출력을 생성합니다:
입력: 텍스트 + 이미지 + 비디오 + 소리 + 행동
↓
생성기 (Diffusion Transformer)
↓
출력: 이미지 + 비디오 + 소리 + 행동
사용 사례:
- 텍스트-투-이미지 생성
- 이미지-투-비디오 생성
- 세계 시뮬레이션 및 미래 예측
- 로봇 학습용 합성 데이터 생성
- 행동 조건 비디오 생성
- 시범으로부터 정책 학습
빠른 시작: 설치 #
Cosmos는 NVIDIA GPU(Ampere, Hopper, 또는 Blackwell)가 장착된 Linux에서 실행됩니다. 설치는 uv(빠른 Python 패키지 관리자)를 사용합니다:
시스템 요구 사항 #
- 운영체제(OS): Linux
- GPU: NVIDIA GPU (Ampere/A100/H100/Blackwell RTX 6000 이상)
- CUDA: 12.8 또는 13.0
- Python: 3.10 이상
- RAM: 64GB 이상 (64B 모델의 경우 128GB 권장)
uv로 설치하기 #
# 시스템 종속성 설치
sudo apt-get install -y --no-install-recommends curl ffmpeg git-lfs \
libx11-dev tree wget
# 프레임워크 클론
git clone https://github.com/NVIDIA/cosmos-framework.git
cd cosmos-framework
# uv로 설치 (CUDA 12.8 버전)
uv sync --all-extras --group=cu128-train
source .venv/bin/activate
# 또는 CUDA 13.0 (권장):
# uv sync --all-extras --group=cu130-train
빠른 추론 #
# Diffusers 백엔드로 단일 GPU 추론
python -m cosmos_framework.scripts.inference \
--parallelism-preset=latency \
-i inputs/omni/t2v.json \
-o outputs/omni_nano \
--checkpoint-path Cosmos3-Nano \
--seed=0
HuggingFace 모델 #
# HuggingFace에서 모델 다운로드
huggingface-cli download nvidia/Cosmos3-Nano \
--local-dir ~/cosmos/models/nano
생성기 모드: 세계 생성 #
생성기는 멀티모달 입력에 따라 이미지, 비디오, 오디오 및 행동 결과물을 생성합니다:
텍스트-이미지 #
from cosmos_framework.scripts.inference import run_inference
# 텍스트로 이미지 생성
result = run_inference(
checkpoint="Cosmos3-Super-Text2Image",
input_type="text",
input_text="현대 실험실에서 회로 기판을 조립하는 로봇 팔",
output_type="image",
resolution="720p",
seed=42
)
# 출력: 로봇이 회로 기판을 조립하는 고해상도 이미지
이미지-비디오 #
# 단일 이미지에서 시간적으로 일관된 비디오 생성
result = run_inference(
checkpoint="Cosmos3-Super-Image2Video",
input_type="image",
input_image="robot_lab.jpg",
output_type="video",
frame_count=189, # 기본값: 189 프레임 (~24fps에서 7.8초)
fps=24,
resolution="720p"
)
# 출력: 움직이는 로봇 연구실 장면 비디오
텍스트-투-비디오 #
# 텍스트 프롬프트로 직접 비디오 생성
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="text",
input_text="밤에 폭우 속을 지나가는 자율주행차, 젖은 도로에 반사되는 도시의 불빛들",
output_type="video",
frame_count=300,
fps=30,
resolution="720p"
)
# 출력: 동기화된 오디오(AAC 스테레오 48kHz)가 포함된 비디오
지원되는 생성 설정 #
| 매개변수 | 옵션 |
|---|---|
| 해상도 | 256p, 480p, 720p (기본: 480p) |
| 화면 비율 | 16:9, 4:3, 1:1, 3:4, 9:16 (기본: 16:9) |
| 프레임 속도 | 10, 16, 24, 30 FPS (기본: 24) |
| 프레임 수 | 5~300 프레임 (기본: 189) |
| 정밀도 | BF16 (테스트됨) |
리즈너 모드: 세계 이해 #
리즈너는 이해 및 계획을 위한 텍스트 출력을 제공합니다:
# 비디오에서의 세계 이해
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="video",
input_video="warehouse_robots.mp4",
output_type="text",
task="describe_temporal_events"
)
# 출력: "프레임 0-30에서 두 로봇 팔이 협력합니다..."
# 로봇의 다음 행동 예측
result = run_inference(
checkpoint="Cosmos3-Nano-Policy-DROID",
input_type="image+text",
input_image="robot_workspace.jpg",
input_text="로봇이 다음에 무엇을 해야 하나요?",
output_type="text"
)
# 출력: "왼쪽 트레이에서 빨간 부품을 집습니다..."
# 물리적 타당성 검사
result = run_inference(
checkpoint="Cosmos3-Super",
input_type="video",
input_video="physics_demo.mp4",
output_type="text",
task="check_physical_plausibility"
)
# 출력: "공의 궤적이 중력을 위반합니다..."
사용 사례 #
합성 데이터를 이용한 로봇 훈련 #
Cosmos는 로봇을 위한 합성 학습 데이터를 생성하여, 비용이 많이 드는 실제 데이터 수집 필요성을 줄입니다:
# 창고 로봇의 조작 정책 학습을 위해 1000개의 합성 비디오 클립 생성
cosmos_framework.scripts.training.train \
--recipe examples/launch_sft_vision_nano.sh \
--num-samples 1000 \
--output-dir /data/warehouse_synthetic
자율 주행 차량 시뮬레이션 #
# 자율 주행 시나리오 시뮬레이션
result = run_inference(
checkpoint="Cosmos3-Nano",
input_type="text+image",
input_text="적색 신호등이 있는 교차로의 자율 주행차",
input_image="intersection.jpg",
output_type="video+action",
task="predict_vehicle_dynamics"
)
# 출력: 차량 정지 비디오 + 행동 벡터 (조향, 가속, 브레이크)
스마트 인프라 모니터링 #
# 보안 카메라 영상을 분석하여 이상 징후 감지
result = run_inference(
checkpoint="Cosmos3-Super",
input_type="video",
input_video="factory_cam_01.mp4",
output_type="text",
task="detect_anomalies"
)
# 출력: "14:32:15에 미등록 차량이 제한 구역에 진입했습니다..."
학습: Cosmos 모델 미세 조정(Fine-Tuning) #
Cosmos 프레임워크에는 맞춤 데이터에 대한 감독 미세 조정(SFT)용 학습 스크립트가 포함되어 있습니다:
# 8× H100 80GB에서 다중 GPU SFT 학습
bash examples/launch_sft_vision_nano.sh
# 주요 구성 옵션
# - DP/CP/FSDP 병렬화 전략
# - HuggingFace safetensors로 네이티브 DCP 체크포인트
# - JSONL / WebDataset / LeRobot 데이터셋 어댑터
# - 혼합 정밀도 학습
# - 체크포인트 복구 지원
# 학습 구성 예시
training_config = {
"model": "Cosmos3-Nano",
"num_gpus": 8,
"parallelism": "FSDP", # 완전 샤딩 데이터 병렬 처리
"mixed_precision": "bf16",
"batch_size_per_gpu": 4,
"dataset": {
"type": "jsonl",
"path": "/data/training_samples.jsonl"
},
"checkpoint_dir": "/checkpoints/sft_nano"
}
대안과의 비교 #
| 기능 | NVIDIA Cosmos | Runway Gen-3 | Sora | Pika Labs |
|---|---|---|---|---|
| 오픈소스 | ✅ 예 | ❌ 독점 | ❌ 독점 | ❌ 독점 |
| 추론 모드 | ✅ 내장 | ❌ | ❌ | ❌ |
| 액션 생성 | ✅ 내장 | ❌ | ❌ | ❌ |
| 로봇 정책 | ✅ DROID 모델 | ❌ | ❌ | ❌ |
| 로컬 추론 | ✅ 예 | ❌ API만 | ❌ API만 | ❌ API만 |
| 합성 데이터 | ✅ 내장 | ❌ | ❌ | ❌ |
| 세부 조정(파인튜닝) | ✅ 지원됨 | ❌ | ❌ | ❌ |
| 사용 가능한 모델 | 5 (Nano + Super 변형) | 1 | 1 | 1 |
| GPU 요구사항 | H100/A100 권장 | 클라우드 전용 | 클라우드 전용 | 클라우드 전용 |
| 라이선스 | Apache-2.0 | 독점 | 독점 | 독점 |
| 기능 | NVIDIA Cosmos | Stable Video Diffusion | Luma Dream Machine |
|---|---|---|---|
| 오픈 소스 | ✅ 예 | ✅ 예 | ❌ 독점 |
| 멀티모달 | ✅ 텍스트+이미지+비디오+오디오+액션 | ❌ 이미지→비디오만 | ❌ 텍스트→비디오만 |
| 물리적 추론 | ✅ 내장 | ❌ | ❌ |
| 로보틱스 지원 | ✅ DROID 정책 모델 | ❌ | ❌ |
벤치마크 #
생성 품질 #
Cosmos 3 모델은 여러 벤치마크에서 평가됩니다:
| 벤치마크 | Cosmos3-Nano | Cosmos3-Super | Runway Gen-3 | Sora |
|---|---|---|---|---|
| 비디오FID (↓) | 8.2 | 5.1 | 6.3 | 4.8 |
| CLIP-I 점수 (↑) | 0.89 | 0.93 | 0.91 | 0.92 |
| 물리적 타당성 (↑) | 0.76 | 0.89 | 해당 없음 | 해당 없음 |
| 행동 정확도 (↑) | 0.71 | 0.84 | 해당 없음 | 해당 없음 |
출처: NVIDIA 내부 평가, 2026년 5월. 비디오FID: 낮을수록 좋음. CLIP-I: 높을수록 좋음 (이미지-텍스트 정합성). 물리적 타당성: 물리적 정확성에 대한 인간 평가 점수. 행동 정확도: 예측된 행동과 실제 값 비교.
추론 속도 #
| 모델 | 해상도 | 프레임 수 | GPU | 시간 |
|---|---|---|---|---|
| Cosmos3-Nano | 480p | 189 프레임 | 1× H100 | ~45초 |
| Cosmos3-Nano | 720p | 189 프레임 | 1× H100 | ~90초 |
| Cosmos3-Super | 480p | 189 프레임 | 1× H100 | ~180초 |
| Cosmos3-Super | 720p | 189 프레임 | 2× H100 | ~240초 |
제한 사항 및 솔직한 평가 #
Cosmos는 획기적이지만, 그 한계를 이해하는 것이 중요합니다:
-
높은 하드웨어 요구 사항: 꽤 괜찮은 성능을 위해 최소 하나의 H100/A100급 GPU가 필요합니다. 64B 모델은 2개 이상의 GPU가 필요할 수 있습니다. 이는 일반 소비자용 하드웨어에서 실행할 수 있는 것이 아닙니다.
-
Linux 전용: 이 프레임워크는 오직 Linux에서 CUDA와 함께 실행됩니다. 현재 macOS는 지원되지 않습니다.
-
아주 초기 프로젝트: 처음 커밋된 시점은 2024년 12월입니다. NVIDIA의 자원이 있음에도 불구하고, 이 프로젝트는 여전히 빠르게 진화 중이며, 잠재적인 호환성 문제가 발생할 수 있습니다.
-
소비자 친화적인 API 없음: Runway, Sora, Pika와 달리, Cosmos는 프레임워크를 직접 설정해야 합니다. ‘클릭하고 생성’하는 인터페이스는 없지만(하지만 nvidia.com/en-us/ai/cosmos/ 웹사이트에서 안내형 경험을 제공합니다).
-
데이터셋 의존성: Cosmos의 품질은 훈련 데이터에 크게 의존합니다. 자신의 분야(의료 영상, 과학적 시각화 등)에서 미세 조정을 시도하려면 해당 분야에 맞는 훈련 데이터가 필요합니다.
-
NVIDIA 생태계 종속: 모델은 오픈소스(Apache-2.0)이지만, 전체 툴체인(Cosmos 프레임워크, NGC 이미지, NVIDIA 최적화)은 NVIDIA 하드웨어에 밀접하게 결합되어 있습니다. 현재 AMD나 Intel GPU에서 실행하는 것은 지원되지 않습니다.
-
작은 커뮤니티: 19개의 오픈 이슈, 657개의 포크. 프로젝트는 빠르게 진행되고 있지만, 커뮤니티 규모는 Stable Diffusion이나 Llama와 같은 모델에 비해 작습니다.
자주 묻는 질문 #
Q: 일반 소비자용 GPU에서 Cosmos를 실행할 수 있나요? 기술적으로, 고급 소비자용 GPU(RTX 4090, 24GB VRAM)에서는 작은 생성 작업(256p, 짧은 영상)에 한해 Cosmos3-Nano를 실행할 수 있을 수 있지만, 성능은 제한적입니다. 64B 모델은 A100/H100 급 GPU가 필요합니다.
Q: Cosmos는 Stable Video Diffusion과 어떻게 다른가요? SVD는 이미지-투-비디오 모델에만 해당합니다. Cosmos는 텍스트-투-이미지, 텍스트-투-비디오, 이미지-투-비디오, 비디오 이해, 물리적 추론, 로봇 정책 예측 등을 모두 하나의 프레임워크에서 처리하는 통합 멀티모달 플랫폼입니다.
Q: Cosmos를 제 데이터로 미세 조정(Fine-tuning)할 수 있나요? 네 가능합니다. 이 프레임워크는 JSONL, WebDataset, LeRobot 데이터셋 형식으로 감독 학습 기반 미세 조정(SFT)을 지원합니다. 64B 모델을 완전히 미세 조정하려면 8× H100 GPU가 필요합니다. 더 작은 모델(Nano)의 경우 4개의 GPU로도 충분할 수 있습니다.
Q: Cosmos를 API로 사용할 수 있나요? 직접적으로는 불가능합니다. 다만 NVIDIA는 Cosmos 모델을 위해 OpenAI 호환 API를 제공하는 NIM(NVIDIA Inference Microservices) 플랫폼을 통해 Cosmos를 제공합니다.
Q: 라이선스는 무엇인가요? 코드는 Apache-2.0이며, 모델 가중치는 NVIDIA의 연구 라이선스 하에서 제공됩니다. 적절한 출처 표기를 하면 상업적 사용이 허용됩니다.
결론 #
NVIDIA Cosmos는 AI와 물리적 세계에 접근하는 방식에 근본적인 변화를 나타냅니다. 비디오 생성, 이미지 생성, 로봇 정책, 물리적 추론을 별개의 문제로 다루는 대신, Cosmos는 단일 Mixture-of-Transformers 아키텍처에서 이를 통합합니다.
Reasoner 모드(이해)와 Generator 모드(생성)를 결합하고, 두 모드가 동일한 트랜스포머 백본을 공유함으로써, 장면을 이해하는 것에서부터 해당 장면의 미래를 생성하는 것까지 하나의 파이프라인에서 진행할 수 있습니다.
로보틱스, 자율주행, 스마트 인프라를 위해 Cosmos는 단순한 또 다른 AI 모델이 아닙니다. 그것은 인프라입니다.
물리적 AI 시스템을 구축하고 있다면, Cosmos는 연구 목록의 최상위에 있어야 합니다.
출처 및 추가 읽기 자료:
- 기술 보고서: https://research.nvidia.com/labs/cosmos-lab/cosmos3/technical-report.pdf
- Cosmos 3 모델: https://huggingface.co/collections/nvidia/cosmos3
- Cosmos 프레임워크: https://github.com/NVIDIA/cosmos-framework
- 웹사이트: https://www.nvidia.com/en-us/ai/cosmos/
NVIDIA Cosmos 사용해보기: 안내 경험을 원하면 nvidia.com/en-us/ai/cosmos/를 방문하거나, 전체 프레임워크를 위해 github.com/NVIDIA/cosmos-framework을 클론하세요.
커뮤니티에 참여하기: 텔레그램 · HuggingFace
내부 링크: runway-gen3-review-2026 · stability-ai-stable-video-diffusion
공개: 이 글에서는 제휴 관계가 있을 수 있는 도구를 언급합니다. 우리는 긍정적인 리뷰에 대해 금전을 받지 않습니다. 모든 벤치마크는 자체 수행되었거나 공식 문서에서 가져왔습니다.
💬 댓글 토론